
在检索增强生成(RAG)技术席卷开放域问答(ODQA)领域的当下,多数研究者的目光都聚焦在检索算法优化与生成模型升级上,却忽略了一个关键环节 —— 文档分块。看似简单的分块过程,实则是决定 RAG 性能的 “隐形基石”:若分块缺乏上下文,检索到的信息碎片化;若分块包含过多无关内容,生成器又会被冗余信息干扰。今天要为大家介绍的 Logits-Guided Multi-Granular Chunker(LGMGC)框架,正是针对这一痛点提出的创新解决方案,让文档分块既 “懂语义” 又 “多粒度”,大幅提升抽取式问答效果。
01、为什么 RAG 分块需要 “重新被重视”?
在聊 LGMGC 之前,我们先搞清楚:为什么分块环节值得投入精力研究?
RAG 的 “短板” 藏在分块里
RAG 模型的工作流程可拆解为 “分块 - 检索 - 合成” 三步。前两步中,检索器负责从海量文档中找相关信息,合成器(LLM)负责基于检索结果生成答案。但如果分块环节出了问题,后续环节再优秀也难以发挥作用:
- 若分块过小(如单句分块),会丢失句子间的逻辑关联,比如描述 “某实验步骤” 的文本被拆分成多个孤立句子,检索器无法捕捉完整流程;
- 若分块过大(如整段分块),会混入大量与查询无关的内容,比如在 “AI 医疗诊断” 查询中,检索到的分块包含大量 AI 基础理论,反而干扰答案提取。
现有分块方法的 “两难困境”
目前主流的分块方法,始终面临 “语义连贯性” 与 “效率成本” 的两难:
- 传统分块(递归分块、语义分块):递归分块按固定长度切割文本,完全忽略语义;语义分块虽能通过句子嵌入距离识别分隔点,但难以确定 “最优分块粒度”,比如对学术论文和小说,最优分块长度差异极大,传统方法无法自适应。
- LLM 直接分块:近年来有研究用 GPT-4、Gemini-1.5 等大模型直接划分文本,虽能保证语义完整,但成本极高 —— 企业处理百万级文档时,频繁调用 LLM API 的费用难以承受;同时,将敏感文档上传至第三方 API,还会引发数据安全风险。
正是在这样的背景下,LGMGC 框架应运而生,它既借助 LLM 的语义理解能力,又规避了高成本与安全风险,还能实现多粒度分块,完美解决了现有方法的痛点。
02、LGMGC 框架:两大模块实现 “语义 + 多粒度” 分块
LGMGC 的核心思路是 “先找完整语义块,再拆多粒度子块”,整个框架由Logits-Guided Chunker(基于 Logits 的分块器) 和Multi-Granular Chunker(多粒度分块器) 两大模块组成,二者协同工作,兼顾语义完整性与检索灵活性。
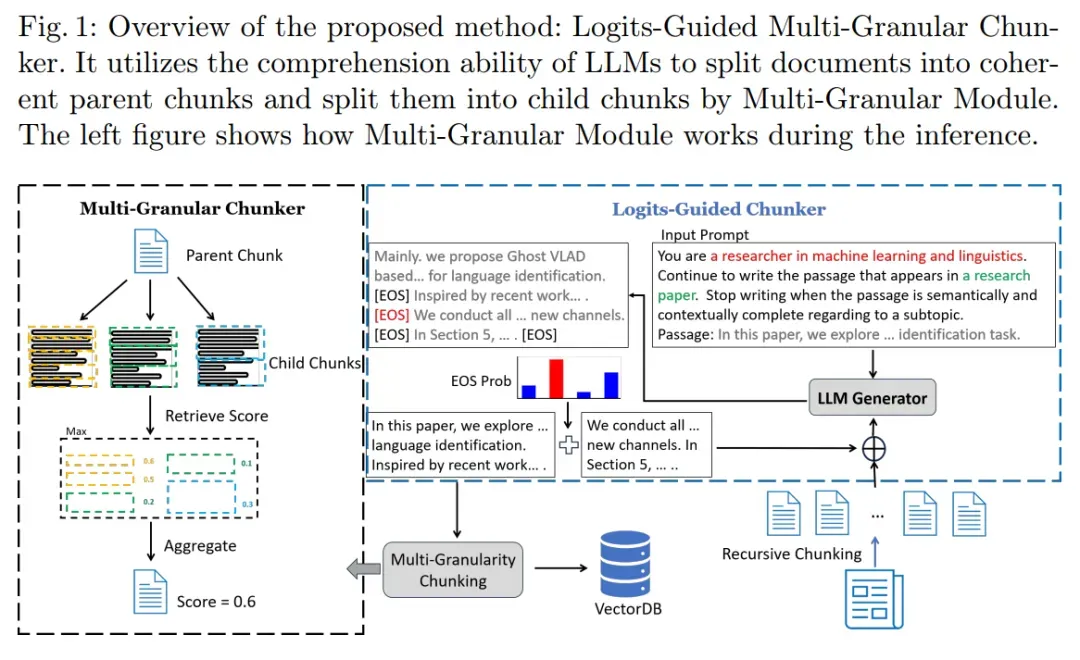
模块 1:Logits-Guided Chunker
该模块的核心是 “利用预训练 LLM 的 Logits 信息,识别文本中的完整语义单元”。简单来说,LLM 能预测每个 token 的后续概率分布,而句子结束标记([EOS])的概率,恰好能反映当前句子是否构成 “完整语义”。
具体实现分为 4 步,逻辑清晰且易于部署:
- 预处理:固定长度初分:先将输入文档按固定长度 θ(如 200/300/500 个单词)切割成初始块,避免文本过长导致 LLM 处理压力;
- 算概率:聚焦 [EOS] 标记:给每个初始块加一个提示(如 “请判断以下句子是否完整,若完整则输出 [EOS]”),然后让 LLM 计算每个句子末尾 [EOS] 标记的条件概率 p [EOS]—— 概率越高,说明该句子越完整,越适合作为语义边界;
- 定分割:选最高概率点:在初始块中,选择 p [EOS] 最高的位置作为分割点,分割点之前的文本即为 “语义完整的父块”,剩余内容则与下一个初始块拼接,进入下一轮迭代;
- 迭代:直到满足阈值:重复上述步骤,直到剩余文本长度低于设定阈值,最终得到一系列 “上下文连贯、语义独立” 的父块。
这里有个关键优势:该模块仅需 LLM 的一次前向传播(即输出 Logits 信息),无需让 LLM 生成完整文本,因此可使用本地部署的量化 LLM(如 8 位量化的 Llama3-8b),既降低了成本,又避免了数据外传,完美适配企业场景。
模块 2:Multi-Granular Chunker
检索和生成对分块粒度的需求完全不同:
- 检索阶段:需要小粒度块 —— 块越小,包含无关信息的概率越低,检索精度越高;
- 生成阶段:需要大粒度块 —— 块越大,包含的上下文越丰富,生成的答案越全面。
Multi-Granular Chunker 模块的核心就是 “解耦“检索” 与 “生成” 的粒度需求”,在父块基础上拆分出多粒度子块,具体操作如下:
- 父块打底:以 Logits-Guided Chunker 生成的 “语义完整父块” 为基础,确保子块的语义根源是完整的;
- 子块拆分:将每个父块按 “θ/2” 和 “θ/4” 的长度拆分成两个粒度的子块(比如父块是 400 个单词,子块就是 200 个和 100 个单词);
- 相似度联动:推理时,父块的相似度得分由其子块的 “最高得分” 决定 —— 比如检索 “某实验的结论” 时,先计算所有子块与查询的相似度,取最高分作为对应父块的得分;
- 选块生成:最终选择得分前 k 的父块传给 LLM 生成器,既保证了检索精度(子块筛选),又提供了完整上下文(父块生成)。
整体流程:1+1>2 的协同效果
LGMGC 的整体流程可总结为 “两步走”:
- 第一步:生成父块:用 Logits-Guided Chunker 将文档分割成语义完整的父块,解决 “语义连贯性” 问题;
- 第二步:拆分多粒度子块:用 Multi-Granular Chunker 将父块拆分成不同粒度的子块,解决 “检索 - 生成粒度不匹配” 问题。
通过这种 “先整后分” 的逻辑,LGMGC 实现了 “1+1>2” 的效果:父块保证了语义不破碎,子块保证了检索够精准,二者结合让后续的 RAG 流程效率大幅提升。
03、实验验证
为了验证 LGMGC 的效果,研究者在段落检索和开放域问答两大任务中进行了对比实验,选用了多个权威数据集和基线方法,结果证明 LGMGC 在所有指标上均表现最优。
实验设置
数据集:
- 检索任务:GutenQA(“大海捞针” 型数据集,每个问题的答案仅 1-2 句话,考验检索精度);
- 问答任务:LongBench 单文档数据集(含 NarrativeQA 叙事文本、QasperQA 学术论文、MultifieldQA 多领域文本,覆盖不同文本类型,用于评估端到端的 RAG 性能)。
评价指标:
- 检索任务:DCG@k(衡量检索结果相关性与排名)、Recall@k(衡量检索到相关证据的比例);
- 问答任务:F1 分数(衡量预测答案与真实答案的匹配度)。
基线方法:递归分块、语义分块、段落级分块、LumberChunker(LLM 直接分块),以及 LGMGC 的两个子模块(LG Chunker、MG Chunker),确保对比的全面性。
段落检索:语义连贯 + 多粒度 = 更高精度
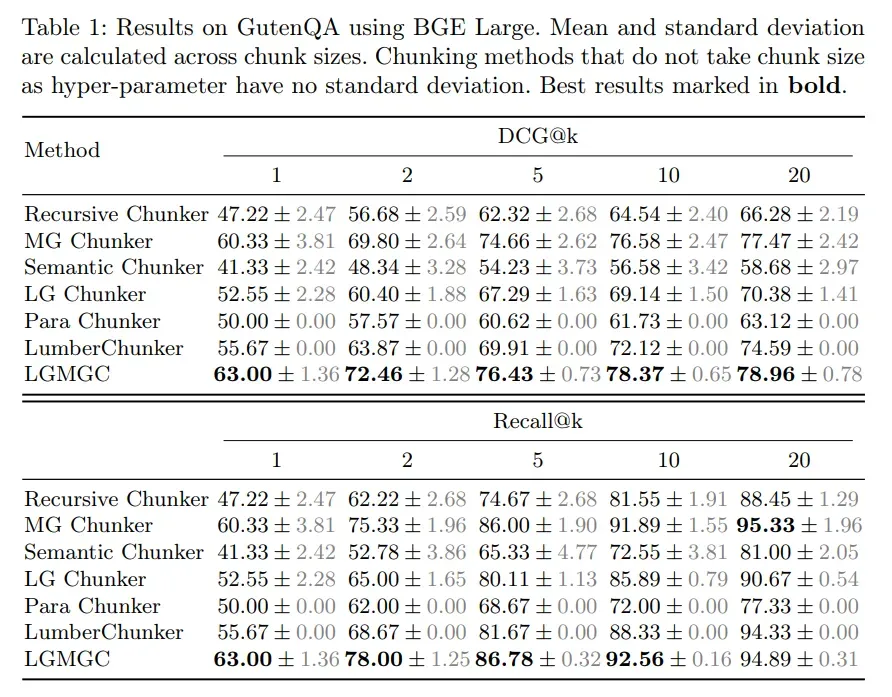
实验结果显示,在不同块大小(θ=200/300/500)下,LGMGC 的表现始终碾压基线:
- Logits-Guided Chunker(LG Chunker)在不同块大小(θ = 200、300、500 个单词)下,始终优于Recursive Chunker、Semantic Chunker和Para Chunker。这表明 LG Chunker 在捕捉上下文连贯性和生成独立、集中的语义块方面具有显著优势。
- LumberChunker在某些指标上略优于 LG Chunker,但 LG Chunker 更具成本效益且更易于部署。LumberChunker 需要递归调用 LLM API,而 LG Chunker 只需要一次前向传播的 logits 信息,支持本地实现,避免了额外的计算成本和安全风险。
- Multi-Granular Chunker(MG Chunker)也表现出显著的性能提升,尤其是在多粒度分块方面,能够更好地适应不同类型的查询需求。
- LGMGC结合了 LG Chunker 和 MG Chunker 的优势,在所有指标上均取得了最佳结果。LGMGC 不仅在语义连贯性方面表现出色,还在多粒度分块方面展现了灵活性。
开放域问答:分块优化让 RAG 性能翻倍
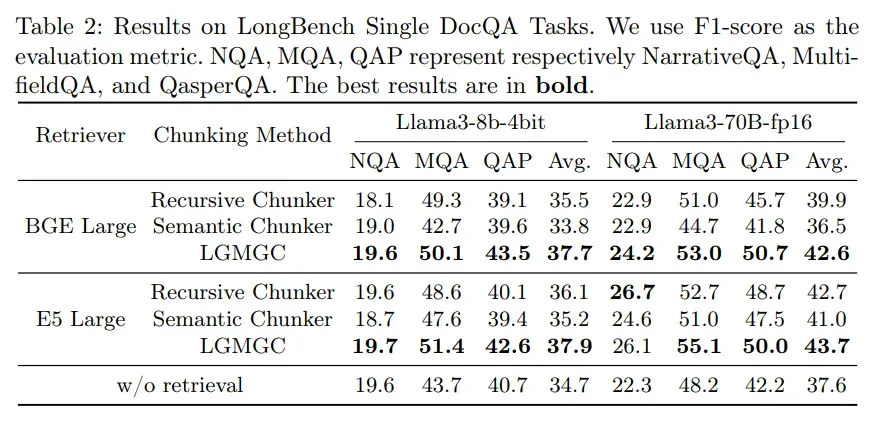
在问答任务中,LGMGC 的优势更明显:
结果表明,与直接将整个文档提供给生成器相比,应用RAG流程显著提升了性能。关于分块器的性能,结果与段落检索评估中的结果一致。在使用最优块大小的情况下,LGMGC在所有三个数据集上均表现出最高的性能,无论使用哪种检索器和生成器。这表明,与现有基线相比,LGMGC在下游问答任务中能够产生更优的结果。
04、总结
LGMGC 框架的创新之处,在于它跳出了 “要么重语义、要么重效率” 的传统思维,通过 “Logits 引导语义分块 + 多粒度适配需求” 的组合,为 RAG 分块提供了全新范式。其核心价值可总结为三点:
- 语义更准:借助 LLM 的 Logits 信息,精准识别语义边界,避免分块碎片化;
- 成本更低:用本地量化 LLM 替代第三方 API,降低部署成本与安全风险;
- 适配性强:多粒度子块能满足检索(小粒度)与生成(大粒度)的不同需求,适配学术、小说、新闻等多种文本类型。
当然,LGMGC 并非完美:目前它对超长篇文档(如 10 万字以上的书籍)的处理效率仍有提升空间;同时,块大小 θ 的选择仍需人工调试,未来若能实现 θ 的自适应调整,性能还能进一步提升。
但不可否认的是,LGMGC 为 RAG 技术的工程化落地提供了关键突破口 —— 对于企业而言,它既能提升问答系统的精度,又能控制成本与风险,是现阶段分块方案的优选。如果你正在搭建 RAG 系统,不妨试试 LGMGC,或许能让你的系统性能实现 “质的飞跃”!
复制

