
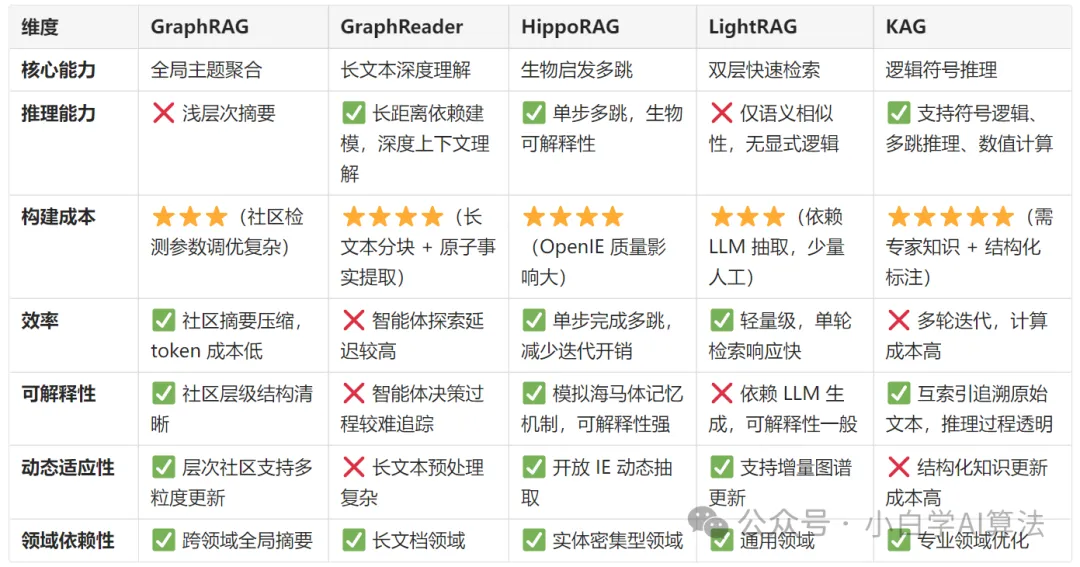
在自然语言处理领域,检索增强生成(RAG)技术通过结合外部知识库与语言模型,显著提升了模型在知识密集型任务中的表现。近年来,基于图结构的 RAG 方法成为研究热点,通过引入知识图谱的实体关系建模能力,有效解决了传统 RAG 在多跳推理、长文本理解和全局语义捕捉中的局限性。本文详细分析五种代表性方法:GraphRAG、GraphReader、LightRAG、HippoRAG和KAG ,从实现细节、优缺点及适用场景展开对比。
1、GraphRAG
微软提出GraphRAG, 通过 “从局部到全局” 的层次抽象,填补了传统 RAG 在宏观语义理解中的空白,尤其适合需要 “鸟瞰式” 知识整合的场景。
项目地址:https://github.com/microsoft/graphrag
论文地址:https://arxiv.org/pdf/2404.16130
方法介绍
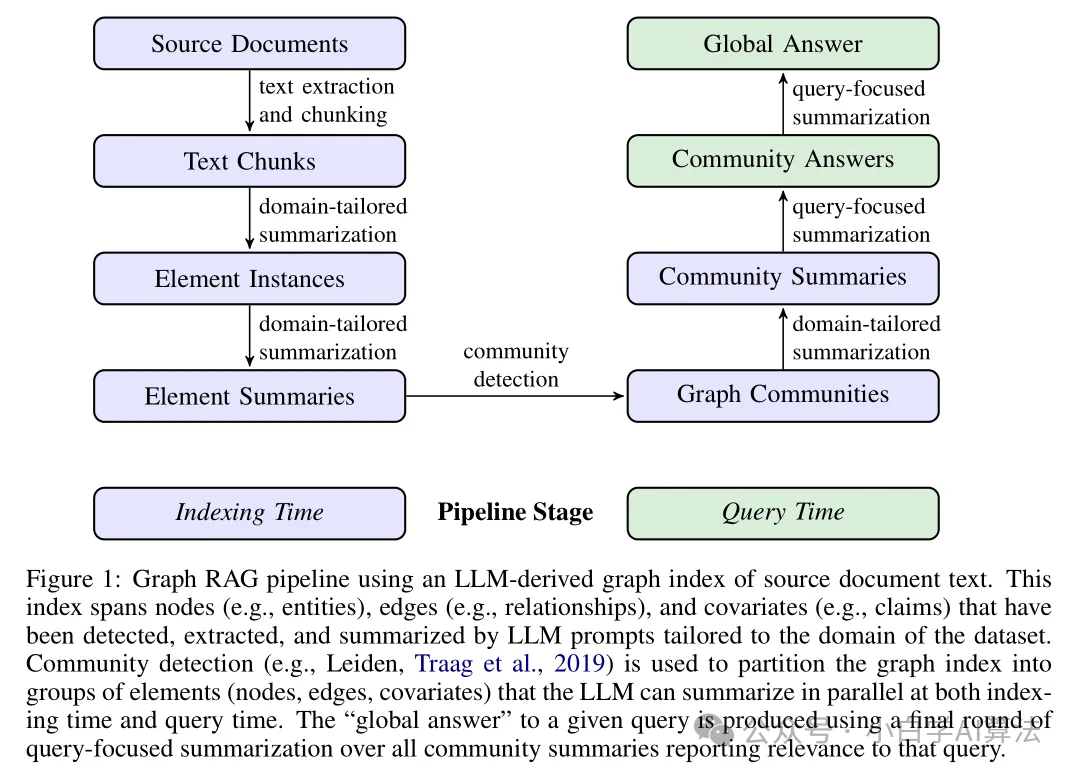
GraphRAG 的目标是通过层次化图结构实现对大规模文本的全局理解,其核心流程分为索引构建阶段(离线)和查询响应阶段(在线),具体如下:
索引构建阶段:先将源文档分割为带重叠的文本块,利用 LLM 提取实体、关系和协变量,构建无模式知识图;再通过 Leiden 算法对图进行多层社区划分,形成 “主题→子主题→具体实体” 的层次结构,最后自底向上生成各层社区摘要,低层聚焦细节,高层整合主题共性,压缩文本量以提升检索效率。
查询响应阶段:解析查询提取关键词,匹配包含相关关键词的社区,将社区摘要分块后利用 LLM 并行生成中间答案,按评分合并生成最终全局答案,必要时可递归调用低层社区检索补充细节。
优点
全局理解能力强:层次社区结构支持从局部到全局的多粒度摘要,适合宏观问题(如 “数据集主要主题”)。
高效摘要生成:社区摘要可并行处理,减少上下文 token 消耗(如根级摘要仅需原始文本 1% 的 token)。
领域无关性:通用图构建流程,适用于多种文本类型(如新闻、播客、学术文献)。
缺点
细节丢失风险:高层社区摘要可能忽略关键细节,影响答案准确性。
调参复杂:社区层级选择和块大小需根据数据集优化,缺乏通用策略。
适用场景
大规模文本摘要:如企业知识库全局检索、行业报告趋势分析。
需要多粒度回答的场景:如教育领域跨章节知识点总结、市场调研多数据源整合。
2、GraphReader
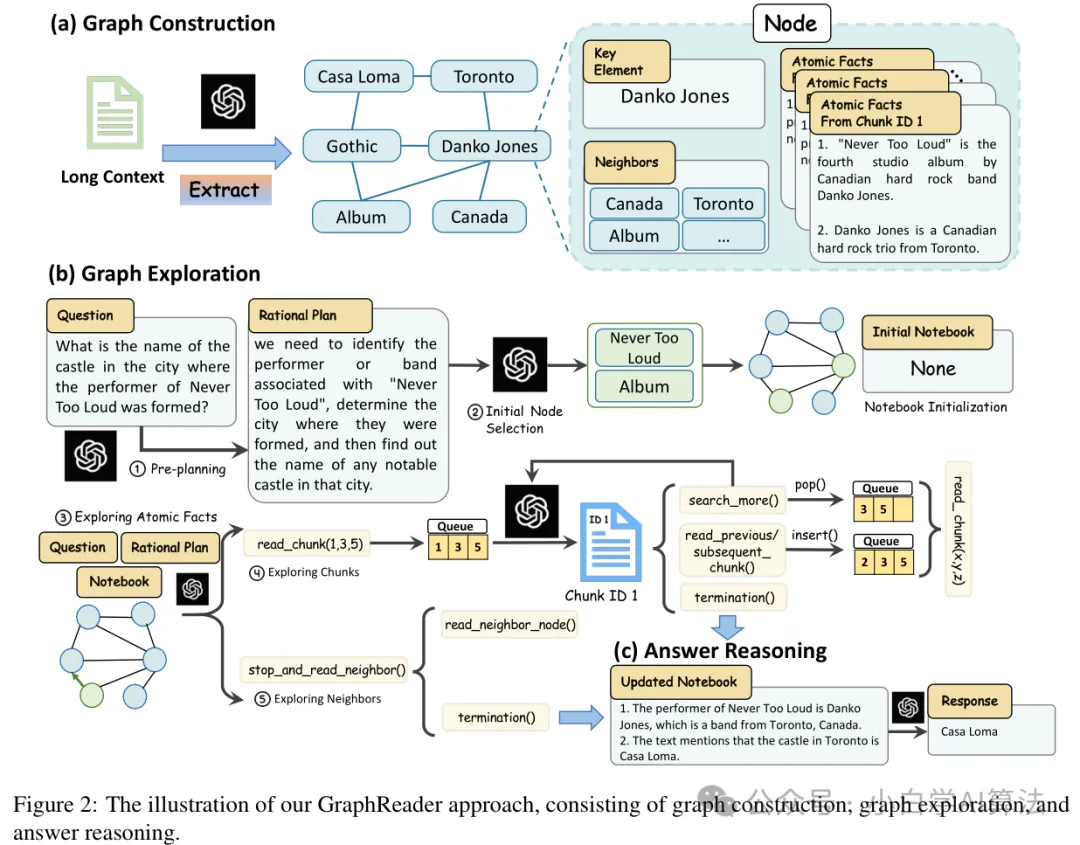
阿里,上海AI Lab等,针对长上下文、复杂关系问题,提出GraphReader,通过构建基于图的智能体系统(Graph-based Agent System),以结构化的方式组织长文本,并利用智能体自主探索该图。概述如图所示:
论文地址:https://arxiv.org/abs/2406.14550
方法介绍
GraphReader 的算法实现围绕图构建、图探索和答案推理三个阶段展开:
在图构建阶段,先将长文档按段落分割成适配 LLM 的文本块,再借助 LLM 从文本块中抽取原子事实和关键元素,最后对关键元素标准化处理,构建节点并建立节点间的链接,形成完整图结构。
图探索阶段,智能体拿到问题和图后,先初始化笔记本,拆解问题制定计划并选择初始节点;接着依次对原子事实、文本块和相邻节点进行探索,在探索过程中通过不同操作函数,判断并记录有价值的信息,直至收集到足够回答问题的内容。
答案推理阶段,智能体完成图探索后,将笔记本中记录的信息进行编译,运用思维链推理方式,生成最终答案。
优点
长文本处理能力强:通过图结构压缩长文本信息,缓解 LLM 上下文窗口限制。
自主推理灵活性:智能体可动态调整探索路径,适应不同复杂度的查询。
高召回率:原子事实和块遍历机制确保关键信息不遗漏,支持多跳推理。
缺点
计算成本高:智能体多轮探索和图遍历增加延迟,实时性较差。
初始化依赖人工:合理计划和节点选择需要领域知识引导,自动化程度较低。
适用场景
超长文档分析:如法律卷宗审阅、科学论文综述生成。
需要深度上下文理解的场景:如历史文献跨段落事件关联、技术文档故障排查。
3、HippoRAG
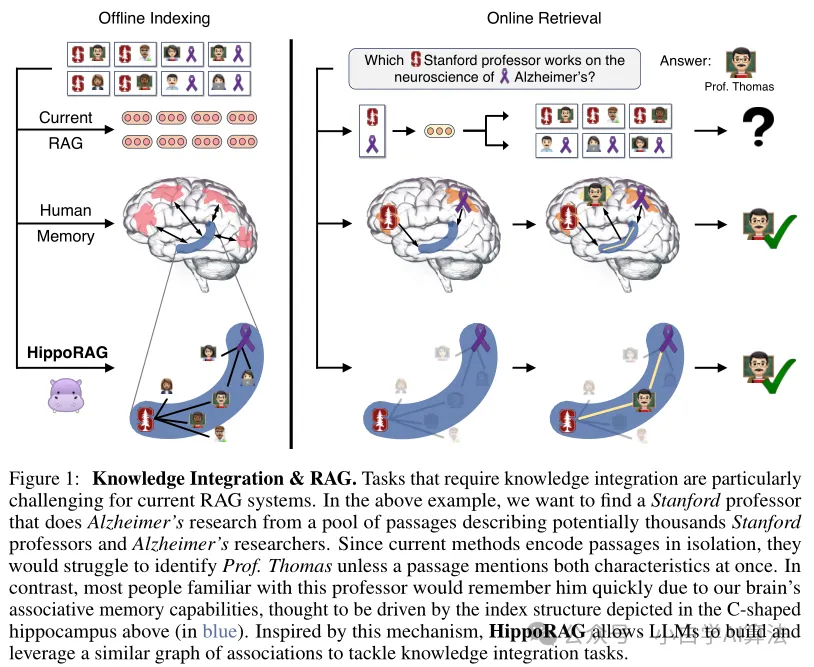
HippoRAG 是一种受神经生物学启发的检索增强生成模型,概述如图所示:
论文地址:https://arxiv.org/abs/2405.14831
项目地址:https://github.com/OSU-NLP-Group/HippoRAG
实现细节
神经生物学启发的知识表示:HippoRAG 模拟人类海马体的记忆机制,通过 “模式分离” 和 “模式完成” 两个核心操作实现知识整合。在索引构建阶段,模型使用开放信息抽取(OpenIE)技术从文本中提取实体、关系和属性,构建无模式知识图谱(Graph)。图中的节点表示实体,边表示关系,并通过同义词边连接语义相似的实体,提升图的连通性。例如,“苹果公司” 和 “Apple Inc.” 通过同义词边关联,增强实体链接能力。
单步多跳检索机制:针对传统 RAG 多轮检索的低效问题,HippoRAG 提出基于个性化 PageRank(PPR)的单步多跳检索算法。当接收到查询时,模型首先使用 LLM 提取查询中的命名实体作为种子节点,然后通过 PPR 算法在知识图谱上传播概率,一次性召回与查询相关的多跳实体。例如,查询 “苹果公司创始人的教育背景” 可直接召回 “Steve Jobs” 及其毕业院校 “Reed College”,避免了传统方法的多次迭代检索。
混合检索与答案生成:HippoRAG 采用向量检索与图检索相结合的策略:向量检索(如 ColBERTv2)负责召回相关文本块,图检索负责捕捉实体间的结构化关系。模型将两种检索结果融合后,通过 LLM 生成最终答案。为提升答案的可靠性,HippoRAG 引入证据评分机制,对召回的文本块和图路径进行置信度评估,优先选择高可信度的信息作为答案依据。
知识更新与遗忘机制:受海马体记忆巩固过程的启发,HippoRAG 设计了动态知识更新策略。当有新数据加入时,模型通过增量式图构建更新知识库,同时保留旧知识的历史版本。为避免知识库无限膨胀,模型引入 “遗忘” 机制,定期删除低价值或过时的知识,通过注意力机制评估知识的重要性,确保知识库的高效性和准确性。
优点
高效多跳检索:单步完成多跳推理,相比传统方法减少迭代次数,提升效率。
生物可解释性:模拟人类记忆机制,推理过程符合认知科学规律,可解释性较强。
缺点
依赖高质量图谱:OpenIE 提取三元组的准确性影响整体性能,噪声图谱会导致检索偏差。
复杂问题处理不足:缺乏逻辑规则支持,难以处理需要数值计算或层次推理的任务。
适用场景
实体关联清晰、逻辑推理需求较低的事实问答场景:如学术领域人物关系查询、历史事件因果分析。
需要快速多跳检索的场景:如金融欺诈关联分析、药物靶点相互作用预测。
4、LightRAG
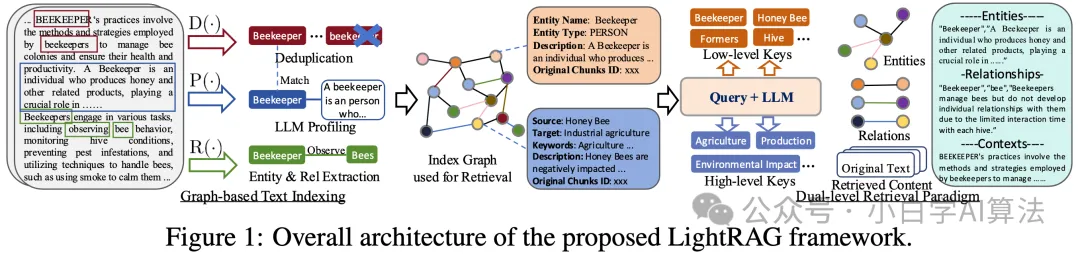
北邮、港大等提出LightRAG, 一种轻量级的检索增强生成模型,主要关注以下三个方面:全面的信息检索、高效低成本的检索、快速适应数据变化。
项目地址:https://github.com/HKUDS/LightRAG
论文地址:https://arxiv.org/abs/2410.05779
方法介绍
算法实现围绕基于图的文本索引、双层检索范式和检索增强答案生成三大核心模块展开。
在基于图的文本索引模块,LightRAG 先将文档分割成小块,利用 LLM 抽取实体与关系,构建知识图谱。通过去重、生成键值对优化图结构,并具备增量更新能力,可高效整合新文档,提升检索性能与信息理解深度。
双层检索范式是 LightRAG 的关键创新。低层次检索聚焦具体实体属性或关系,用于回答精确性问题;高层次检索则聚合多实体关系信息,处理抽象主题查询。通过提取本地与全局关键词,结合向量数据库匹配与子图邻近节点收集,实现了精准检索与全面信息整合。
在检索增强答案生成环节,LightRAG 将检索到的实体、关系描述及原始文本等信息拼接后输入通用 LLM,通过整合查询与多源文本,生成契合用户意图的答案,兼顾上下文连贯性与回答质量 。
优点
轻量级设计:无需复杂逻辑推理,通过双层检索平衡细节与全局理解,检索效率高。
动态适应性强:支持增量更新知识库,适合实时数据场景(如新闻摘要、动态赛事分析)。
低成本部署:相比 KAG,减少了符号推理模块,更易在资源受限环境中部署。
缺点
推理能力有限:依赖语义相似性,缺乏显式逻辑规则,难以处理深层推理任务。
长文本处理不足:未显式建模段落间依赖关系,复杂多跳问题中召回率较低。
适用场景
快速响应型问答:如智能客服、实时资讯检索、跨领域概况总结。
需要动态更新知识的场景:如电商产品推荐、社交媒体热点分析。
5、KAG
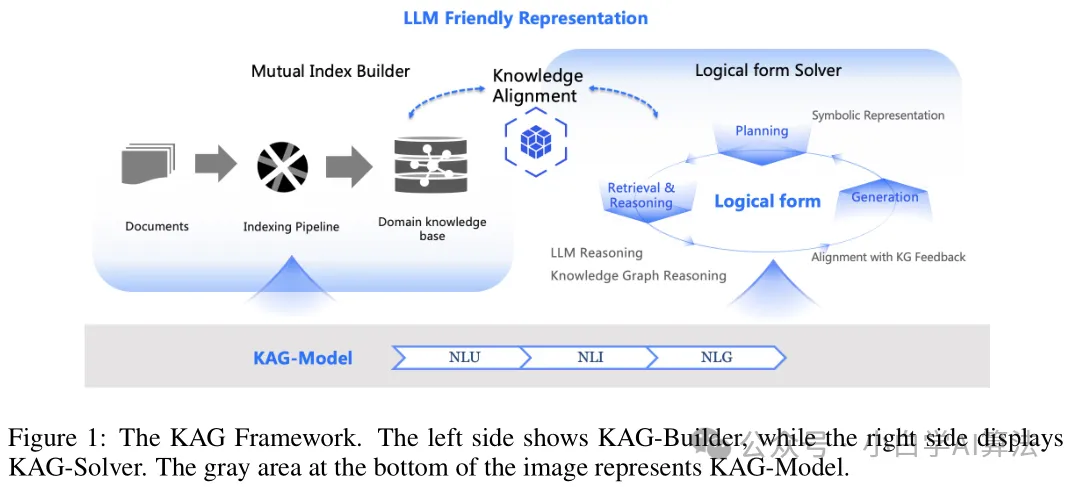
蚂蚁集团提出KAG(Knowledge Augmented Generation),旨在解决传统语言模型及相关技术在知识处理与复杂问题求解方面存在的一系列难题。
项目地址:https://github.com/OpenSPG/KAG
论文地址:https://arxiv.org/abs/2409.13731
方法介绍
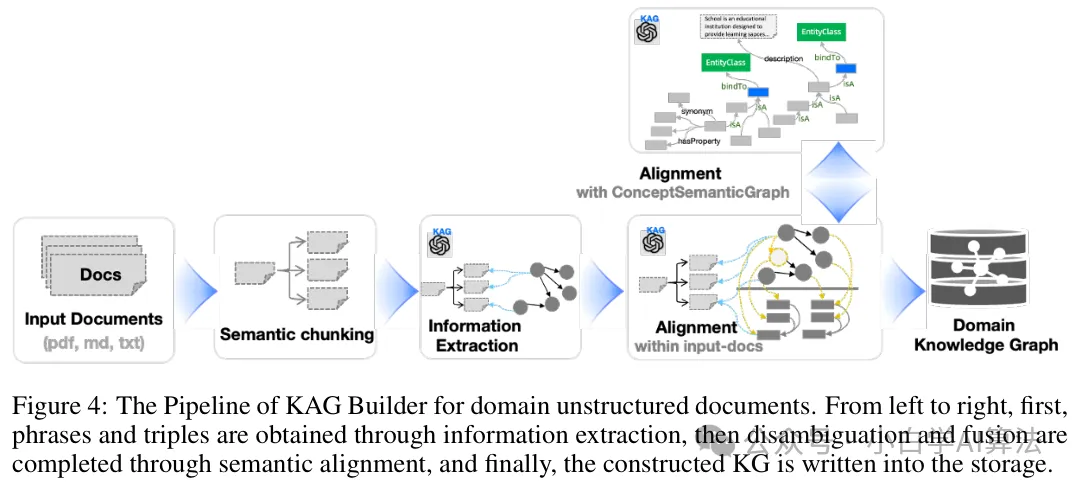
三层架构协同运作:KAG-Builder 利用 LLMFriSPG 框架构建离线索引,实现文本块与知识图谱的互索引,支持无模式信息抽取和结构化知识对齐;KAG-Solver 作为逻辑形式引导的混合推理引擎,整合规划、检索、推理算子,可进行符号推理与数值计算;KAG-Model 则增强 LLM 的自然语言理解、推理和生成能力,支持端到端推理。
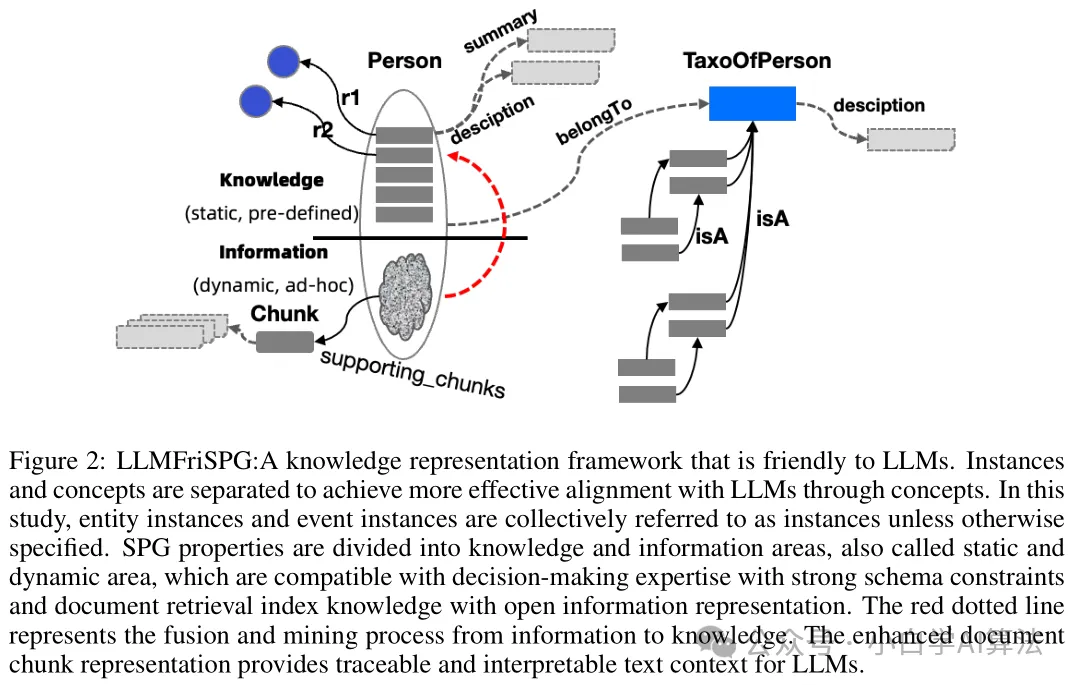
知识表示创新:LLMFriSPG 框架采用分层存储知识,包括 KGcs 层、KGfr 层、RC 层,支持动态属性和概念分层,解决信息损失问题;同时,通过图结构与原始文本块的双向互索引机制,有效提升检索准确性和可解释性。
逻辑推理求解:KAG 将自然语言问题拆解为逻辑表达式,借助 ReSP 反思机制等多轮迭代,逐步逼近答案,能够支持多跳推理和数值计算,实现复杂问题的深度推理。
优点
强推理能力:结合符号逻辑与文本检索,擅长处理需要多跳推理、逻辑计算的专业领域问题(如法律、医学)。
高可解释性:互索引机制保留原始文本上下文,推理过程可追溯。
领域适应性强:通过领域知识注入和模式约束,有效减少开放信息抽取的噪声。
缺点
构建成本高:需要专业知识构建结构化知识图谱,依赖大量标注数据和专家人力。
计算复杂度高:逻辑形式求解和多轮迭代增加推理延迟,对算力要求较高。
适用场景
专业领域复杂问答:如法律条文解析、医疗诊断推理、科学文献分析。
需要强逻辑推理、高准确性和可解释性的场景:如金融风控报告生成、政策合规性检查。
6、总结
对于一些场景的推荐算法及原因如下:
场景类型 | 推荐算法 | 核心原因 |
专业领域复杂推理 | KAG | 逻辑规则 + 领域知识注入,适合法律条文解析、医疗诊断等需要精确推理的场景 |
实时动态问答 | LightRAG | 双层检索响应快,支持增量更新,适合新闻热点、电商咨询等实时性要求高的场景 |
多跳实体关联分析 | HippoRAG | 单步 PPR 检索捕获实体间隐含关系,适合学术合作网络、社交关系挖掘等场景 |
超长文档深度理解 | GraphReader | 图探索 + 块遍历处理长距离依赖,适合法律卷宗审阅、技术文档故障排查等场景 |
跨领域全局摘要 | GraphRAG | 层次社区整合全局主题,适合企业知识库概览、行业趋势分析等需要宏观理解的场景 |
对于RAG方法的选择,整体来讲,还是要通过任务、成本等方面来综合考虑,没有能够通用一切场景的方法:
- 优先考虑任务性质:若需逻辑严谨性(如金融风控),选 KAG;若需快速响应(如客服),选 LightRAG。若问题涉及实体网络(如人物关系),选 HippoRAG;若处理超长文本(如合同),选 GraphReader;若需全局概览(如行业报告),选 GraphRAG。
- 平衡成本与效率:KAG 和 GraphReader 构建成本高,适合预算充足的企业级场景;LightRAG 和 HippoRAG 轻量级,适合中小团队快速落地。
- 结合领域数据特性:结构化数据多的领域(如医疗记录)适合 KAG;非结构化长文本(如用户评论)适合 GraphReader;实体密集型数据(如学术论文)适合 HippoRAG/GraphRAG。


