多模态模型

月之暗面再推多模态新模型,Kimi K2 升级版拟于第一季度亮相
近日,据《科创板日报》消息,国内大模型领先企业月之暗面计划在2026年第一季度(拟定于1月或3月)上线全新的多模态模型。 据悉,该模型型号或定名为K2.1/K2.5,将在多模态处理与智能体(Agent)能力上实现进一步突破。 这款即将推出的新产品是基于月之暗面首个万亿参数开源模型Kimi K2升级而来。

DeepMind 首席执行官预测 2026 年三大 AI 发展趋势
在近期举办的 Axios AI 峰会上,谷歌 DeepMind 的首席执行官德米斯・哈萨比斯(Demis Hassabis)分享了他对未来一年 AI 领域的展望。 他指出,2026 年将是多模态模型、互动视频世界和更可靠的 AI 代理迅速发展的关键一年。 哈萨比斯强调,DeepMind 的最新 AI 模型 “Gemini” 已在多模态能力方面取得了显著进展。

商汤NEO开源:用1/10数据量媲美顶级多模态模型,终结"拼凑式"AI时代
商汤科技与南洋理工大学S-Lab联合发布并开源全新多模态模型架构NEO,通过底层架构创新实现视觉与语言的深层统一,在性能、效率和通用性上取得全面突破。 极致数据效率:1/10数据量达顶尖性能NEO最显著的突破在于其极高的数据效率——仅需3.9亿图像文本示例,相当于业界同等性能模型1/10的数据量,便能开发出顶尖的视觉感知能力。 无需依赖海量数据及额外视觉编码器,NEO凭借简洁架构在多项视觉理解任务中追平Qwen2-VL、InternVL3等顶级模块化旗舰模型。

法国 AI 公司 Mistral 发布新模型,力求与 OpenAI 和谷歌保持竞争
法国人工智能初创公司 Mistral 于周二发布了一系列新模型,旨在追赶全球领先的 AI 实验室如谷歌、OpenAI 和 DeepSeek。 此次发布紧随 DeepSeek 和谷歌近期的模型更新,显示出全球 AI 实验室在研究前沿和商业运营方面的激烈竞争。 Mistral 此次推出了一个大型模型,声称是 “世界上最好的开放权重多模态和多语言模型”。

谷歌Gemini 3发布后迅速登顶LMArena排行榜,马斯克与阿尔特曼齐送祝贺
谷歌发布Gemini 3后,其中Gemini 3 Pro以1501 Elo刷新LMArena公开榜单历史最高分,超越GPT-5.1、Claude 4. 5 与Grok-4.1,成为目前评分最高的多模态模型。 性能方面,Gemini 3 Pro在“人类终极考试”获37.5%、GPQA Diamond达91.9%,并在MMMU-Pro与Video-MMMU分别取得81%与87.6%,显示其在科学、数学及视频理解任务上全面领先。

苹果即将在2025年国际计算机视觉大会亮相
在全球科技界备受瞩目的国际计算机视觉大会(ICCV)即将于2025年10月19日至23日在美丽的檀香山召开,苹果公司确认将携带多项重要研究成果亮相这一盛会。 此次大会旨在聚焦计算机视觉领域的前沿技术和研究进展,苹果也不例外,将展示他们在多模态模型和视频生成等热点领域的最新研究。 图源备注:图片由AI生成,图片授权服务商Midjourney苹果公司将提交并展示八篇论文,涵盖多种重要议题。

马斯克挖角 NVIDIA 核心团队,xAI 加速 “世界模型” 研发
埃隆・马斯克的人工智能公司 xAI 正在全力推进 “世界模型” 的开发,这一技术被认为是实现通用人工智能(AGI)的重要途径。 为了加快这一进程,xAI 从竞争对手 NVIDIA 挖来了两名核心研究员 ——Zeeshan Patel 和 Ethan He。 两位新加入的团队成员都在 NVIDIA 的 Omniverse 平台中发挥了重要作用,为 xAI 的研发带来了宝贵的经验和技术支持。
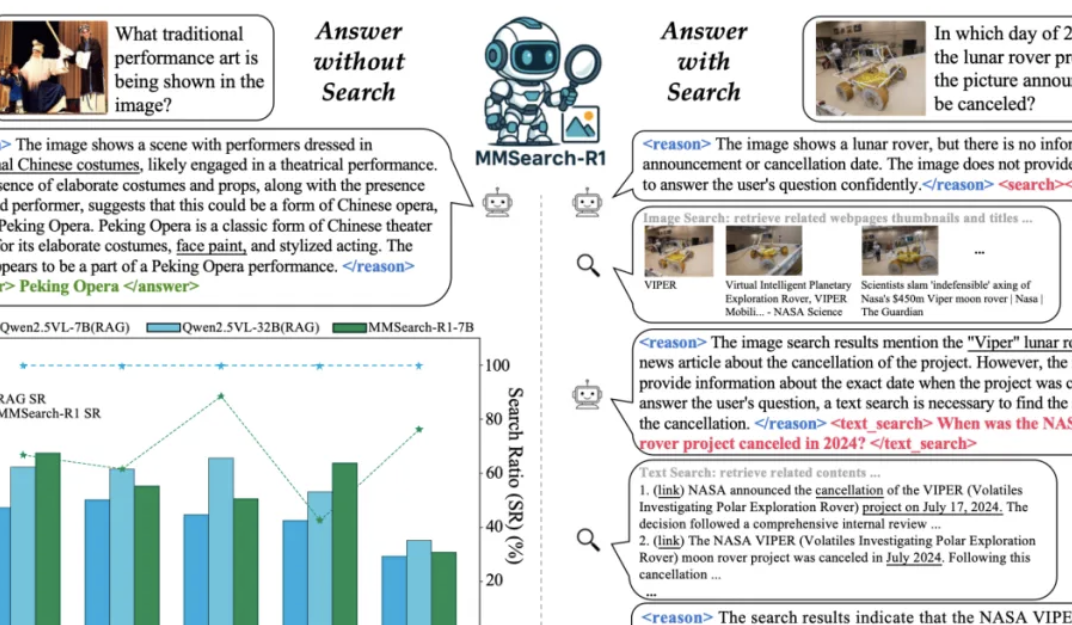
多模态模型学会“按需搜索”,少搜30%还更准!字节&NTU新研究优化多模态模型搜索策略
多模态模型学会“按需搜索”! 字节&NTU最新研究,优化多模态模型搜索策略——. 通过搭建网络搜索工具、构建多模态搜索数据集以及涉及简单有效的奖励机制,首次尝试基于端到端强化学习的多模态模型自主搜索训练。
约翰斯・霍普金斯大学研发新 AI 模型,可更准确预测心源性猝死风险
美国约翰斯·霍普金斯大学开发出一款多模态人工智能模型,在识别突发性心脏骤停高风险人群方面,明显优于现行的临床指南。这一研究结果已在最新一期的《自然-心血管研究》杂志上发表。
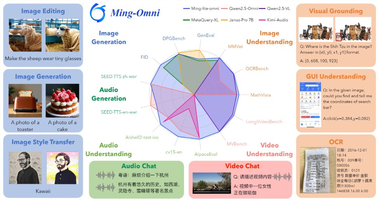
蚂蚁集团和inclusionAI联合推Ming-Omni:首个开源版多模态GPT-4o
近日,Inclusion AI 与 蚂蚁集团联合推出了一款名为 “Ming-Omni” 的先进多模态模型,标志着智能技术的新突破。 Ming-Omni 能够处理图像、文本、音频及视频,为多种应用提供强大支持,其功能不仅涵盖语音和图像生成,还具备多模态输入的融合处理能力。 ** 全面的多模态处理能力 **Ming-Omni 的设计中采用了专用编码器来提取不同模态的标记(tokens),这些标记经过 “Ling” 模块(即混合专家架构,MoE)进行处理,后者配备了新提议的模态特定路由器。
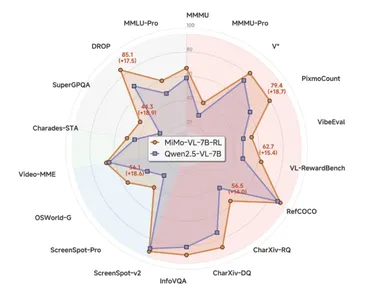
小米多模态大模型Xiaomi MiMo-VL开源
近日,小米公司研发的MiMo-VL多模态模型接过MiMo-7B的接力棒,在多个领域展现出了强大的实力。 该模型在图片、视频、语言的通用问答和理解推理等多个任务上大幅领先同尺寸标杆多模态模型Qwen2.5-VL-7B,在GUI Grounding任务上的表现更是可与专用模型相媲美,为Agent时代的到来做好了准备。 MiMo-VL-7B在多模态推理任务上成绩斐然,尽管参数规模仅为7B,却在奥林匹克竞赛(OlympiadBench)和多个数学竞赛(MathVision、MathVerse)中大幅领先参数规模10倍大的阿里Qwen-2.5-VL-72B和QVQ-72B-Preview,同时也超越了闭源模型GPT-4o。

可能是目前最好的3B多模态模型,有望做“AI作业帮”
作者 | 徐浚哲、尹宇阳我们团队近期开源多模态模型VLR1-3B的预览版(preview),欢迎大家尝试:“小”模型,使用了强化学习训练方式,增强了推理性能。 达到了同级别模型中推理能力第一(SOTA)。 主要是数学相关的测试,在MathVista和MathVision这两个权威AI数学榜单的官网上,VLR1-3B 这“小”模型不仅都在榜,而且比很多商业闭源大模型(如Gemini1.5和GPT-4V)表现都要强,甚至在MathVista的评测中领先GPT-4o~同时对比了多个banchMark结果,Average第一~ModelAverageMathVistaMathVisionMathVerseDynaMathWeMathLogicVistaQwen2-VL-2B20.548.016.117.53.810.826.6InternVL2.5-2B21.251.114.022.34.48.027.3InternVL3-2B29.157.620.224.514.822.940.3Qwen2.5-VL-3B31.861.221.931.213.222.940.3VLM-R1-3B-Math-030533.462.721.932.213.030.040.5Taichu-VLR-3B33.664.923.132.112.630.438.7VLAA-Thinker-Qwen2.5VL-3B35.461.024.436.418.233.838.5TBAC-VLR1-3B-preview35.764.825.033.217.732.440.8正巧最近正愁帮邻居刚上初中的孩子批数学作业,被多项式计算和几何证明搞得焦头烂额的。
GPT-4o图像生成功能现已集成至自定义GPTs
2025年4月26日 AIbase报道:OpenAI近日宣布,其旗舰多模态模型GPT-4o的图像生成功能现已正式集成至ChatGPT的自定义GPTs功能中。 这一更新标志着用户创建的定制化AI助手能够直接生成和编辑图像,为内容创作、设计和教育等领域带来更多可能性。 无缝集成的图像生成体验GPT-4o的图像生成功能此前已于2025年3月25日起在ChatGPT和Sora平台向免费、Plus、Pro和Team用户逐步开放。

字节跳动推出Vidi多模态模型,引领超长视频理解与编辑新潮流
字节跳动宣布推出全新多模态模型Vidi,专注于视频理解与编辑,首版核心能力为精准的时间检索功能。 据AIbase了解,Vidi能够处理视觉、音频和文本输入,支持长达一小时的超长视频分析,在时间检索任务上性能超越GPT-4o与Gemini等主流模型。 这一突破性技术已在AI社区引发热烈讨论,相关细节通过字节跳动官方渠道与GitHub公开。
OpenAI发布两款多模态推理模型o4-mini、满血版o3
在今天凌晨1点的技术直播中,OpenAI正式推出其最新且最强大的多模态模型o4-mini和满血版o3。 这两款模型具备独特优势,不仅能同时处理文本、图像和音频,还可作为智能体自动调用网络搜索、图像生成、代码解析等工具,并且拥有深度思考模式,能在思维链中思考图像。 OpenAI公布的测试数据显示,o4-mini表现卓越。

Moonshot AI开源轻量级MoE多模态模型Kimi-VL,2.8B参数媲美SOTA模型!
最近有点忙,没来得及更新,但一直保持着对前沿技术的紧密关注,不得不感叹当今技术日新月异。 多模态推理模型进展,现有的开源大型视觉语言模型在可扩展性、计算效率和高级推理能力方面显著落后于纯文本语言模型。 OpenAI的GPT-4o和Google的Gemini等模型能够无缝感知和解释视觉输入,但不开源,DeepSeek-R1等模型虽然采用了MoE架构,但在长上下文推理和多模态任务上仍有不足。

阿里推出全新多模态模型 Qwen2.5-VL-32B:兼顾视觉语言与数学推理
在人工智能领域,阿里巴巴再次带来了重磅消息。 近日,阿里开源了最新的多模态模型 ——Qwen2.5-VL-32B-Instruct。 这款新模型是 Qwen2.5系列中的一员,其他版本包括3B、7B 和72B,而32B 版本在保持性能的同时,更加注重便捷的本地运行体验。

阿里云魔搭首发上线阶跃星辰最新开源的两款多模态模型
全球开发者目光再次聚焦中国!在备受瞩目的全球开发者大会(GDC)上,阿里云魔搭社区重磅宣布,首发上线阶跃星辰最新开源的两款多模态模型,包括 全球参数量最大的开源视频生成模型 Step-Video-T2V,以及 业界首款产品级开源语音交互模型 Step-Audio。 这一消息瞬间引爆全球AI开源社区,再次彰显中国在人工智能领域的强劲创新实力。 作为中国最大的AI模型社区,阿里云魔搭社区此次发布的这两款重磅模型,无疑是近期全球多模态领域最受瞩目的开源成果。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
大语言模型
字节跳动
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉