
在实际业务场景中,知识库不会只有单一领域的知识,可能会存在多个领域的知识,如果对用户问题不提前做领域区分,在对基于距离的向量数据库进行检索时,可能会检索出很多与用户问题不属于同一个领域的文档片段,这样的上下文会存在较多的噪音或者不准确的信息,从而影响最终的回答效果。
另一方面知识库中涵盖的知识表达形式也是有限的,但用户的提问方式却是千人千面的,用户遣词造句的方式以及描述问题的角度可能会与向量数据库中存储的文档片段存在差异,这就可能导致用户问题和知识库之间不能很好匹配,从而降低检索效果。
为了解决此问题,我们可以对用户问题进行查询增强,比如对用户问题进行意图识别、同义改写、多视角分解以及补充上下文,通过这几个查询增强方式来更好地匹配知识库中的文档片段,提升检索效果和回答效果。
本文完整代码地址[1]:https://github.com/laixiangran/ai-learn/blob/main/src/app/rag/04_question_optimize/route.ts
现在我们准备两份文档《2024少儿编程教育行业发展趋势报告.pdf》、《2021年低代码行业研究报告.pdf》,将这两份文档同时存储到向量数据库中,同时我们在每个文档片段的元数据中加上 category 这个字段,用来标记每个片段所属的领域,作为后续的检索筛选条件。
代码实现如下:
复制const pdfs = [
{
path: 'src/app/data/2024少儿编程教育行业发展趋势报告.pdf',
category: '少儿编程',
},
{
path: 'src/app/data/2021年低代码行业研究报告.pdf',
category: '低代码',
},
];
for (const pdf of pdfs) {
const { path, category } = pdf;
const pdfContent = awaitloadPdf(path); // pdf 文件解析
const documents = awaitsplitDocuments(pdfContent); // 文档切分
for (constdocumentof documents) {
// 添加元数据
document.metadata.category = category; // 少儿编程 or 低代码
}
awaitaddDocuments(documents); // 保存文档到向量数据库
}到这里,我们的知识库就同时存在两个不同领域的文档,在不对问题进行任何优化的前提下,我们将该 RAG 系统版本定为 V2.0,现在我们先通过RAG系列(五):系统评估 - 基于LLM-as-judge实现评估系统这一篇文章实现的评估系统来对 V2.0 进行评估,得分如下:

可以看到,相对于 V1.0,五个指标得分都有不同程度的下降,主要的原因就是同样的问题在 V2.0 中会检索到不属于“少儿编程”领域的文档片段。比如用户问题 “少儿编程教育行业当前的发展动力主要来自哪些方面?”检索出了“低代码”相关的文档片段,从而影响了各个指标的得分:
复制"question": "少儿编程教育行业当前的发展动力主要来自哪些方面?", "retrievedContext": [ "低代码行业发展趋势-产品易用性提升路径\n基础能力\n易用性\n增加引擎和交付模块数量,提升整个集成引擎\n的组合方式,覆盖更多应用场景。\n⚫架构落地\n增加引擎和交付模块数量,提升整个集成引擎\n的组合方式,覆盖更多应用场景。\n⚫平台架构设计\n客户知道怎么设计才能发挥无代码、低代码平\n台的真正能力,现阶段国内对这方面认知逐渐\n提升。\n低\n代\n码\n/\n零\n代\n码\n产\n品\n落地能力\n使用能力", "低代码商业模式-前后端开发平台\n厂商角度\n•厂商角度:面向具有一定开发能力的专业人员,降低专业开发人员的使用门槛,减少对\n高级别研发人员的依赖,大大提升了开发效率和降低开发人员成本。\n软件开发商\n产品提供方\n低代码平台厂商\n微服务架构\n大多提供给一\n定开发能力的\n专业人员。\nDevOps\n控件、组件\n企业\n客户\n元数据管理\n......\n中台化能力", "•多鲸是多鲸资本旗下教育行业垂直内容平台,专注产业视角下的教育行\n业研究,依托对教育产业的深度认知,通过原创图文视频等媒体内容、\n链接一线教育从业者的线上线下活动,打造教育行业媒体影响力,与教\n育从业者同行,助力行业发展。\n扫\n\n描\n\n二\n\n维\n\n码\n\n关\n\n多\n\n鲸\n获\n\n取\n\n更\n\n多\n\n资\n\n讯" ],
本文将以 V2.0 作为基准版本,以此来验证对用户问题进行查询增强后的效果。
意图识别
意图识别是根据用户问题来识别问题所属的知识领域,这样可以缩小或者准确定位到需要检索哪个知识库,从而更精准地检索出相关的文档片段。比如,对于这样一个用户问题:“少儿编程教育行业当前的发展动力主要来自哪些方面?”,可以知道这个问题属于“少儿编程”这个知识领域,那么在检索的时候就要去检索与“少儿编程”相关的知识库,而不应该去检索其它知识库。
对用户问题的意图识别有很多方法,比如规则匹配、传统机器学习以及深度学习等等,这里先不做展开。
本文采用的方法是直接通过 LLM 来识别用户问题的意图,代码实现如下:
复制/**
* 问题优化 - 意图识别
* @param question 原始问题
* @returns
*/
async function intentRecognition(question) {
const prompt = `
你是一个语言专家,你的任务是分析下面的问题是属于哪个领域。
说明:
1. 无法判断时,默认为“少儿编程”;
2. 只需要回答领域名称,不要输出其他内容。
领域列表:
["少儿编程", "低代码"]
问题:
${question}
回答:
`;
const res = await generateModel.invoke(prompt);
const data = res.content;
console.log('intentRecognition: ', data);
return data;
}这里的意图对应的是每个文档片段的元数据的 category,这样我们就可以将 category 作为检索条件来查询对应领域的知识库:
复制// 意图识别
const intent = await intentRecognition(evaluateData.question);
// 检索条件
const vectorFilter = {
category: intent, // 将意图作为筛选条件
};
// 文档检索
const docs = await chromadb.similaritySearchWithScore(
question,
topK,
vectorFilter
);这样我们检索到的文档片段都是属于“少儿编程”领域,不会再有“低代码”的文档片段了。
复制"question": "少儿编程教育行业当前的发展动力主要来自哪些方面?", "retrievedContext": [ "•多鲸是多鲸资本旗下教育行业垂直内容平台,专注产业视角下的教育行\n业研究,依托对教育产业的深度认知,通过原创图文视频等媒体内容、\n链接一线教育从业者的线上线下活动,打造教育行业媒体影响力,与教\n育从业者同行,助力行业发展。\n扫\n\n描\n\n二\n\n维\n\n码\n\n关\n\n多\n\n鲸\n获\n\n取\n\n更\n\n多\n\n资\n\n讯", "的需求,具备快速成长和创造巨大价值的潜力。然而,曾经的从业逻辑,已不再适配当前大量新玩家涌入、市场\n竞争愈发激烈的全新格局。", "具保持同步。\n【多鲸资本创始合伙人/姚玉飞 】\n•未来教育的关注点,是培养个性鲜明、独立自强的大写的“人”。我们希望孩子们面对一个繁杂多样、极\n不确定的世界时,拥有高阶的分析判断力,能在给定条件下找到最优选择。作为世界公认的未来语言,编\n程已经成为打造孩子们面向未来的核心竞争力的重要方式。" ],
我们将版本定为 V3.0,评估得分如下:

可以看到,相对于 V2.0,通过对问题的意图识别实现知识库的精准检索,五个指标得分都恢复到 V1.0 的水平了。
接下来,我们在 V3.0 的基础上再进一步对问题进行优化。
同义改写
同义改写是通过将原始查询改写成相同语义下不同的表达方式,来解决用户查询单一的表达形式可能无法全面覆盖到知识库中多样化表达的知识。比如,对于这样一个用户问题:“少儿编程教育行业当前的发展动力主要来自哪些方面?”,可以改写成下面几种同义表达:1、“少儿编程教育行业的当前发展是由哪些因素推动的?”;2、“是什么力量在驱动着少儿编程教育行业目前的发展?”;3、“目前推动少儿编程教育行业发展的重要因素有哪些?”。每个改写后的问题都可独立用于检索相关文档片段,随后从这些不同问题中检索到的文档片段集合进行合并和去重处理,从而形成一个更大的相关文档集合。
本文采用的方法是直接通过 LLM 来对用户问题进行同义改写,代码实现如下:
复制/**
* 问题优化 - 同义改写
* @param question 原始问题
* @param num 同义改写后的同义问题数量
* @returns
*/
async function synonymyRewritten(question, num = 3) {
const prompt = `
你是一个语言专家,你的任务是将给定的原始问题改写成${num}个语义相同但表达方式不同的问题。
说明:
1. 严格按以下JSON格式返回:["问题1", "问题2", ...],不能输出其他无关内容。
原始问题:
${question}
回答:
`;
const res = await generateModel.invoke(prompt);
const data = formatToJson(res.content) || [];
console.log('synonymyRewritten: ', data);
return data;
}然后将原始问题和同义改写出来的问题同时用于检索,再将每个问题检索到的文档片段组合起来,根据文档 id 去重并按文档片段相似度升序排列,最终取 topK(此时是 3) 个文档片段作为最终的上下文,代码实现如下:
复制const allQuestions = [evaluateData.question];
// 同义改写的问题
allQuestions.push(...evaluateData.synonymyQuestions);
// 检索条件
const vectorFilter = {
category: evaluateData.category,
};
const allDocs = [];
while (allQuestions.length > 0) {
const question = allQuestions.shift();
const docs = await chromadb.similaritySearchWithScore(
question,
topK,
vectorFilter
);
allDocs.push(...docs);
}
// 根据文档 id 去重并按文档相似度升序排列,最终取 topK 个文档作为上下文
const uniqueDocs = Array.from(
newMap(allDocs.map((doc) => [doc[0].id, doc])).values()
);
uniqueDocs.sort((a, b) => a[1] - b[1]);
// 最终的上下文
const retrievedContext = uniqueDocs
.slice(0, topK)
.map((doc) => doc[0].pageContent);我们将版本定为 V4.0,评估得分如下:

可以看到,相对于 V3.0,似乎效果提升的并不明显,有的指标(上下文召回率、上下文相关性、答案正确性)得分反而下降了。
出现这个现象的主要原因是虽然我们通过同义改写的方式扩大了检索文档片段集合,但由于我们只是简单做了去重和根据相似度排序,在 topK 不变的情况下,最终的上下文会有一些与同义问题相似度高但与原问题相似度低的文档片段,从而影响部分指标的下降。
解决这个问题的方法有很多,可以直接增大 topK,也可以通过重排序模型进行重排和筛选,这块后面会单独详细介绍,这里先不做展开。
本文先直接增大 topK,将 topK 设置为 6,我们将版本定为 V4.1,评估得分如下:
此时我们可以看到,相对于 V3.0,除了上下文相关性得分下降了(因为检索文档片段多了,就可能会包含更多与问题无关的文档片段),其他指标都有提升来,基本复合预期。
多视角分解
多视角分解采用分而治之的方法来处理复杂问题,将复杂问题分解为来自不同视角的子问题,以检索到问题相关的不同角度的文档片段。比如,对于这样一个问题:“少儿编程教育行业当前的发展动力主要来自哪些方面?”,可以从多个视角分解为:1、“推动少儿编程教育行业发展的重要因素有哪些?”;2、“目前支撑少儿编程教育市场的关键力量是什么?”;3、“少儿编程教育领域发展的主要驱动来源有哪些?”等子问题。每个子问题能检索到不同的相关文档片段,这些文档片段分别提供来自不同视角的信息。通过综合这些文档片段,LLM 能够生成一个更加全面和深入的最终答案。
本文采用的方法是直接通过 LLM 来对用户问题进行多视角分解,代码实现如下:
复制/**
* 问题优化 - 多视角分解
* @param question 原始问题
* @param num 多视角分解后的子问题数量
* @returns
*/
async function subRewritten(question, num = 3) {
const prompt = `
你是一个语言专家,你的任务是将给定的原始问题分解成${num}个不同视角的子问题。
说明:
1. 严格按以下JSON格式返回:["问题1", "问题2", ...],不能输出其他无关内容。
原始问题:
${question}
回答:
`;
const res = await generateModel.invoke(prompt);
const data = formatToJson(res.content) || [];
console.log('subRewritten: ', data);
return data;
}然后将原始问题和多视角分解出来的子问题同时用于检索,再将每个问题检索到的文档片段组合起来,根据文档 id 去重并按文档片段相似度升序排列,最终取 topK(此时是 3) 个文档片段作为最终的上下文,代码实现如下:
复制const allQuestions = [evaluateData.question];
// 多视角分解
allQuestions.push(...evaluateData.subQuestions);
// 检索条件
const vectorFilter = {
category: evaluateData.category,
};
const allDocs = [];
while (allQuestions.length > 0) {
const question = allQuestions.shift();
const docs = await chromadb.similaritySearchWithScore(
question,
topK,
vectorFilter
);
allDocs.push(...docs);
}
// 根据文档 id 去重并按文档相似度升序排列,最终取 topK 个文档作为上下文
const uniqueDocs = Array.from(
newMap(allDocs.map((doc) => [doc[0].id, doc])).values()
);
uniqueDocs.sort((a, b) => a[1] - b[1]);
// 最终的上下文
const retrievedContext = uniqueDocs
.slice(0, topK)
.map((doc) => doc[0].pageContent);我们将版本定为 V5.0,评估得分如下:
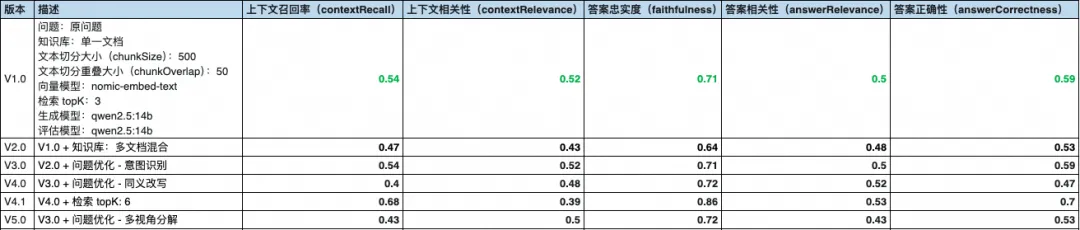
这里的问题情况和解决方案与同义改写的情况类似,这里就不重复讲解了。
补充上下文
补充上下文旨在通过生成与原始问题相关的上下文信息,从而丰富查询内容,提高检索的准确性和全面性。比如,对于这样一个问题:“少儿编程教育行业当前的发展动力主要来自哪些方面?”,可以生成如下上下文信息:“少儿编程教育行业的快速发展得益于政策支持、家长对孩子未来竞争力的重视以及技术进步和市场需求的增长”。这些生成的上下文信息可以作为原始问题的补充信息,提供更多的上下文内容,从而提高检索结果的相关性和丰富性。
本文采用的方法是直接通过 LLM 来根据用户问题生成补充的上下文,代码实现如下:
复制/**
* 问题优化 - 补充上下文
* @param question 原始问题
* @param maxLen 补充上下文的最大字符长度
* @returns
*/
async function contextSupplement(question, maxLen = 200) {
const prompt = `
你是一个语言专家,你的任务是根据给定的原始问题,生成一段与原始问题相关的背景信息。
说明:
1. 背景信息最大不超过${maxLen}个字符;
2. 只要输出背景信息,不能输出其他无关内容。
原始问题:
${question}
回答:
`;
const res = await generateModel.invoke(prompt);
const data = res.content;
console.log('supplementContext: ', data);
return data;
}然后将原始问题和生成的补充上下文同时用于检索,再将每个问题检索到的文档片段组合起来,根据文档 id 去重并按文档片段相似度升序排列,最终取 topK(此时是 3) 个文档片段作为最终的上下文,代码实现如下:
复制const allQuestions = [evaluateData.question];
// 补充上下文
allQuestions.push(evaluateData.supplementaryContext);
// 检索条件
const vectorFilter = {
category: evaluateData.category,
};
const allDocs = [];
while (allQuestions.length > 0) {
const question = allQuestions.shift();
const docs = await chromadb.similaritySearchWithScore(
question,
topK,
vectorFilter
);
allDocs.push(...docs);
}
// 根据文档 id 去重并按文档相似度升序排列,最终取 topK 个文档作为上下文
const uniqueDocs = Array.from(
newMap(allDocs.map((doc) => [doc[0].id, doc])).values()
);
uniqueDocs.sort((a, b) => a[1] - b[1]);
// 最终的上下文
const retrievedContext = uniqueDocs
.slice(0, topK)
.map((doc) => doc[0].pageContent);我们将版本定为 V6.0,评估得分如下:
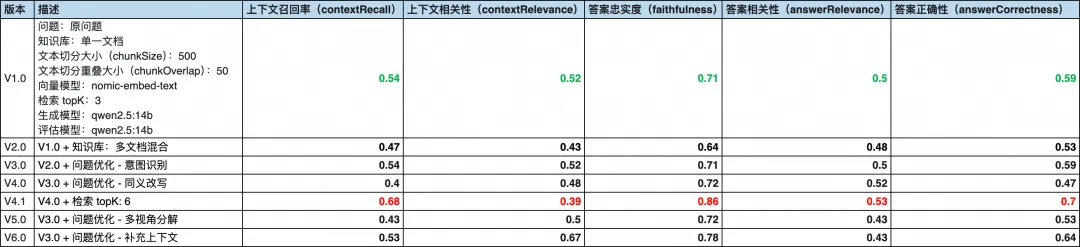
这里的问题情况和解决方案与同义改写的情况类似,这里就不重复讲解了。
结语
通过本文的研究与实践,我们系统验证了在多领域知识库场景下,通过意图识别、同义改写、多视角分解和补充上下文等查询增强技术对 RAG 系统性能的提升作用。通过实践验证,意图识别通过领域过滤可有效减少跨领域噪音,而后续的语义优化策略进一步解决了表达差异问题,使系统在准确率、相关性和完整性等关键指标有一定程度的提升。
当然我们也看到了,仅仅通过问题优化还不够,要想进一步提升 RAG 系统各个指标的表现,还需要通过更多的优化,比如切分优化、检索优化等等,这些后续都会一一讲解,敬请期待。
引用链接
[1] 本文完整代码地址: https://github.com/laixiangran/ai-learn/blob/main/src/app/rag/04_question_optimize/route.ts


