IBM 发布了 Granite4.0Tiny Preview,这是即将推出的 Granite4.0系列语言模型中最小的一款的预览版本。该模型不仅具备高效的计算能力,还为开源社区提供了一个值得关注的实验平台。
高效的性能与极小的内存需求
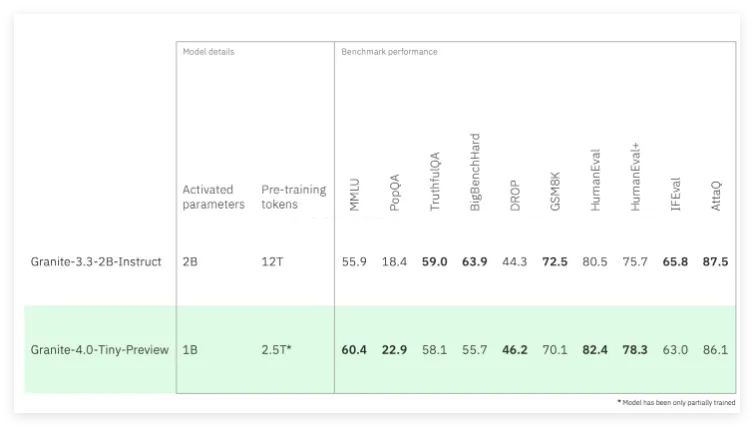
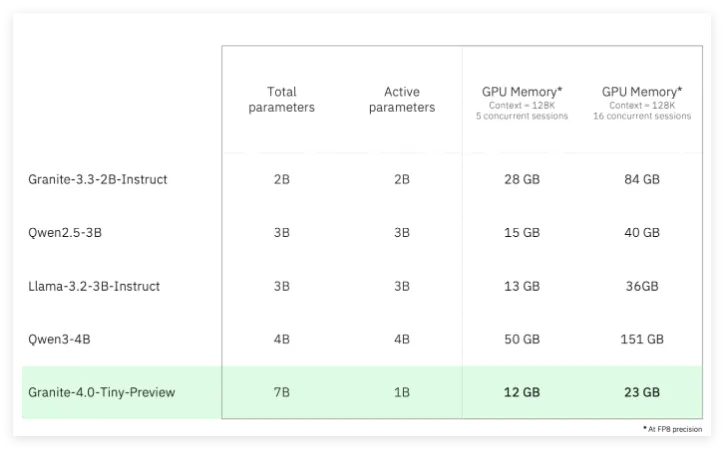
Granite4.0Tiny 在 FP8精度下,能够在消费级硬件上运行多个长上下文(128K)的并发任务,适用于市面上价格低于350美元的 GPU。尽管该模型目前仅经过部分训练,处理过2.5万亿个训练标记,但其性能已接近 IBM Granite3.32B Instruct,且内存需求降低约72%。随着后续训练的进行,预计 Granite4.0Tiny 的性能将达到与 Granite3.38B Instruct 相当的水平。
全新的混合架构设计
Granite4.0系列语言模型采用了全新的混合 Mamba-2/Transformer 架构,结合了 Mamba 的速度与效率以及 Transformer 的自注意力精度。Granite4.0Tiny Preview 是一个细粒度的混合专家模型,具有70亿个总参数,但在推理时仅激活10亿个参数。这一创新的架构设计源自 IBM 研究与 Mamba 原始创造者的合作,提升了模型的整体性能。
无约束的上下文长度
Granite4.0的一个亮点是其理论上能够处理无限长的序列。这一能力源自其不使用位置编码(NoPE)的设计,有效避免了传统模型在处理长上下文时的性能限制。测试表明,该模型在处理128K 个标记时表现良好,未来还将验证其在更长上下文上的性能表现。
适合多种应用场景
Granite4.0Tiny 的内存效率和性能,使其成为多个企业应用的理想选择。IBM 计划在未来几个月内,进一步完善模型,并期待在即将召开的 IBM Think2025大会上分享更多信息。
IBM 的 Granite4.0Tiny Preview 不仅是对高效能语言模型的一次大胆尝试,更是对开源社区的一次有力支持。随着后续版本的推出,该模型有望为开发者和企业用户带来更多可能性。
官方博客:https://www.ibm.com/new/announcements/ibm-granite-4-0-tiny-preview-sneak-peek