MoE

xLLM社区12月6日首揭开源推理引擎:支持MoE、T2I、T2V全场景,联合Mooncake缓存方案实现延迟低于20ms
成立仅三个月的xLLM社区宣布将于 12 月 6 日举办首届线下Meetup,主题“共建开源AI Infra生态”。 活动将展示自研推理引擎xLLM-Core,公开对比数据:在同级GPU上,MoE、Text-to-Image、Text-to-Video三类任务的P99 延迟均低于20ms,较vLLM平均下降42%,吞吐量提升2. 1 倍。

科大讯飞推出全国产算力星火 X1.5,AI 技术再升级
在近日举行的科大讯飞全球开发者节上,科大讯飞正式发布了全新深度推理大模型 —— 星火 X1.5。 这个基于全国产算力平台的模型不仅在技术上取得了重大突破,还宣称在效率上达到了国际竞争对手的93% 以上,让国内开发者在全球市场上更加从容不迫。 星火 X1.5模型的亮点在于其在 MoE(Mixture of Experts)模型的全链路训练效率上实现了突破。

为MoE解绑:全新「专家即服务」推理架构发布,超细粒度扩展锐减37.5%成本
本文第一作者刘子铭为新加坡国立大学三年级博士生,本科毕业于北京大学,研究方向为机器学习系统中的并行推理与训练效率优化。 通信作者为上海创智学院冯思远老师和新加坡国立大学尤洋老师。 共同作者来自于上海奇绩智峰智能科技有限公司,北京基流科技有限公司等。

小巧却强大的推理引擎!Ring-mini-2.0 震撼发布,性能超越10B模型
今天,我们正式推出了 Ring-mini-2.0,这是一款基于 Ling-mini-2.0架构深度优化的高性能推理型 MoE 模型。 Ring-mini-2.0的总参数量达到16B,但在实际运行中仅需激活1.4B 参数,便能实现相当于10B 级别以下的密集模型的推理能力。 这款模型在逻辑推理、编程和数学任务中表现尤为出色,支持128K 的长上下文,使得其在各种应用场景中都能展现出强大的能力。

MoE那么大,几段代码就能稳稳推理 | 开源
混合专家网络模型架构(MoE)已经成为当前大模型的一个主流架构选择,以最近开源的盘古Pro MoE为例,其基于MoGE架构构建的混合专家架构,总参数量达720亿,激活参数量为160亿,专门针对昇腾硬件优化,在性能与效率上表现突出。 盘古还实现了在推理时做到又快又稳。 在技术特性上,盘古模型引入 “快思考” 和 “慢思考” 双系统,可根据问题复杂度自动切换响应模式,并在推理性能上实现突破——在昇腾800I A2上单卡推理吞吐性能达1148 tokens/s,经投机加速技术可提升至1528 tokens/s,显著优于同等规模稠密模型。

腾讯开源 Hunyuan-A13B:小尺寸,大智慧的 AI 模型
Hunyuan-A13B 是一个由腾讯最新开源的大语言模型,它以创新的设计理念,在相对较小的活跃参数规模下,实现了强大的性能表现,特别适用于资源受限的环境。 这款模型采用了细粒度 MoE(Mixture-of-Experts)架构,拥有130亿活跃参数,但总参数量高达800亿。 这种设计让它在保持高效和可扩展性的同时,能够提供前沿的推理能力和通用应用支持。

小红书发布首个开源大模型dots.llm1:11.2 万亿非合成数据助力中文性能提升
小红书近日宣布开源其首个大规模模型 ——dots.llm1,该模型具有1420亿个参数,是一种专家混合模型(MoE)。 其设计的一个显著特点是,在推理过程中仅激活140亿参数,这种结构不仅保持了高性能,还大幅降低了训练和推理的成本。 dots.llm1使用了11.2万亿个非合成的高质量训练数据,这在当前开源大模型中显得非常罕见,表明小红书在语言处理方面的强大资源。
Qwen3正式发布,优化编码与代理能力,强化MCP支持引领AI新潮流
阿里云Qwen团队宣布Qwen3系列模型正式发布,以卓越的编码能力、增强的代理功能和对Model Context Protocol(MCP)的深度支持,掀起AI社区热潮。 据AIbase了解,Qwen3涵盖从0.6B到235B-A22B的多种模型规模,优化了数学推理、代码生成和多模态任务,性能直追GPT-4o与Gemini-2.5-Pro。 社交平台上的讨论显示,Qwen3的MCP集成与开源策略备受期待,相关细节已通过Hugging Face与Qwen官网公开。

Qwen3正式确认本周发布,阿里云AI新篇章即将开启
阿里云Qwen团队通过社交平台正式确认,Qwen3系列模型将于本周内发布,标志着其旗舰大语言模型(LLM)与多模态能力的又一次重大升级。 据AIbase了解,Qwen3将推出包括0.6B、4B、8B、30B-A3B在内的多种模型规模,支持高达256K的上下文长度,涵盖推理与非推理任务。 社交平台上的热烈讨论凸显了其全球影响力,相关细节已通过Hugging Face与Qwen官网逐步公开。

Moonshot AI开源轻量级MoE多模态模型Kimi-VL,2.8B参数媲美SOTA模型!
最近有点忙,没来得及更新,但一直保持着对前沿技术的紧密关注,不得不感叹当今技术日新月异。 多模态推理模型进展,现有的开源大型视觉语言模型在可扩展性、计算效率和高级推理能力方面显著落后于纯文本语言模型。 OpenAI的GPT-4o和Google的Gemini等模型能够无缝感知和解释视觉输入,但不开源,DeepSeek-R1等模型虽然采用了MoE架构,但在长上下文推理和多模态任务上仍有不足。

DeepSeek-R2曝5月前上线!第三弹DeepGEMM 300行代码暴击专家优化内核
第三天,DeepSeek发布了DeepGEMM。 这是一个支持稠密和MoE模型的FP8 GEMM(通用矩阵乘法)计算库,可为V3/R1的训练和推理提供强大支持。 仅用300行代码,DeepGEMM开源库就能超越专家精心调优的矩阵计算内核,为AI训练和推理带来史诗级的性能提升!
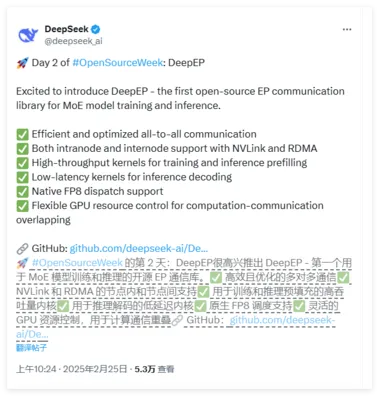
DeepSeek开源周第二日:首个面向MoE模型的开源EP通信库
Deepseek 公布了开源周第二天的产品,首个面向MoE模型的开源EP通信库,支持实现了混合专家模型训练推理的全栈优化。 DeepEP 是一个专为混合专家(MoE)和专家并行(EP)设计的高效通信库。 它致力于提供高吞吐量和低延迟的多对多 GPU 内核,通常被称为 MoE 调度和组合。

DeepSeek671B提到的MOE是什么?图解MOE(混合专家模型)
本文仅做记录,图挺形象的。 原文:,你可能会在标题中看到“MoE”这个词。 那么,这个“MoE”到底代表什么?

超详细,DeepSeep 接入PyCharm实现AI编程!(支持本地部署DeepSeek及官方DeepSeek接入),建议收藏!
在当今数字化时代,AI编程助手已成为提升开发效率的利器。 DeepSeek作为一款强大的AI模型,凭借其出色的性能和开源免费的优势,成为许多开发者的首选。 今天,就让我们一起探索如何将DeepSeek接入PyCharm,实现高效、智能的AI编程。

字节跳动豆包UltraMem架构将大模型推理成本降低83%
字节跳动豆包大模型团队今日宣布,成功研发出全新稀疏模型架构UltraMem,该架构有效解决了MoE(混合专家)模型推理时的高额访存问题,推理速度较MoE提升2-6倍,推理成本最高可降低83%。 这一突破性进展为大模型的高效推理开辟了新路径。 UltraMem架构在保证模型效果的前提下,成功解决了MoE架构推理时的访存瓶颈。

豆包提出全新稀疏模型架构 UltraMem,推理成本较 MoE 最高可降 83%
实验结果表明,训练规模达 2000 万 value 的 UltraMem 模型,在同等计算资源下,可同时实现业界领先的推理速度和模型性能,为构建数十亿规模 value 或 expert 开辟了新路径。

别TM浪费算力了,这样才能最大限度发挥deepseek的潜能 - MOE
最近几周自学deepseek原理 应用 实践,一些成果,和大家分享:小众关心的,deepseek核心技术原理;大众关心的,提示词要怎么写;今天和大家聊聊,deepseek的核心机制之一的混合专家MOE。 什么是混合专家MOE? 混合专家,Miture of Experts,该模型思路不再追求大而全,转而追求多而专精。

全球首次:时序大模型突破十亿参数,华人团队 Time-MoE 预训练数据达 3000 亿个时间点
Time-MoE 采用了创新的混合专家架构,能以较低的计算成本实现高精度预测。 研发团队还发布了 Time-300B 数据集,为时序分析提供了丰富的训练资源,为各行各业的时间序列预测任务带来了新的解决方案。 在当今以数据为驱动的时代,时序预测已成为众多领域不可或缺的核心组成。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉