最近有点忙,没来得及更新,但一直保持着对前沿技术的紧密关注,不得不感叹当今技术日新月异。
多模态推理模型进展,现有的开源大型视觉语言模型在可扩展性、计算效率和高级推理能力方面显著落后于纯文本语言模型。
OpenAI的GPT-4o和Google的Gemini等模型能够无缝感知和解释视觉输入,但不开源,DeepSeek-R1等模型虽然采用了MoE架构,但在长上下文推理和多模态任务上仍有不足。
此外,早期的基于MoE的视觉语言模型在架构和能力上存在局限,无法处理长上下文和高分辨率视觉输入。
今天来看一下月之暗面最新的工作,基于MoE架构的高效多模态模型Kimi-VL。
先来看下Kimi-VL的主要创新:
- 创新的模型架构设计:该模型由 MoonViT(原生分辨率视觉编码器)、MLP 投影器和 MoE 语言模型组成,能够处理多种输入形式(单图像、多图像、视频、长文档等),在多种任务(如细粒度感知、数学问题、大学水平问题、OCR、代理任务等)上表现出色。
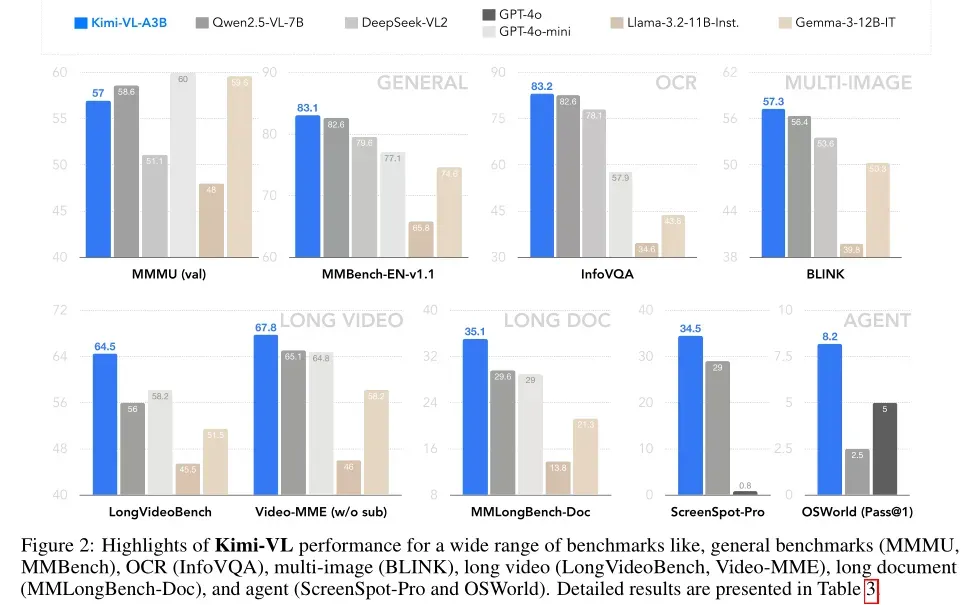
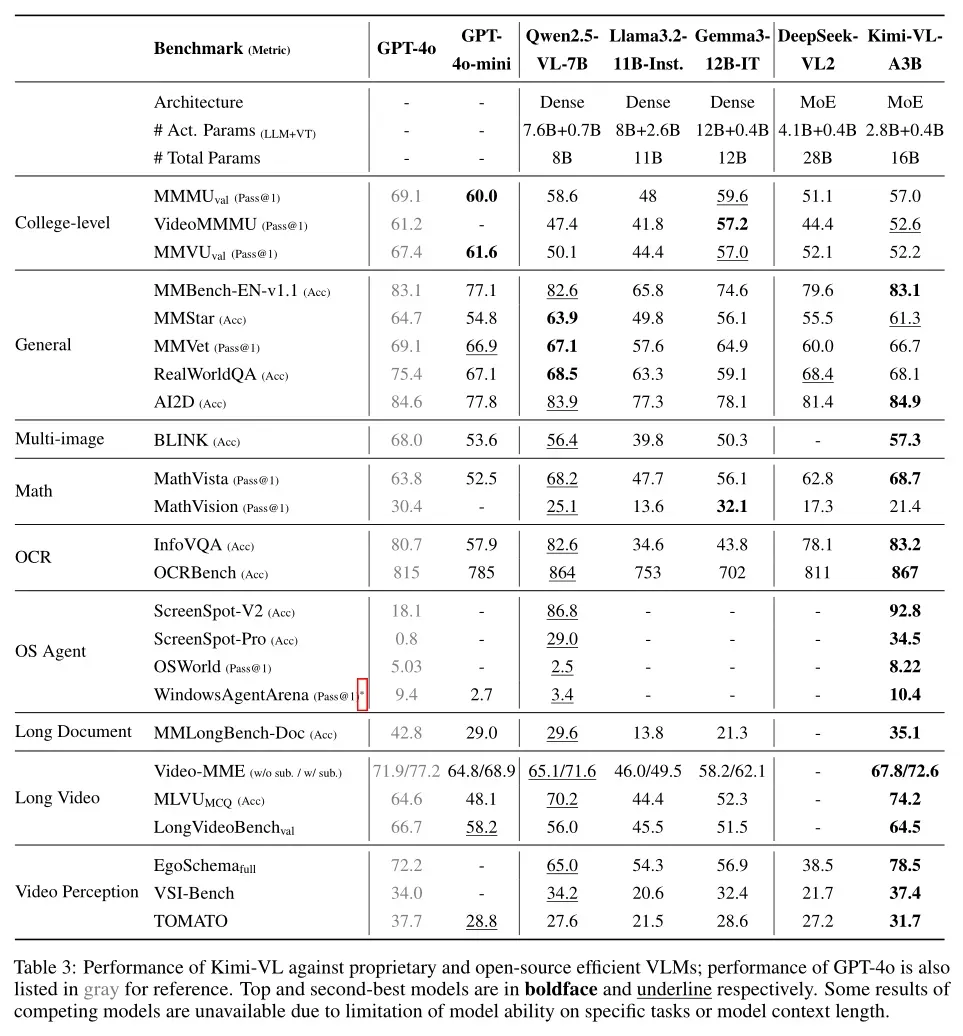
- 高效多模态推理能力:Kimi-VL 在多个具有挑战性的视觉语言任务中展现出强大的能力,包括大学水平的图像和视频理解、OCR、数学推理、多图像理解等,并在与 GPT-4omini、Qwen2.5-VL-7B、Gemma-3-12B-IT 等前沿高效 VLM 的比较评估中表现出色,甚至在某些关键领域超越了 GPT-4o。
- 长文本和长视频处理能力:Kimi-VL 拥有 128K 扩展上下文窗口,能够处理多样化的长输入,在 LongVideoBench 和 MMLongBench-Doc 等基准测试中取得了令人印象深刻的分数(分别为 64.5 和 35.1),并且其原生分辨率视觉编码器 MoonViT 能够清晰地看到和理解超高分辨率视觉输入,同时在常见任务中保持较低的计算成本。
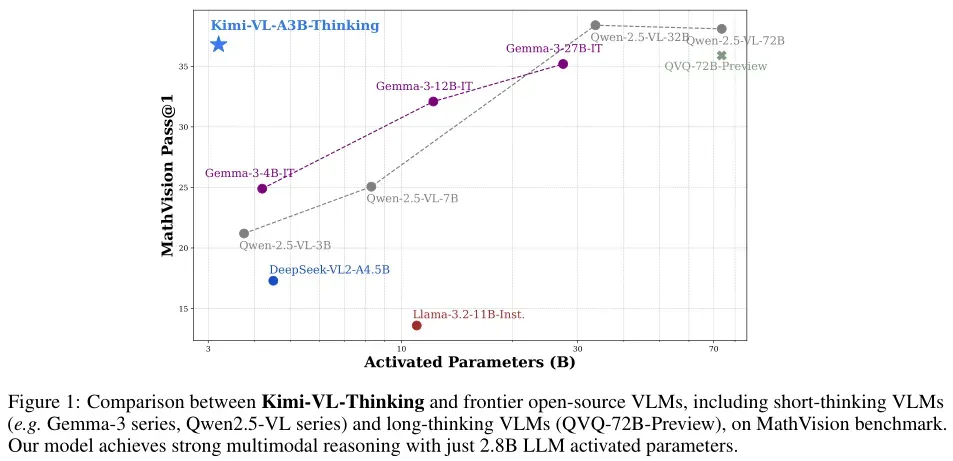
- 推出 Kimi-VL-Thinking 变体:基于 Kimi-VL,通过长链推理(CoT)监督微调(SFT)和强化学习(RL)开发了 Kimi-VL-Thinking,该模型仅2.8B激活参数就在 MMMU、MathVision 和 MathVista 等基准测试中表现出色。
再来看下突破性的性能表现:
- 与Qwen2.5-VL、Gemma-3等前沿开源VLM相比,Kimi-VL-Thinking仅使用2.8B激活参数即可实现强大的多模态推理。
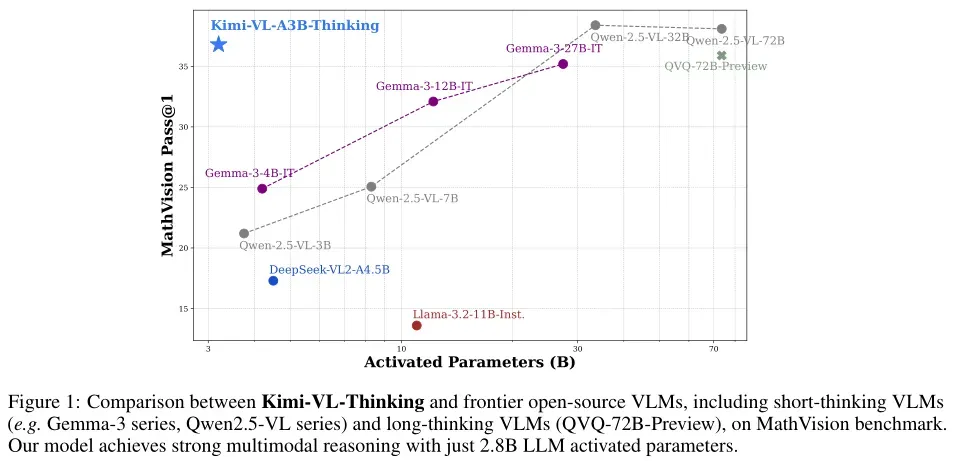
- 在一些重要基准测试中,Kimi新模型“以小博大”,2.8B的参数激活超越了GPT-4o、Llama-3.2等前沿模型。
下面来详细介绍下技术细节:
1、模型架构
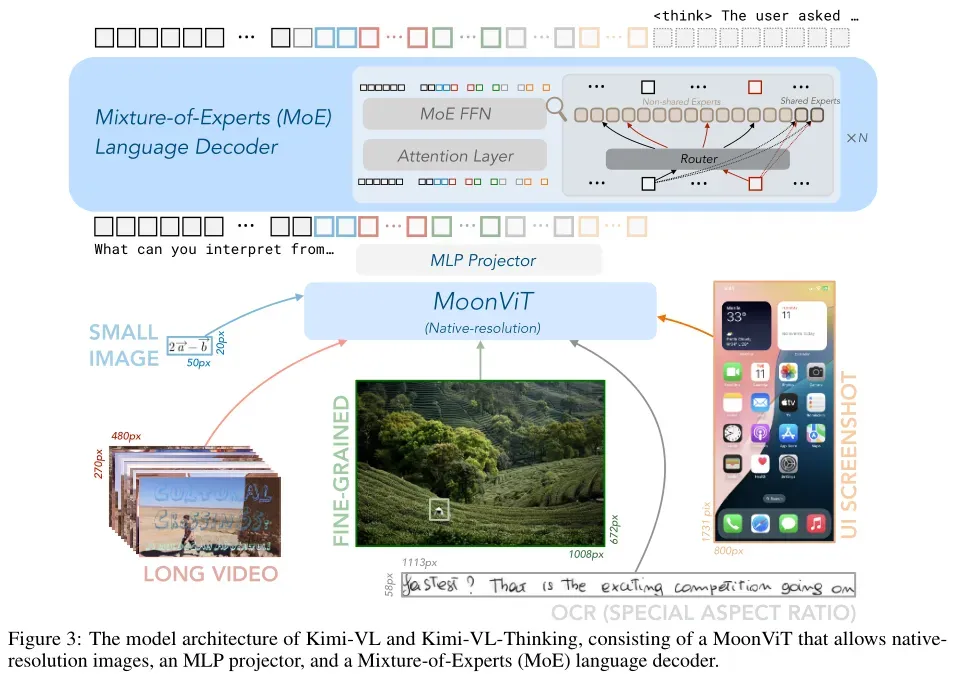
Kimi-VL 的模型架构由三个主要部分组成:原生分辨率视觉编码器(MoonViT)、MLP 投影器和混合专家(MoE)语言模型。
MoonViT:原生分辨率视觉编码器
MoonViT 是 Kimi-VL 的视觉编码器,其核心功能是能够直接处理不同分辨率的图像,而无需复杂的子图像分割和拼接操作。这种设计使得模型能够更自然地处理多样化的视觉输入,同时保持高效的计算性能。
实现细节:
- 图像预处理:MoonViT 采用 NaViT 的打包方法,将图像分割为图块(patches),展平后按顺序拼接成一维序列。这种预处理方法使得 MoonViT 能够与语言模型共享相同的核心计算算子和优化,例如变长序列注意力机制(如 FlashAttention)。
- 位置嵌入:MoonViT 基于 SigLIP-SO-400M 初始化并持续预训练,该模型原本使用可学习的固定尺寸绝对位置嵌入来编码空间信息。然而,随着图像分辨率的提高,这些插值后的嵌入逐渐变得不足。为了解决这一问题,在高度和宽度维度上引入了二维旋转位置嵌入(RoPE),从而改善了细粒度位置信息的表示,尤其是在高分辨率图像中。这两种位置嵌入方法共同为模型编码空间信息,并与展平和打包流程无缝集成。
- 输出特征:生成的连续图像特征随后被传递到 MLP 投影器,并最终输入 MoE 语言模型进行后续训练阶段。
MLP 投影器
MLP 投影器的作用是将视觉编码器(MoonViT)提取的图像特征投影到语言模型(LLM)的嵌入维度。这一过程确保了视觉特征能够被语言模型有效理解和处理。
实现细节:
- 像素混洗操作:首先使用像素混洗操作对 MoonViT 提取的图像特征进行空间维度压缩,进行 2×2 下采样并相应扩展通道维度。
- 两层 MLP:将像素混洗后的特征输入两层 MLP,将其投影到 LLM 嵌入的维度。
混合专家(MoE)语言模型
Kimi-VL 的语言模型采用 Moonlight 模型,一个具有2.8B激活参数、16B总参数的 MoE 语言模型,其架构与 DeepSeek-V3 相似。MoE 架构通过动态选择专家模块来处理输入,从而在保持高效计算的同时,提升模型的表达能力和推理能力。
实现细节:
- 初始化:从 Moonlight 预训练阶段的中间检查点初始化,该检查点已处理 5.2T 纯文本数据 token 并激活了 8192 token(8K)的上下文长度。
- 联合预训练:使用总计 2.3T token 的多模态和纯文本数据的联合配方继续预训练。这一过程确保了模型在语言和多模态任务上的全面能力。
- 专家选择:MoE 架构通过动态选择专家模块来处理输入,从而在保持高效计算的同时,提升模型的表达能力和推理能力。
增强版Muon优化器
在训练Kimi-VL模型时,优化器的选择对于模型的收敛速度和最终性能至关重要。本研究中使用了增强版的Muon优化器(Muon is Scalable for LLM Training),它在原始Muon优化器的基础上,通过增加权重衰减、调整Per-Parameter更新规模、基于ZeRO-1优化策略,开发了Muon优化器的分布式实现等方法进行了改进,以更好地适应大规模训练的需求。
2、预训练
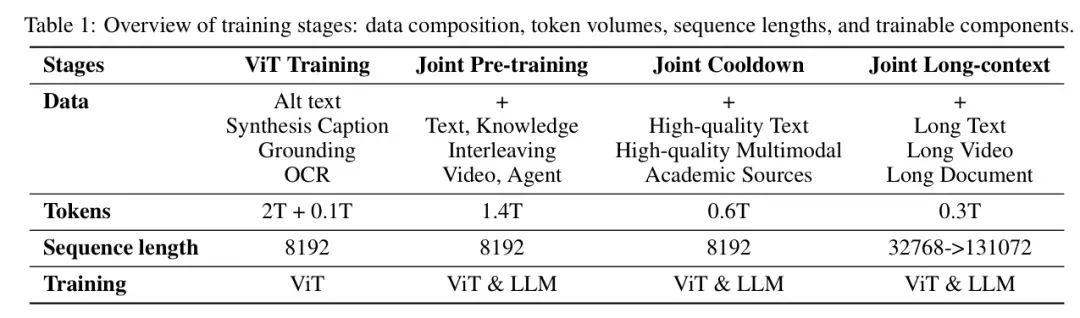
Kimi-VL的预训练过程包含四个阶段,每个阶段都有其特定的目标和数据组成,旨在逐步提升模型的语言和多模态能力。

ViT训练阶段
这一阶段的目标是训练一个强大的原生分辨率视觉编码器(MoonViT),使其能够高效处理不同分辨率的图像。
训练数据使用图像-文本对进行训练,其中文本部分包括:图像替代文本(alt text)、合成标题(synthetic captions)、grounding 边界框(grounding bboxes)、OCR 文本(OCR texts)。
方法:
- 损失函数:结合 SigLIP 损失(一种对比损失变体)和基于输入图像的标题生成交叉熵损失。最终损失函数为:
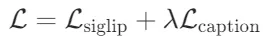 ,其中λ=2。
,其中λ=2。 - 训练策略:图像和文本编码器计算对比损失,文本解码器基于图像编码器的特征进行下一 token 预测(NTP)。为加速训练,使用 SigLIP SO-400M 权重初始化两个编码器,并采用渐进分辨率采样策略逐步允许更大尺寸的图像。
- 对齐阶段:在消耗 2T token 的 CoCa 式阶段训练 ViT 后,再用 0.1T token 将 MoonViT 与 MoE 语言模型对齐,此阶段仅更新 MoonViT 和 MLP 投影器。这一对齐阶段显著降低了语言模型中 MoonViT 嵌入的初始困惑度,为后续联合预训练阶段的平稳进行奠定了基础。
联合预训练阶段
这一阶段的目标是整合语言和视觉能力,提升模型的多模态理解能力。
训练数据使用纯文本数据和多模态数据的组合进行训练。多模态数据包括:图像-文本对、视频-文本对、OCR 数据、知识数据(如几何图形、图表等)
方法:
- 训练策略:从加载的 LLM 检查点继续训练,采用相同的学习率调度器,额外消耗 1.4T token。初始步骤仅使用语言数据,之后逐步增加多模态数据的比例。
- 渐进方法:通过逐步增加多模态数据的比例,确保模型在保留语言能力的同时,成功整合视觉理解能力。
联合冷却阶段
这一阶段的目标是通过高质量的数据进一步提升模型的性能,特别是在数学推理、知识型任务和代码生成方面
训练数据使用高质量的语言和多模态数据集进行训练,包括:合成数据(用于数学推理、知识型任务和代码生成)、经过筛选的学术视觉或视觉语言数据源
方法:
- 语言部分:通过实证研究,发现冷却阶段加入合成数据能显著提升性能,尤其是在数学推理、知识型任务和代码生成方面。冷却数据集的一般文本部分选自预训练语料库的高保真子集。
- 多模态部分:除了采用文本冷却数据准备的两种策略(即问答合成和高质量子集回放)外,还筛选并重写了多种学术视觉或视觉语言数据源为 QA 对。
- 采样策略:采用混合方法,利用选定的预训练子集,同时通过专有语言模型生成内容进行增强。通过拒绝采样技术生成 QA 对,并在整合到冷却数据集前进行全面验证。
联合冷却阶段是模型预训练过程中的一个重要环节,通过使用高质量的数据集和特定的训练策略,可以帮助模型在多种任务上表现出色,通过逐步减少数据的复杂性和多样性,帮助模型在训练过程中更加稳定,避免过拟合,进一步提升模型的性能和稳定性。
联合长上下文激活阶段
这一阶段的目标是扩展模型的上下文长度,使其能够处理更长的文本和视频输入。
训练数据使用长文本、长视频和长文档等长上下文数据进行训练。
方法:
- 上下文长度扩展:将模型的上下文长度从 8192(8K)扩展到 131072(128K),并将其 RoPE 嵌入的逆频率从 50,000 重置为 800,000。
- 分阶段扩展:联合长上下文阶段分为两个子阶段,每个子阶段将模型的上下文长度扩展四倍。在每个子阶段,将长数据的比例过滤并上采样至 25%,同时用剩余的 75% token 回放前一阶段的短数据。
- 数据组成:长上下文激活数据不仅包含长文本,还包括长多模态数据,如长交错数据、长视频和长文档。还合成了一小部分 QA 对以增强长上下文激活的学习效率。
经过长上下文激活后,模型能够通过长纯文本或长视频的 NIAH 评估,证明了其多功能的长上下文能力。具体来说,模型在不同上下文长度范围内的 NIAH 召回准确率如表所示:

3、后训练
在预训练阶段之后,Kimi-VL 进入后训练阶段,这一阶段的目标是通过特定的任务数据进一步微调模型,以提升其在实际应用中的性能。后训练阶段主要包括以下几个部分:联合监督微调(SFT)、长链推理(CoT)监督微调和强化学习(RL)。

联合监督微调(SFT)
这一阶段,通过基于指令的微调,增强模型遵循指令和进行对话的能力,最终形成交互式的 Kimi-VL 模型。
训练数据使用纯文本和视觉语言 SFT 数据的混合进行训练。这些数据包括指令-响应对,覆盖多种任务和场景。
长链推理(CoT)监督微调
这一阶段,通过长链推理(CoT)监督微调,提升模型在复杂推理任务中的表现。
训练数据基于精炼的RL提示集,通过提示工程构建了一个高质量的长 CoT 预热数据集,包含针对文本和图像输入的经过准确验证的推理路径。生成的预热数据集旨在封装对人类式推理至关重要的关键认知过程,例如规划(模型在执行前系统化步骤)、评估(对中间步骤的关键评估)、反思(重新考虑并改进方法)和探索(鼓励考虑替代解决方案)。
方法:对预热数据集进行轻量级监督微调,引导模型内化这些多模态推理策略。逐步增加推理路径的复杂性,使模型能够处理更复杂的推理任务。
强化学习(RL)
这一阶段,通过强化学习进一步提升模型的推理能力,使其能够自主生成结构化的 CoT 推理过程。
方法:采用在线策略镜像下降变体作为 RL 算法,通过迭代优化策略模型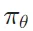 以提高其问题解决准确性。在第i次训练迭代中,将当前模型视为参考策略模型,并优化以下目标,通过相对熵正则化以稳定策略更新:
以提高其问题解决准确性。在第i次训练迭代中,将当前模型视为参考策略模型,并优化以下目标,通过相对熵正则化以稳定策略更新:
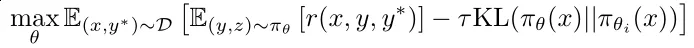
4、实验结果
与前沿模型对比
推理能力
- Kimi-VL 的长链推理(CoT)能力通过长 CoT 监督微调和强化学习得到了显著提升,使其在处理复杂的多步推理任务时具有强大的能力。
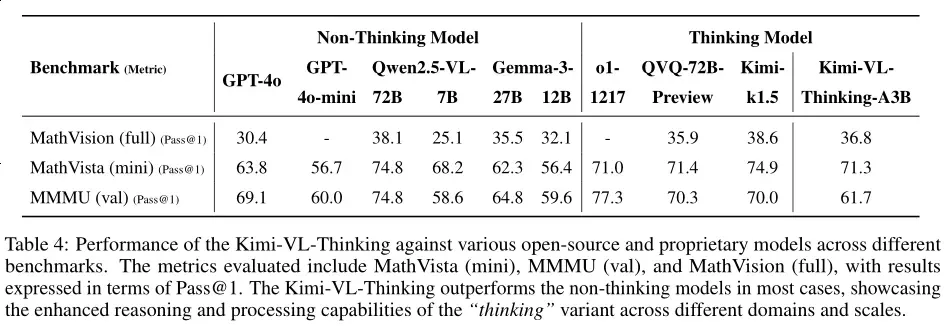
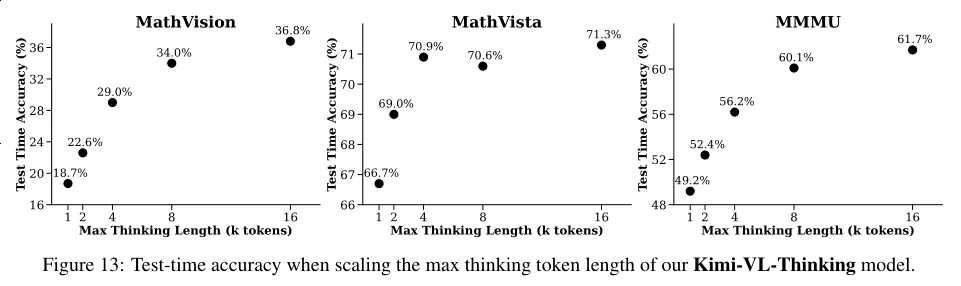
- Kimi-VL-Thinking 在测试时推理长度的扩展也表现出色,表明 Kimi-VL-Thinking 能够利用更长的推理链来提高其在复杂任务中的表现。
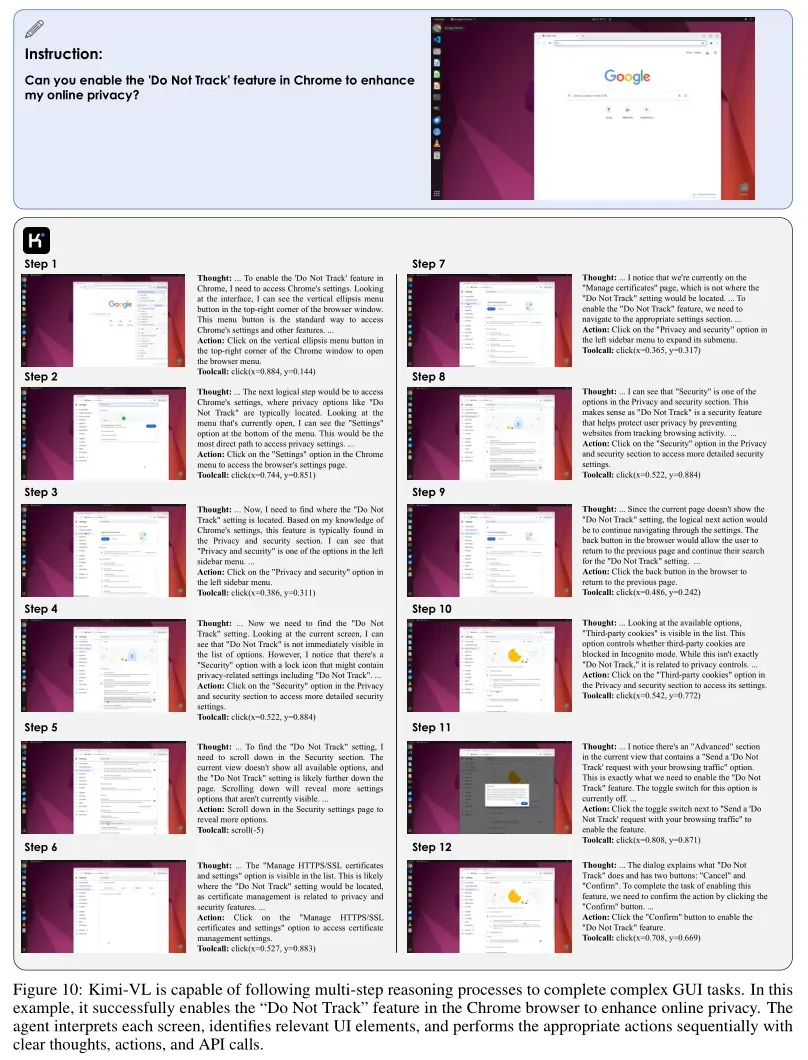
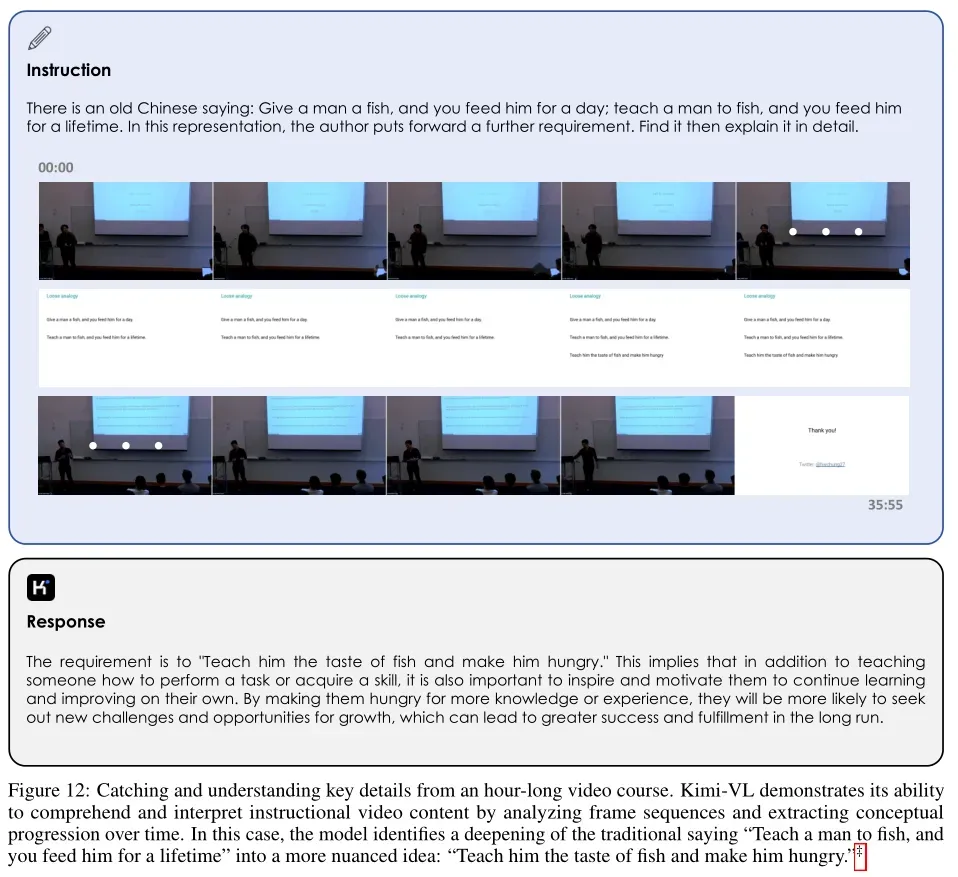
5、Kimi-VL能力展示