Transformer架构的出现极大推动了生成式AI的发展,在此基础之上开发出了ChatGPT、Copilot、讯飞星火、文心一言、Midjourney等一大批知名产品。
但Transformer架构并非完美还存在不少问题,例如,在执行需要计数或复制输入序列元素的任务经常会出错。而这些操作是推理的基本组件,对于解决日常任务至关重要。
所以,谷歌DeepMind和牛津大学的研究人员发布了一篇论文,深度研究了在解码器Transformer架构中的“表示崩塌”和“过度压缩”两大难题,同时提供了几个简单的解决方案。

表示崩塌
表示崩溃是指在某些情况下,输入给大模型的不同序列在经过处理后,会生成非常相似甚至几乎相同的表示,并导致模型无法具体区分它们。
这是因为Transformer架构中的自注意力机制和位置编码的设计,使得随着序列的增长,信息的表示越来越集中,从而导致信息的损失。
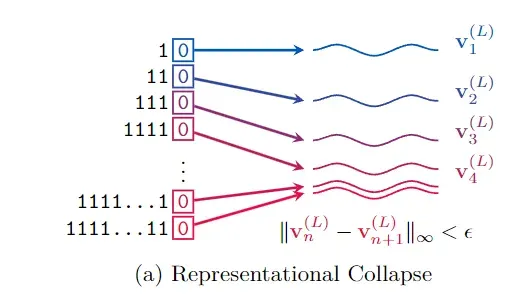
为了更好地解释这种表示崩溃,研究人员定义了两个序列的表示差异,并在Gemma 7B大语言模型中进行了实验。

一组是逐渐增长的1的序列,另一组是在1的序列末尾添加了一个额外的1。通过观察这两组序列在Transformer模型中的表示。
研究人员发现,随着序列长度的增加,两组序列的表示差异逐渐减小,直至低于机器的浮点精度,这时大模型已经无法精准区分这两个序列了。
过度压缩
过度压缩现象的出现与表示崩塌有很大关系。在Transformer模型中,过度压缩的表现为早期输入的token在模型的最终表示中的影响力减弱,特别是当这些token距离序列的末尾较远时。
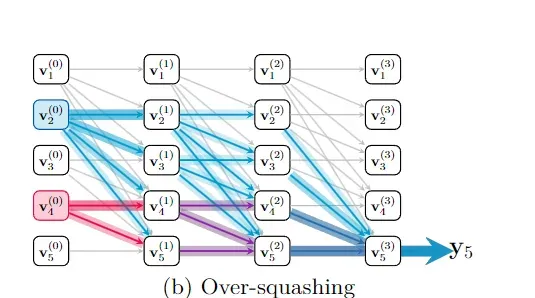
由于Transformer模型的自注意力机制和层叠结构,数据在每一层都会经过多次的压缩和重新分配,这可能导致一些重要的信息在传播过程中被稀释或变得非常不明显。
为了展示过度压缩在Transformer中的详细表现,研究人员深度分析了如何通过模型的每一层传递并最终影响下一个token的预测。
研究人员发现,对于序列中较早的token,由于它们可以通过更多的路径影响最终的表示,因此它们的影响力会随着序列长度的增加而减少。这种影响力随着token在序列中的位置而变化,序列开始的token比序列末尾的token更容易在模型的表示中保留其信息。
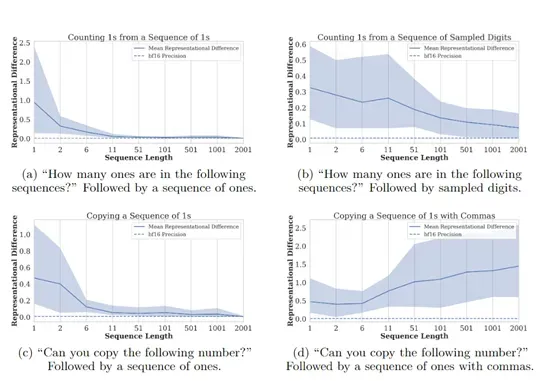
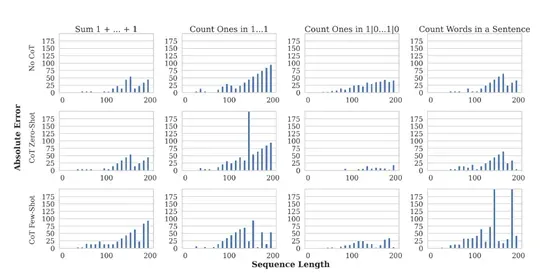
同样为了验证该现象的存在,研究人员在Gemini 1.5和Gemma 7B模型中进行了复制和计数任务实验。
结果显示,当序列长度增加时,模型在复制序列末尾的token时表现不佳,而在复制序列开始的token时表现较好,这基本验证了过度压缩的现象确实存在。
五个解决方案
为了解决Transformer架构中的表示崩塌和过度压缩两大难题,研究人员提出了5个简单有效的解决方法。
改进注意力机制:最直接的方法就是改进Transformer架构中的自注意力机制。通过调整注意力权重的分配,可以增强模型对序列中早期token的关注。这可以通过修改注意力分数的计算方式来实现,例如,通过增加对早期token的权重,或者重新设计一种机制,使得模型在处理长序列时不会忽略这些token。
改进位置编码:位置编码是Transformer模型中用于捕捉序列中token位置信息的关键组件。可以改进这个模块,例如,使用相对位置编码或可学习的动态位置编码,有助于模型更好地保持序列中各个token的独特性,从而减少表示崩溃的发生。
增加大模型深度和宽度:增加模型的深度和宽度可以提供更多的参数来学习复杂的表示,有助于模型更好地区分不同的输入序列。但是对AI算力的需求也非常大,不适合小型企业和个人开发者。
使用正则化:例如,使用权重衰减可以帮助模型避免过拟合,有助于减少表示崩溃现象。通过在训练过程中引入噪声或限制权重的大小,能抵抗输入序列的微小变化。
引入外部记忆组件:可以使用外部记忆组件,例如,差分记忆或指针网络,可以帮助模型存储和检索长序列中的信息。这种外部记忆可以作为模型内部表示的补充,提供一种机制来保持序列中关键信息的活跃度。
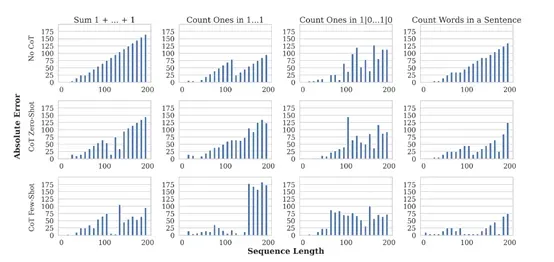
为了验证方法的有效性,研究人员在谷歌的Gemini 1.5和Gemma 7B大语言模型中行了综合评测。结果显示,改进注意力机制和引入外部记忆组件等方法,确实能有效缓解这两大难题。


