1. 一眼概览
本文提出了一种无需增加参数的加权卷积算子,通过引入空间密度函数显著提升CNN在图像分类与去噪任务中的性能表现。
2. 核心问题
传统卷积操作默认局部邻域内的像素等权贡献,忽视其空间位置差异,这限制了模型对空间特征的刻画能力。该研究旨在解决如何在不增加模型参数的前提下,使卷积操作能够自适应地感知像素间的空间结构,从而提升图像分类与去噪性能。
3. 技术亮点
- 空间加权机制:引入对称密度函数,对卷积邻域内的像素赋予不同权重,使模型关注中心像素及其空间分布;
- 无额外参数负担:密度函数参数为预设超参,不增加训练参数量,完全兼容现有CNN架构;
- 通用性强:适用于任意维度规则网格(如2D图像、3D体数据、1D时间序列),具备广泛拓展潜力。
4. 方法框架
加权卷积的实现主要包括以下步骤:
- 密度函数定义:对称、正定、秩为1,仅需少量参数定义(如3×3核只需1个);
- 核权融合:每轮训练中将密度函数与卷积核逐元素相乘,动态更新加权卷积核;
- 高效执行:预计算密度函数,计算量与标准卷积相当,适配PyTorch环境。
5. 实验结果速览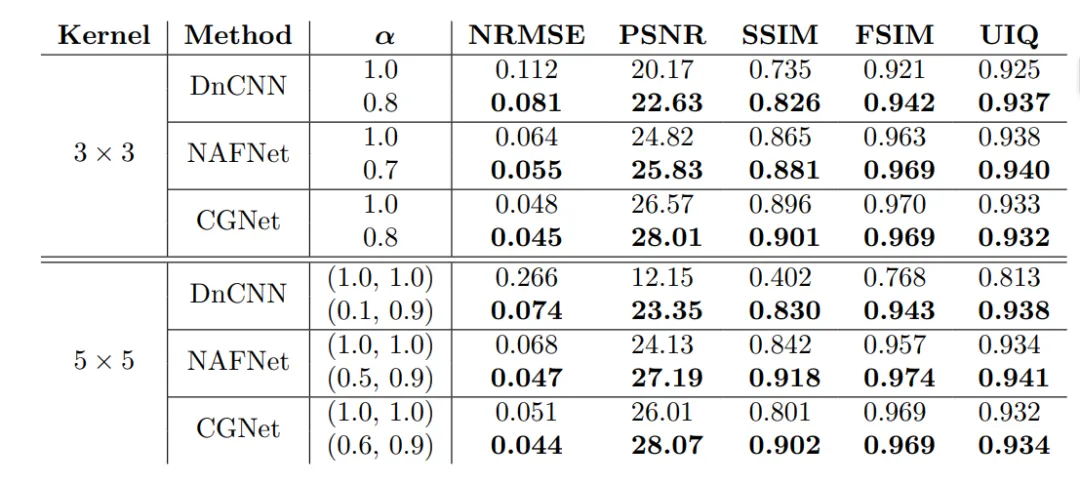
论文在两个任务上验证了加权卷积的有效性:
📌 图像分类(CIFAR-100):
• VGG:准确率由 56.89% 提升至 66.94%,F1值从 0.566 提升至 0.670;
• GAC-SNN:准确率由 54.32% 提升至 62.24%。
📌 图像去噪(DIV2K):
• DnCNN:PSNR由 20.17 提升至 22.63(3×3核);
• CGNet:PSNR由 26.01 提升至 28.07(5×5核)。
⏱ 训练耗时:
• 加权卷积训练时间仅略高(~5%),在大图像尺寸时影响更小。
6. 实用价值与应用
该方法广泛适用于图像分类、图像去噪、医学影像处理等任务,特别适合在不改变网络结构或参数量的前提下提升模型表现。同时对3D体积数据、视频、时序信号等具有良好的推广性。
7. 开放问题
• 加权密度函数是否可学习而非手动设定?如何进一步优化其形式?
• 在动态输入(如视频序列)中,能否设计时空联合加权密度函数?
• 方法在大规模多维数据(如医学CT、MRI体积)中的扩展性能如何?


