多模态大模型

神州云动CloudCC AI入选全球AI Agent图谱!汽车售后响应提速300%,企业级市场爆发式增长
企业级AI智能体(AI Agent)赛道迎来高速增长拐点。 据最新发布的《2025年Q3全球企业级AI Agent优秀厂商图谱》,神州云动(CloudCC)凭借其多模态大模型融合平台成功入选,成为国内少数跻身国际视野的AI Agent解决方案商。 数据显示,2025年前三季度,中国企业级AI Agent市场规模达186亿元,同比激增220%,标志着该技术已从概念验证迈入多行业规模化价值落地阶段。

多模态大模型最新评测出炉!Gemini-3-Pro断层第一,豆包、商汤领跑国产阵营,Qwen3-VL成首个开源高分模型
全球多模态大模型竞争格局再更新。 近日,权威评测平台SuperCLUE-VLM发布2025年12月多模态视觉语言模型综合榜单,谷歌Gemini-3-Pro以83.64分断层领先,展现其在视觉理解与推理领域的压倒性优势。 字节跳动豆包大模型以73.15分强势跻身前三,商汤科技SenseNova V6.5Pro以75.35分位列第二,国产大模型整体表现亮眼,彰显中国AI在多模态赛道的快速追赶能力。

Jan团队发布Jan-v2-VL-Max!30B多模态模型专攻长周期Agent任务,长序列执行稳超Gemini 2.5 Pro
在AI智能体(Agent)向复杂、多步任务演进的关键阶段,开源社区迎来一员新锐猛将。 Jan团队今日正式发布 Jan-v2-VL-Max——一款300亿参数的多模态大模型,专为长周期、高稳定性自动化执行场景打造,在关键指标上已超越谷歌Gemini2.5Pro与DeepSeek R1,为开源Agent生态注入强劲动力。 聚焦“误差累积”难题,专治多步执行“失焦”当前多模态Agent在执行长序列操作(如自动化UI操作、跨应用任务流)时,常因中间步骤微小偏差导致后续任务全面偏离,即“误差累积”问题。
长跑型 AI 登场:Jan 团队发布 Jan-v2-VL,深度优化多步任务执行力
开源 AI 项目 Jan 团队近日正式推出了全新的多模态大模型 Jan-v2-VL-Max。 这款拥有30B 参数的模型并非盲目追求通用性,而是精准锁定在“长周期执行任务”这一核心痛点上,旨在解决 AI 在复杂自动化流程中容易“断片”的问题。 该模型的技术底座源自 Qwen3-VL-30B-A3B-Thinking。

前字节视觉大模型 AI 平台负责人潘欣加盟美团 出任多模态AI创新业务负责人
前字节跳动视觉大模型AI平台负责人潘欣已于本周到岗,出任多模态AI创新业务负责人,直接向美团技术委员会汇报。 至此,这家市值千亿港元的生活服务巨头在 2025 年“外卖+AI”战略中补齐了最核心的一块算法拼图。 潘欣的履历横跨中美顶尖研发体系:在Google Brain期间,他主导TensorFlow动态图模块,奠定全球主流深度学习框架的灵活训练范式;回国后相继任职百度、腾讯、字节跳动,负责PaddlePaddle性能优化、无量框架建设及视觉大模型平台, 2024 年 11 月又以AI合伙人身份加盟闪极科技,推动智能眼镜量产。

智谱开源 GLM-4.6V 系列:106B 原生支持 Function Call,轻量版 9B 免费商用
智谱正式并上线开源 GLM-4.6V 多模态大模型系列,含基础版 GLM-4.6V(总参106B,激活12B)与轻量版 GLM-4.6V-Flash(9B)。 新模型将上下文窗口提升至128k tokens,视觉理解精度达同参数 SOTA,首次把 Function Call 能力原生融入视觉模型,打通「视觉感知 → 可执行行动」完整链路。 API 价格较 GLM-4.5V 下降50%,输入1元 / 百万 tokens、输出3元 / 百万 tokens;GLM-4.6V-Flash 完全免费,已集成 GLM Coding Plan 与专用 MCP 工具,开发者可零成本商用。

巨量引擎亮出AI治理“利剑”:自研多模态大模型10分钟审90%广告,单季拦截84万违规素材
当AI生成内容席卷广告行业,虚假宣传、违规素材和恶意诱导也悄然滋生。 面对这场由技术催生的新风险,巨量引擎选择用更强大的AI来守护秩序。 近日,其首次公开自研的AI广告治理大模型,以“全链路治理”为框架、“以AI治AI”为核心策略,为数字广告生态筑起一道智能防线。

生数科技完成新一轮数亿元规模A轮融资
2025年9月19日,生数科技宣布完成新一轮数亿元人民币规模的A轮融资,此次融资由博华资本领投,百度战投、北京市人工智能产业投资基金、启明创投、达泰资本、BV百度风投等老股东持续跟投,同时建发新兴投资等产业合作方也加码跟投。 生数科技自2023年成立以来,凭借其强大的核心团队,该团队由来自清华大学、北京大学、帝国理工学院、卡耐基梅隆大学等全球顶尖高校的技术人才以及产业界的产品研发和产业服务人才组成,展现出深厚的产业实践经验和全球化技术落地能力。 生数科技专注于多模态大模型及应用的自主研发,其核心产品Vidu具备AI图像生成、视频生成与音频生成等多项能力,广泛应用于互联网、广告、电商、动漫、文旅、广电、教育、游戏及影视等多个行业领域。

商汤「日日新V6.5」登顶OpenCompass全球多模态大模型榜单
根据权威评测平台OpenCompass多模态大模型学术榜单(Multi-modal Academic Leaderboard)最新数据显示,商汤「日日新 V6.5」(SenseNova-V6.5 Pro)多模态大模型以82.2的综合成绩登顶榜首,领先Gemini 2.5 Pro以及GPT-5等国际顶尖模型。 这一佳绩不仅意味着商汤「日日新 V6.5」成为全球最强多模态大模型之一,同时也是商汤在“多模态通用智能”技术战略下的成果印证。 商汤科技联合创始人、执行董事、首席科学家林达华在《迈向多模态通用智能:商汤的思考》中指出,智能的核心是与外界进行自主交互的能力,多模态信息感知与处理的能力是AGI的核心要求,使AI能像人类一样,通过视觉、听觉等多种感官接收并融合信息,实现更深层次的理解与推理,是迈向AGI的必由之路。

VLDB2025 | Magnus: 字节跳动面向大规模机器学习的数据管理方案
导读机器学习广泛应用于字节跳动,数据作为机器学习训练的核心要素,如何高效灵活的管理支撑大规模训练数据的存储、生产以及训练,成为数据基础设施的一大挑战;近两年大模型迅猛发展,对数据集管理也提出了更多新的场景需求。 字节跳动在开源 Apache Iceberg 的基础上,打造了一套面向大规模机器学习的数据管理解决方案 Magnus,在存储格式、索引、元数据管理、更新机制、训练框架集成等多个维度实现优化。 Magnus 已在字节内部部署超过五年,在搜索、广告、推荐、大模型等核心业务中大规模落地,数据规模超5EB,相关成果已被 VLDB 2025收录。
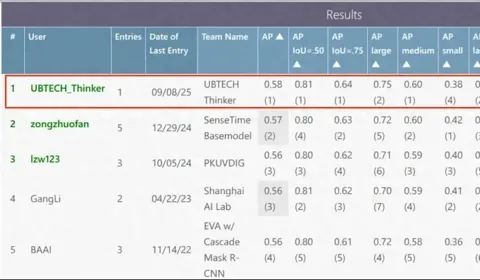
全球四项第一!优必选自研人形机器人最强大脑Thinker登顶全球
近日,优必选自主研发的人形机器人Walker最强大脑——百亿参数基座的多模态大模型:优必选Thinker,在机器人感知与规划领域三大国际权威基准测试——分别由微软、谷歌等发起与提出的MS COCO Detection Challenge、RoboVQA与Egoplan-bench2中,针对二十一个场景、四大类型的任务规划等命题,优必选一举斩获四项全球榜单第一。 榜单吸引了来自英伟达、北京智源研究院、上海AI Lab等全球顶尖团队,角逐激烈。 优必选这次取得的成绩不仅体现了其机器人在复杂环境感知、语义理解与长程任务规划方面的全方位技术领先性,也标志着人形机器人Walker S系列的“最强大脑”实现关键进化。

多模态大模型持续学习系列研究,综述+Benchmark+方法+Codebase一网打尽!
本系列工作核心作者: 郭海洋(自动化所博士生)、 朱飞 (中科院香港院AI中心AP)、 曾繁虎 (自动化所硕士生)、 刘文卓 (自动化所博士生)、 赵宏博 (自动化所博士生)。 通讯作者为自动化所博士生导师张煦尧研究员和刘成林研究员。 团队长期从事人工智能研究,成果发表于 CVPR、ICCV、NeurIPS、ICLR、ACL、TPAMI、IJCV 等国际顶级会议与期刊。

DeepSeek、GPT-5都在尝试的快慢思考切换,有了更智能版本,还是多模态
本研究由腾讯混元和中科院自动化所联合研发,团队成员包括 Jie Jiang, Qi Yang, Bolin Ni, Shiming Xiang, Han Hu, Houwen Peng背景:多模态大模型的思考困境当前,业界顶尖的大模型正竞相挑战“过度思考”的难题,即无论问题简单与否,它们都采用 “always-on thinking” 的详细推理模式。 无论是像 DeepSeek-V3.1 这种依赖混合推理架构提供需用户“手动”介入的快慢思考切换,还是如 GPT-5 那样通过依赖庞大而高成本的“专家路由”机制提供的自适应思考切换。 它们距离真正意义上的“智能思考”仍有距离。

理想i8正式发布:首款纯电SUV,售价32.18万元起
7 月 29 日晚,理想汽车正式发布家庭六座纯电 SUV—— 理想 i8。 作为旗下首款纯电 SUV,理想 i8 价格定位在 32.18 万元 - 36.98 万元,并将于 8 月 20 日开启交付,目前已可以在全国零售门店试驾体验了。 理想 i8 的设计理念源于游艇,其延续了 MEGA 的前脸设计风格,尾部则与理想 L 系 SUV 类似,首发提供五款车身外观色,三款内饰配色,可选 20、21 英寸轮毂。

尖峰对话17分钟全记录:Hinton与周伯文的思想碰撞
7 月 26 日下午,人工智能教父 Geoffrey Hinton 与上海人工智能实验室主任、首席科学家周伯文教授开展了一场浓缩高密度智慧的尖峰对话,将 Hinton 的上海之行推向新高潮。 77 岁的 Geoffrey Hinton 第一次飞越重洋踏上了中国,当他步入会场时,全场起立鼓掌,观众们高举手机长达数分钟,直播画面中一度无法看到台上的嘉宾。 在 17 分钟的对话中,两位科学家谈及 AI 多模态大模型前沿、“主观体验” 和 “意识”、如何训练 “善良” 的超级智能、AI 与科学发现,以及给年轻科学家的建议。

复杂空间指令也能秒懂?RoboRefer 让机器人理解推理空间,开放世界也能精准行动!
本文的主要作者来自北京航空航天大学、北京大学和北京智源人工智能研究院。 本文的第一作者为北京航空航天大学硕士生周恩申,主要研究方向为具身智能和多模态大模型。 本文的共一作者兼项目负责人为北京智源研究院研究员迟程。

阿里Ovis-U1震撼发布:多模态AI三合一,开源赋能全球开发者
2025年6月29日,阿里巴巴国际AI团队正式发布了全新多模态大模型 **Ovis-U1**,标志着其在多模态人工智能领域的又一重大突破。 作为Ovis系列的最新力作,Ovis-U1将多模态理解、图像生成和图像编辑功能融为一体,展现了强大的跨模态处理能力,为开发者、研究者和行业应用提供了全新的可能性。 以下是AIbase对Ovis-U1的详细报道。

通义千问发布多模态统一理解与生成模型Qwen VLo
近日,Qwen VLo多模态大模型正式发布,该模型在图像内容理解与生成方面取得了显著进展,为用户带来了全新的视觉创作体验。 据介绍,Qwen VLo在继承原有Qwen-VL系列模型优势的基础上,进行了全面升级。 该模型不仅能够精准“看懂”世界,更能基于理解进行高质量的再创造,真正实现了从感知到生成的跨越。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
大语言模型
字节跳动
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉