MoE

元象发布中国最大 MoE 开源大模型:总参数 255B,激活参数 36B
元象 XVERSE 发布中国最大 MoE 开源模型 XVERSE-MoE-A36B。该模型总参数 255B,激活参数 36B,官方号称效果能“大致达到”超过 100B 大模型的“跨级”性能跃升,同时训练时间减少 30%,推理性能提升 100%,使每 token 成本大幅下降。MoE(Mixture of Experts)混合专家模型架构,将多个细分领域的专家模型组合成一个超级模型,在扩大模型规模的同时,保持模型性能最大化,甚至还能降低训练和推理的计算成本。谷歌 Gemini-1.5、OpenAI 的 GPT-4 、

微软发布 Phi-3.5 系列 AI 模型:上下文窗口 128K,首次引入混合专家模型
微软公司今天发布了 Phi-3.5 系列 AI 模型,其中最值得关注的是推出了该系列首个混合专家模型(MoE)版本 Phi-3.5-MoE。本次发布的 Phi-3.5 系列包括 Phi-3.5-MoE、Phi-3.5-vision 和 Phi-3.5-mini 三款轻量级 AI 模型,基于合成数据和经过过滤的公开网站构建,上下文窗口为 128K,所有模型现在都可以在 Hugging Face 上以 MIT 许可的方式获取。AI在线附上相关介绍如下:Phi-3.5-MoE:首个混合专家模型Phi-3.5-MoE 是

“全球首创”单台 RTX 4090 服务器推理,昆仑万维开源 2 千亿稀疏大模型天工 MoE
昆仑万维今日宣布开源 2 千亿稀疏大模型 Skywork-MoE,基于之前昆仑万维开源的 Skywork-13B 模型中间 checkpoint 扩展而来,号称是首个完整将 MoE Upcycling 技术应用并落地的开源千亿 MoE 大模型,也是首个支持用单台 RTX 4090 服务器(8 张 RTX 4090 显卡)推理的开源千亿 MoE 大模型。据介绍,本次开源的 Skywork-MoE 模型隶属于天工 3.0 的研发模型系列,是其中的中档大小模型(Skywork-MoE-Medium),模型的总参数量为 1

MoE 高效训练的 A/B 面:与魔鬼做交易,用「显存」换「性能」
MoE 会成为未来大模型训练的新方向吗? 这是人们发现 MoE 架构可以用于大模型训练、推理后,发出的一声疑问。 MoE(Mixture of Experts),又称「混合专家」,本质是一种模块化的稀疏激活。

元象首个MoE大模型开源:4.2B激活参数,效果堪比13B模型
元象发布XVERSE-MoE-A4.2B大模型 , 采用业界最前沿的混合专家模型架构 (Mixture of Experts),激活参数4.2B,效果即可媲美13B模型。该模型全开源,无条件免费商用,让海量中小企业、研究者和开发者可在元象高性能“全家桶”中按需选用,推动低成本部署。GPT3、Llama与XVERSE等主流大模型发展遵循规模理论(Scaling Law), 在模型训练和推理的过程中,单次前向、反向计算时,所有参数都被激活,这被称为稠密激活 (densely activated)。 当 模型规模增大时,
「天工2.0」MoE大模型发布——「天工AI」国内首个MoE架构免费向C端用户开放的大语言模型应用全新问世
北京时间2月6日,昆仑万维正式发布新版MoE大语言模型「天工2.0」与新版「天工AI智能助手」APP,这是国内首个搭载MoE架构并面向全体C端用户免费开放的千亿级参数大语言模型AI应用。用户即日起可在各手机应用市场下载「天工AI智能助手」APP,体验昆仑万维「天工2.0」MoE大模型的卓越性能。「天工2.0」是昆仑万维自去年4月发布双千亿级大语言模型「天工」以来的最大规模版本升级,其采用业内顶尖的MoE专家混合模型架构,应对复杂任务能力更强、模型响应速度更快、训练及推理效率更高、可扩展性更强。此次更新全面升级了AI
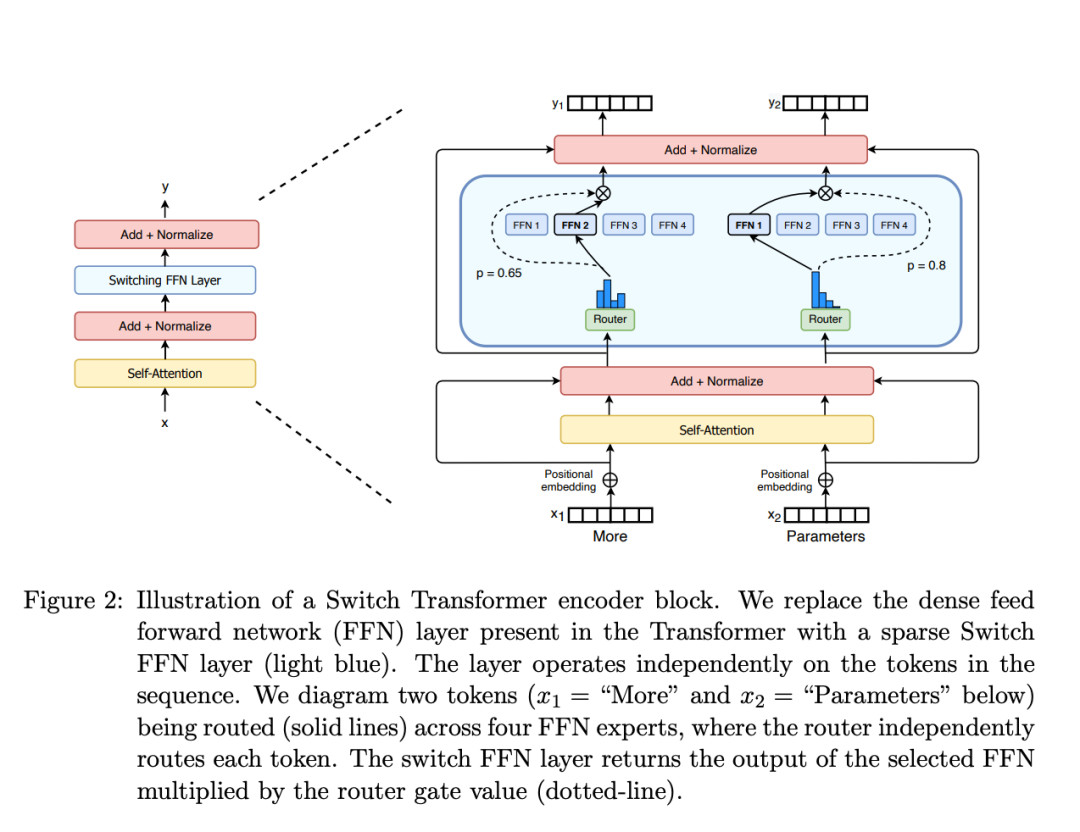
被OpenAI、Mistral AI带火的MoE是怎么回事?一文贯通专家混合架构部署
本文将介绍 MoE 的构建模块、训练方法以及在使用它们进行推理时需要考虑的权衡因素。专家混合 (MoE) 是 LLM 中常用的一种技术,旨在提高其效率和准确性。这种方法的工作原理是将复杂的任务划分为更小、更易于管理的子任务,每个子任务都由专门的迷你模型或「专家」处理。早些时候,有人爆料 GPT-4 是采用了由 8 个专家模型组成的集成系统。近日,Mistral AI 发布的 Mixtral 8x7B 同样采用这种架构,实现了非常不错的性能(传送门:一条磁力链接席卷 AI 圈,87GB 种子直接开源 8x7B MoE
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉