架构

AI 时代下设计模式的逆袭:为何经典架构思想从未过时?
一、设计模式的“前世今生”:从被忽视到重新审视在软件开发的漫长历程中,设计模式曾经历过备受追捧、过度使用,乃至被部分开发者束之高阁的阶段。 20世纪90年代,《设计模式:可复用面向对象软件的基础》一书的问世,如同在软件开发领域投下一颗重磅炸弹。 抽象工厂、装饰器等模式成为开发者们热议的话题,它们为解决常见问题提供了标准化的方案,建立了一套通用的技术语言,让开发者无需每次都从零开始构思解决方案。

构建强大AI Agent的关键 = Pydantic AI + MCP + Advanced Web Scraping
引言在文中,我将展示一个超快速教程,教你如何使用 Pydantic AI、MCP 和高级网页抓取技术,构建一个强大的智能聊天机器人,适用于商业或个人用途。 MCP 逐渐被接受,因为它是一个开放标准。 我制作了一些非常酷的视频,你一定会喜欢。

硬核分享!构建单智能体已经Out了!大佬分享:架构设计如何推动可靠的多智能体编排
作者 | Nikhil Gupta,Atlassian AI产品管理负责人编译 | 云昭出品 | 51CTO技术栈(微信号:blog51cto)时至今日,如果再提如何构建一个Agent,肯定已经过时了。 打造一个超级智能的单一模型已经不再是2025年的主旋律。 而真正的力量和令人兴奋的新领域,是让多个专业化的AI智能体协同运转起来。

Claude 4一战封神!找出6万行架构级重构的白鲸bug! 前大厂开发者自述:四年投入了200个小时没发现,别的模型都没做到!
出品 | 51CTO技术栈(微信号:blog51cto)今天,一篇Reddit上的帖子走红了,光看题目就很有料:Claude Opus 帮我解决了一个我四年来都找不到的“白鲸级 bug”图片发帖人是一位有 30 年经验的前 FAANG C 工程师,是团队里负责给bug清场的大佬级角色。 但这一次,他坦言被 Claude Opus “彻底震撼了”。 这个 Bug 有多棘手?
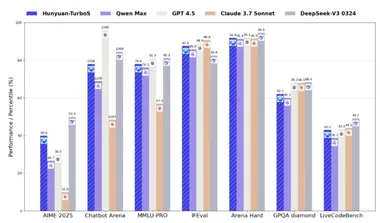
腾讯混元 TurboS 技术报告全面揭秘,560B参数混合Mamba架构
腾讯发布了混元 TurboS 技术报告,揭示了其旗舰大语言模型 TurboS 的核心创新与强大能力。 根据全球权威大模型评测平台 Chatbot Arena 的最新排名,混元 TurboS 在239个参赛模型中位列第七,成为国内仅次于 Deepseek 的顶尖模型,并在国际上仅落后于谷歌、OpenAI 及 xAI 等几家机构。 混元 TurboS 模型的架构采用了创新的 Hybrid Transformer-Mamba 结构,这种新颖的设计结合了 Mamba 架构在处理长序列上的高效性与 Transformer 架构在上下文理解上的优势,从而实现了性能与效率的平衡。

字节提出从单一主题发展到多主题定制的通用框架UNO,通过情境生成释放更多可控性
字节跳动的智能创作团队提出了一个从单一主题发展到多主题定制的通用框架UNO,从少到多的泛化:通过情境生成释放更多可控性。 能够将不同的任务统一在一个模型下。 在单主题和多主题驱动的生成中都能实现高度一致性,同时确保可控性。

Transformer 模型结构详解及代码实现!
一、Transformer简要发展史以下是Transformer模型发展历史中的关键节点:Transformer架构于2017年6月推出。 原本研究的重点是翻译任务。 随后推出了几个有影响力的模型,包括:时间模型简要说明2017 年 6 月「Transformer」Google 首次提出基于 Attention 的模型,用于机器翻译任务2018 年 6 月「GPT」第一个使用 Transformer 解码器模块进行预训练的语言模型,适用于多种 NLP 任务2018 年 10 月「BERT」使用 Transformer 编码器模块,通过掩码语言建模生成更强大的句子表示2019 年 2 月「GPT-2」更大更强的 GPT 版本,由于潜在风险未立即发布,具备出色的文本生成能力2019 年 10 月「DistilBERT」BERT 的轻量化版本,在保留 97% 性能的同时,速度更快、内存占用更低2019 年 10 月「BART、T5」使用完整的 Encoder-Decoder 架构,在各种 NLP 任务中表现优异2020 年 5 月「GPT-3」超大规模语言模型,支持“零样本学习”,无需微调即可完成新任务这个列表并不全面,只是为了突出一些不同类型的 Transformer 模型。

全新GPU高速互联设计,为大模型训练降本增效!北大/阶跃/曦智提出新一代高带宽域架构
随着大模型的参数规模不断扩大,分布式训练已成为人工智能发展的中心技术路径。 如此一来,高带宽域的设计对提升大模型训练效率至关重要。 然而,现有的HBD架构在可扩展性、成本和容错能力等方面存在根本性限制:以交换机为中心的HBD(如NVIDIA NVL-72)成本高昂、不易扩展规模;以GPU为中心的HBD(如 Google TPUv3和Tesla Dojo)存在严重的故障传播问题;TPUv4等交换机-GPU混合HBD采用折中方案,但在成本和容错方面仍然不甚理想。

RAG架构综述:探寻最适配RAG方案
RAG技术通过整合外部知识源检索与模型生成能力,使语言模型能够基于真实世界的信息生成更准确、可靠的回答。 如今,RAG技术不断演进,衍生出了多种各具特色的架构类型,每种都针对特定场景和需求进行了优化。 深入了解这些不同类型的RAG架构,对于开发者、数据科学家以及AI爱好者而言至关重要,能够帮助他们在项目中做出更合适的技术选型,充分发挥RAG的优势。

DeepSeek-V3 发布新论文,揭示低成本大模型训练的奥秘
近日,DeepSeek 团队发布了关于其最新模型 DeepSeek-V3的一篇技术论文,重点讨论了在大规模人工智能模型训练中遇到的 “扩展挑战” 以及与硬件架构相关的思考。 这篇长达14页的论文不仅总结了 DeepSeek 在开发 V3过程中的经验与教训,还为未来的硬件设计提供了深刻的见解。 值得注意的是,DeepSeek 的 CEO 梁文锋也参与了论文的撰写。

ICML 2025 Spotlight|华为诺亚提出端侧大模型新架构MoLE,内存搬运代价降低1000倍
Mixture-of-Experts(MoE)在推理时仅激活每个 token 所需的一小部分专家,凭借其稀疏激活的特点,已成为当前 LLM 中的主流架构。 然而,MoE 虽然显著降低了推理时的计算量,但整体参数规模依然大于同等性能的 Dense 模型,因此在显存资源极为受限的端侧部署场景中,仍然面临较大挑战。 现有的主流解决方案是专家卸载(Expert Offloading),即将专家模块存储在下层存储设备(如 CPU 内存甚至磁盘)中,在推理时按需加载激活的专家到显存进行计算。

开源的轻量化VLM-SmolVLM模型架构、数据策略及其衍生物PDF解析模型SmolDocling
缩小视觉编码器的尺寸,能够有效的降低多模态大模型的参数量。 再来看一个整体的工作,从视觉侧和语言模型侧综合考量模型参数量的平衡模式,进一步降低参数量,甚至最小达256M参数量,推理时显存占用1GB。 下面来看看,仅供参考。

模型压缩到70%,还能保持100%准确率,无损压缩框架DFloat11来了
大型语言模型(LLMs)在广泛的自然语言处理(NLP)任务中展现出了卓越的能力。 然而,它们迅速增长的规模给高效部署和推理带来了巨大障碍,特别是在计算或内存资源有限的环境中。 例如,Llama-3.1-405B 在 BFloat16(16-bit Brain Float)格式下拥有 4050 亿个参数,需要大约 810GB 的内存进行完整推理,超过了典型高端 GPU 服务器(例如,DGX A100/H100,配备 8 个 80GB GPU)的能力。

ICLR 2025 Oral|差分注意力机制引领变革,DIFF Transformer攻克长序列建模难题
近年来,Transformer 架构在自然语言处理领域取得了巨大成功,从机器翻译到文本生成,其强大的建模能力为语言理解与生成带来了前所未有的突破。 然而,随着模型规模的不断扩大和应用场景的日益复杂,传统 Transformer 架构逐渐暴露出缺陷,尤其是在处理长文本、关键信息检索以及对抗幻觉等任务时,Transformer 常常因过度关注无关上下文而陷入困境,导致模型表现受限。 为攻克这一难题,来自微软和清华的研究团队提出了 DIFF Transformer,一种基于差分注意力机制的创新基础模型架构。

Transformer+Mamba黄金组合!长文推理性能飙升3倍,性能还更强
过去几年,Transformer虽稳坐AI架构「铁王座」,但其二次方复杂度带来的算力消耗和长序列处理瓶颈,限制了大模型在推理阶段处理长文本。 Mamba凭借「线性复杂度」异军突起,非常适合长序列任务,有望成为Transformer架构的替代品,但在处理全局关系上偏弱。 Mamba Transformer混合架构可以将二者的优势互补,实现「效率」和「性能」的双丰收。

谷歌提出Transformer架构中,表示崩塌、过度压缩的五个解决方法
Transformer架构的出现极大推动了生成式AI的发展,在此基础之上开发出了ChatGPT、Copilot、讯飞星火、文心一言、Midjourney等一大批知名产品。 但Transformer架构并非完美还存在不少问题,例如,在执行需要计数或复制输入序列元素的任务经常会出错。 而这些操作是推理的基本组件,对于解决日常任务至关重要。

CVPR满分论文 | 英伟达开源双目深度估计大模型FoundationStereo
本文介绍了 FoundationStereo,一种用于立体深度估计的基础模型,旨在实现强大的零样本泛化能力。 通过构建大规模(100 万立体图像对)合成训练数据集,结合自动自筛选流程去除模糊样本,并设计了网络架构组件(如侧调谐特征主干和远程上下文推理)来增强可扩展性和准确性。 这些创新显著提升了模型在不同领域的鲁棒性和精度,为零样本立体深度估计设立了新标准。

DeepSeek 悄然发布 DeepSeek-V3–0324:远超预期的重大升级
DeepSeek 近期悄然发布的 DeepSeek-V3–0324,在 AI 社区和行业内引发了广泛关注。 这一版本是 DeepSeek V3 (DeepSeek-V3 深度剖析:下一代 AI 模型的全面解读)模型的重要升级,其带来的一系列技术革新和性能提升远超众人预期,为开发者和企业带来了新的机遇与可能。 一、DeepSeek-V3–0324 的技术突破(一)Multi-head Latent Attention(MLA)和增强的 DeepSeekMoE 架构DeepSeek-V3–0324 引入了 Multi-head Latent Attention(MLA)和增强版的 DeepSeekMoE 架构,这些创新技术为模型性能的提升奠定了坚实基础。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
大语言模型
字节跳动
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉