字节跳动的智能创作团队提出了一个从单一主题发展到多主题定制的通用框架UNO,从少到多的泛化:通过情境生成释放更多可控性。能够将不同的任务统一在一个模型下。在单主题和多主题驱动的生成中都能实现高度一致性,同时确保可控性。
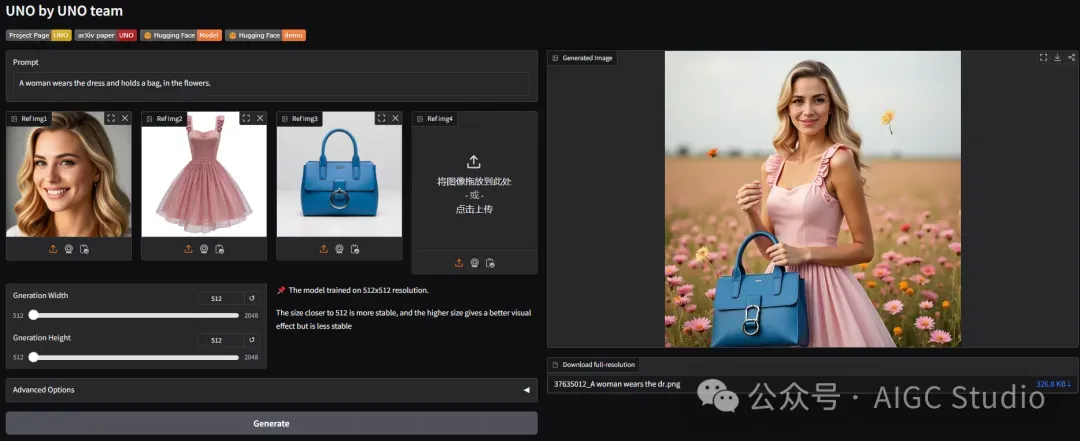
举一个例子:上传一张人物,一身衣服,一个包,UNO就可以生成这个人穿着衣服拿着包的效果图,效果看起来很真实!


相关链接
- 论文:https://arxiv.org/abs/2504.02160
- 主页:https://bytedance.github.io/UNO/
- 代码:https://github.com/bytedance/UNO
- ComfyUI:https://github.com/jax-explorer/ComfyUI-UNO
- 试用:https://huggingface.co/spaces/bytedance-research/UNO-FLUX
论文介绍

UNO从少到多的泛化:通过上下文生成释放更多可控性
尽管由于其广泛的应用,主题驱动生成已在图像生成中得到广泛探索,但它在数据可扩展性和主题扩展性方面仍然存在挑战。对于第一个挑战,从策划单主题数据集转向多主题数据集并对其进行扩展尤其困难。对于第二个挑战,大多数最新方法都集中在单主题生成上,这在处理多主题场景时很难应用。在本研究中,我们提出了一种高度一致的数据合成流程来应对这一挑战。该流程利用扩散变压器固有的上下文生成功能,生成高一致性的多主题配对数据。此外,我们引入了UNO,它由渐进式跨模态对齐和通用旋转位置嵌入组成。它是一个由文本到图像模型迭代训练而成的多图像条件主题到图像模型。大量实验表明,我们的方法可以在确保单主题和多主题驱动生成的可控性的同时实现高度的一致性。
它是如何工作的?
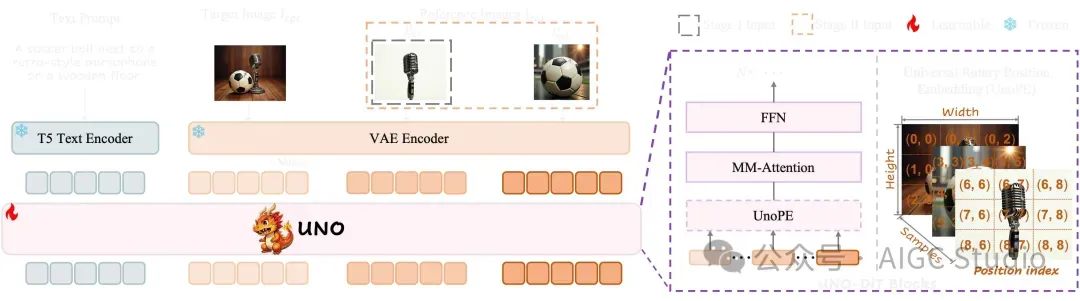 它为模型引入了两项关键增强功能:渐进式跨模态对齐和通用旋转位置嵌入(UnoPE)。渐进式跨模态对齐分为两个阶段。在第一阶段,我们使用单主体上下文生成的数据将预训练的T2I模型微调为S2I模型。在第二阶段,我们继续使用生成的多主体数据对进行训练。UnoPE可以有效地使UNO具备在缩放视觉主体控件时缓解属性混淆问题的能力。
它为模型引入了两项关键增强功能:渐进式跨模态对齐和通用旋转位置嵌入(UnoPE)。渐进式跨模态对齐分为两个阶段。在第一阶段,我们使用单主体上下文生成的数据将预训练的T2I模型微调为S2I模型。在第二阶段,我们继续使用生成的多主体数据对进行训练。UnoPE可以有效地使UNO具备在缩放视觉主体控件时缓解属性混淆问题的能力。
泛化能力

与最先进的方法的比较



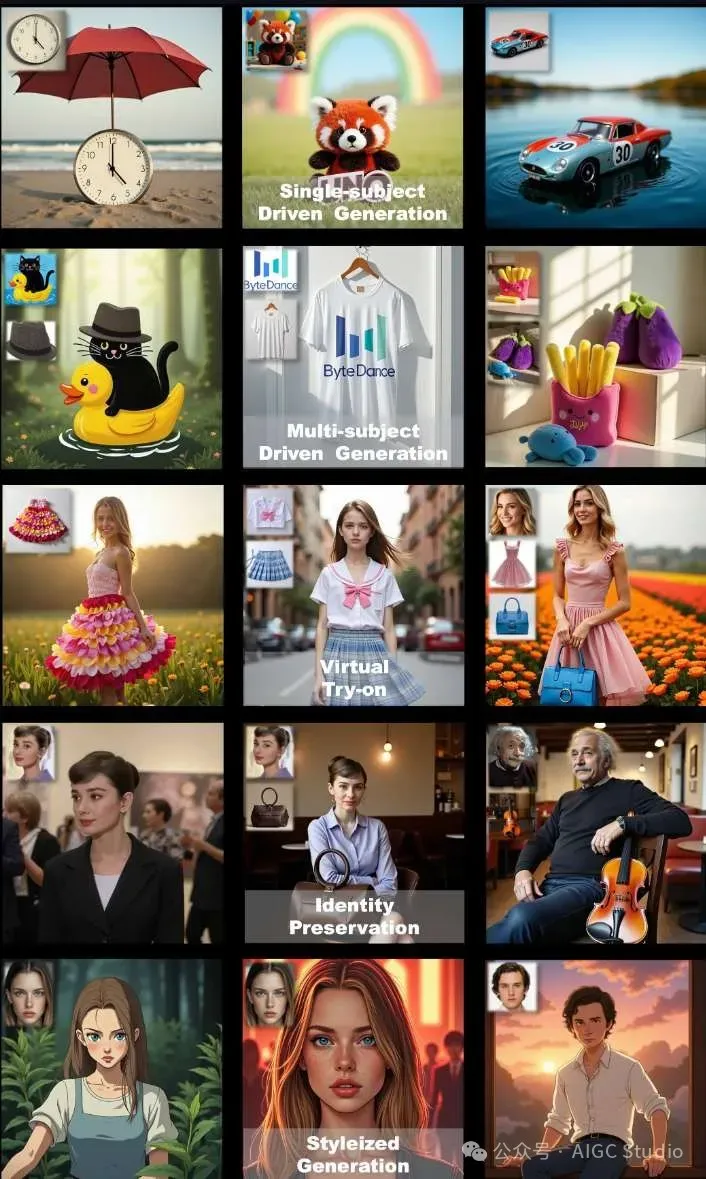
应用场景
结论
本文提出了一种通用定制架构 UNO,它能够解锁扩散变换器 (Diffusion Transformer) 的多条件上下文能力。这是通过渐进式跨模态对齐和通用旋转位置嵌入实现的。UNO 的训练分为两个步骤。第一步使用单幅图像输入来激发扩散变换器中的主体到图像能力。下一步是对多主体数据对进行进一步训练。我们提出的通用旋转位置嵌入也能显著提高主体相似度。此外还提出了一种渐进式合成流程,该流程从单主体生成演进到多主体上下文生成。该流程能够生成高质量的合成数据,有效减少复制粘贴现象。大量实验表明,UNO 在单主体和多主体定制中均实现了高质量的相似度和可控性。


