近日,由清华大学、腾讯混元、斯坦福大学及卡耐基梅隆大学的研究团队联合发布了一项新评估基准 ——RBench-V,专门针对多模态大模型的视觉推理能力进行测试。该基准的推出,旨在填补当前评估体系中对模型视觉输出能力的空白,以便更全面地了解现有模型的性能。

RBench-V 基准测试包含803道题目,涉及多个领域,包括几何与图论、力学与电磁学、多目标识别和路径规划等。与以往只要求文字回答的评估不同,这次评测特别要求模型生成或修改图像内容,以支持推理过程。这意味着,模型不仅需要理解问题,还需要像人类一样,通过绘制辅助线或观察图形结构来进行思考。
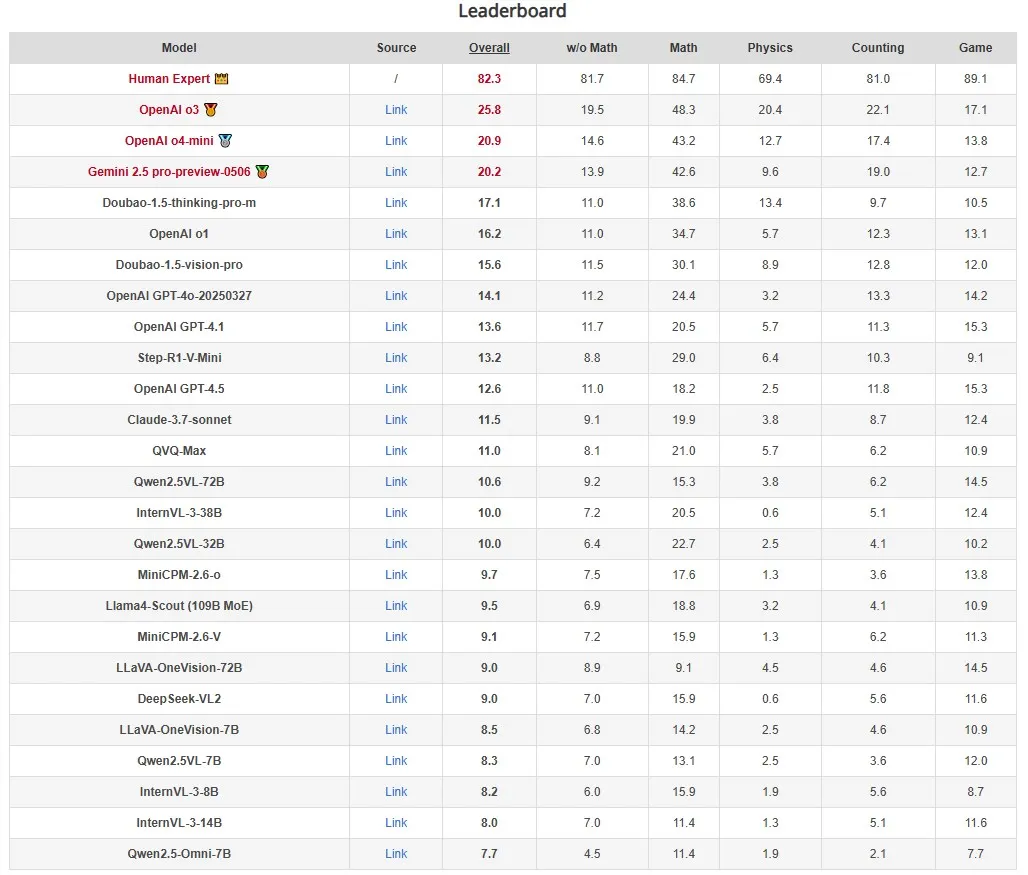
测试结果显示,即便是表现最好的 o3模型,在 RBench-V 上的准确率也仅为25.8%,远低于人类专家的82.3%。Google 的 Gemini2.5模型紧随其后,仅获得20.2% 的得分。更令人担忧的是,许多开源模型的准确率在8% 至10% 之间,甚至有些模型的表现接近随机作答。
RBench-V 的研究表明,当前的多模态大模型在处理复杂的几何问题时,往往采取了简化的策略。与人类通过直观的可视化方法进行思考不同,大部分模型更倾向于将图形问题抽象为代数表达,用文本推理代替真实的图像操作。这一现象反映出它们在深层理解图像信息上的不足。
研究团队指出,未来的模型需要在推理过程中主动生成图像,以帮助思考,才能真正实现 “类人智能”。他们提到,多模态思维链和智能体推理等新方法,可能是人工智能发展的一条重要路径。
如需了解更多信息,请访问项目主页: [RBench-V 项目主页](https://evalmodels.github.io/rbenchv/)。
划重点:
🔍 研究团队联合发布 RBench-V,评估多模态大模型的视觉推理能力。
📉 表现最好的 o3模型仅获25.8%,远低于人类82.3% 的准确率。
🧩 当前模型在处理视觉问题时缺乏深层理解,需改进推理方式以推动智能发展。


