核心速览
研究背景
- 研究问题:这篇文章要解决的问题是如何在检索增强生成(RAG)系统中有效利用图结构来提升大型语言模型(LLMs)的性能,特别是在知识密集型任务中。
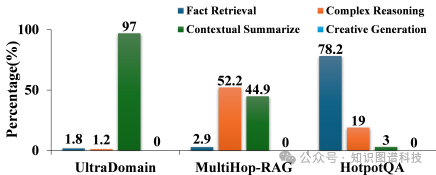
- 研究难点:该问题的研究难点包括:现有基准测试(如HotpotQA、MultiHopRAG和UltraDomain)未能充分评估图结构在RAG系统中的有效性;现有数据集缺乏领域特定知识和明确的逻辑连接;现有基准测试的任务复杂度划分不细致,无法全面评估模型的复杂推理能力。
- 相关工作:该问题的研究相关工作有:传统的RAG系统通过将文本分块进行索引和检索,但这种方法会牺牲上下文信息;GraphRAG系统通过构建外部结构化图来改进LLMs的上下文理解能力,但其在实际任务中的表现不一致。
研究方法
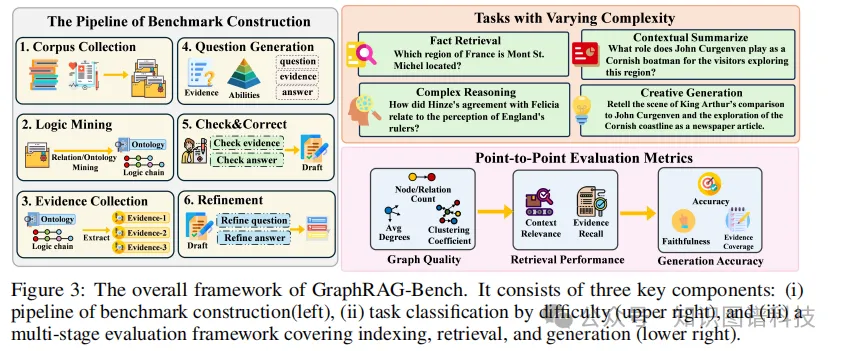
这篇论文提出了GraphRAG-Bench,用于评估GraphRAG模型在层次化知识检索和深度上下文推理中的表现。
 图片
图片
具体来说,
- 任务形式化:设计了四个不同难度的任务,从事实检索到创意生成,逐步增加检索难度和推理复杂性。
 图片
图片
- 数据集构建:构建了两个数据集,一个是医学指南数据集,包含明确的层次结构和标准化协议;另一个是19世纪小说数据集,包含隐式的非线性叙事。
- 逻辑和证据提取:使用GPT-4.1将原始文本转换为结构化的领域本体,保留实体及其上下文关系和层次依赖关系。
- 问题生成:根据证据的类型生成问题,从孤立子图的检索到全局拓扑感知的综合推理。
- 相关性检查和精炼:实施严格的验证和精炼过程,确保数据集的准确性和实用性。
实验设计
- 数据收集:从国家综合癌症网络(NCCN)临床指南和Project Gutenberg图书馆收集了医学指南和小说数据集。
- 实验设计:设计了四个不同难度的任务,并在每个任务上评估了多种GraphRAG框架和传统RAG系统的表现。
- 样本选择:选择了医学指南和小说数据集中的样本,确保数据的多样性和代表性。
- 参数配置:在实验中保持了统一的条件,所有系统使用相同的嵌入模型和生成温度,以公平比较各系统的性能。
结果与分析
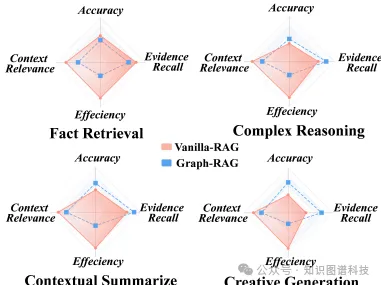
- 生成准确性(Q1):在简单事实检索任务中,基本RAG与GraphRAG的表现相当或更优;在复杂任务中,GraphRAG表现出明显的优势,特别是在复杂推理、上下文总结和创意生成任务中。
 图片
图片
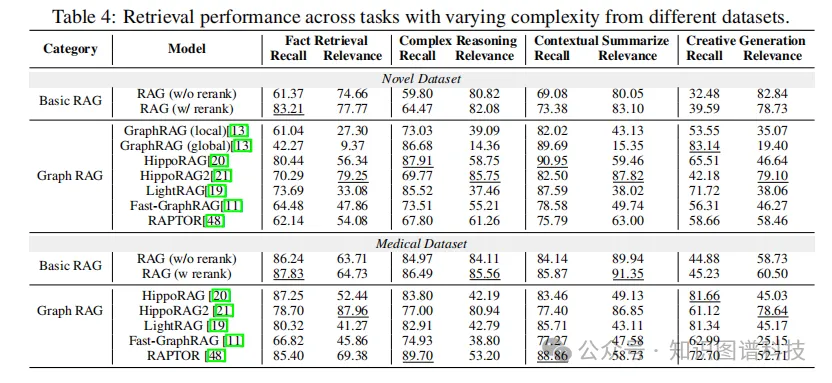
- 检索性能(Q2):在简单问题中,RAG在检索离散事实方面表现优异;在复杂问题中,GraphRAG在连接远距离文本片段方面表现出色。
 图片
图片
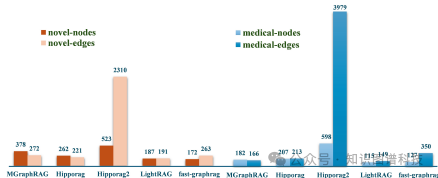
- 图复杂性(Q3):不同GraphRAG实现生成的索引图在结构上存在显著差异,HippoRAG2生成的图密度最高,节点和边数最多,改善了信息的连接性和覆盖率。
- 效率(Q4):GraphRAG由于涉及额外的知识检索和图聚合步骤,显著增加了提示长度,特别是在复杂任务中,提示长度的增加可能导致冗余信息的引入,从而降低上下文相关性。
总体结论
这篇论文系统地研究了GraphRAG在哪些条件下能够超越传统RAG,并提供了其实际应用的指导。通过提出GraphRAG-Bench,论文为评估GraphRAG模型提供了一个全面的基准测试,揭示了图结构在不同任务中的潜在优势。尽管GraphRAG在复杂任务中表现出色,但在简单任务中可能会引入冗余信息,影响效率。未来的研究可以扩展到多模态数据的评估,进一步验证GraphRAG在异构知识表示中的应用效果。
论文评价
优点与创新
- 全面性:GraphRAG-Bench设计了一个全面的基准测试,涵盖了从图构建、知识检索到最终生成的整个流程,提供了系统性的评估。
- 多样化的任务:基准测试包含了从事实检索、复杂推理、上下文摘要到创意生成等多种难度的任务,确保了评估的全面性。
- 高质量的数据集:数据集结合了结构化的医学指南和未组织的小说文本,平衡了非结构化的现实世界模糊性和领域特定的层次结构。
- 阶段性的评估指标:设计了阶段性的评估指标,能够细粒度地评估GraphRAG模型在图构建、知识检索和最终生成等各个阶段的表现。
- 开源和可复现性:代码和数据集已开源,确保了研究的透明性和可复现性。
- 创新的图结构:通过引入图结构,显著提高了知识检索的精度和上下文的深度,使LLMs能够更有效地处理复杂的多跳查询。
不足与反思
- 单模态限制:当前的框架仅限于文本上下文,忽略了多模态数据集成带来的挑战和机会。未来工作将扩展到多模态评估,测试基于图的检索和推理机制在混合知识表示下的泛化能力。
- 实际应用的挑战:尽管GraphRAG在理论上具有很大的潜力,但在实际应用中,特别是在需要跨模态数据集成的领域(如医疗、法律分析和科学研究),仍需进一步验证和改进。
关键问题及回答
问题1:GraphRAG-Bench是如何设计任务复杂度的?
GraphRAG-Bench设计了四个不同难度的任务,从简单的事实检索到复杂的创意生成,逐步增加检索难度和推理复杂性。具体任务包括:
- 事实检索:要求从文本中检索孤立的知识点,主要测试精确的关键词匹配。
 图片
图片
- 复杂推理:要求通过逻辑连接多个知识点,测试模型的综合推理能力。
- 上下文总结:要求将分散的信息综合成连贯的结构化答案,强调逻辑一致性和上下文理解。
- 创意生成:要求在检索内容的基础上进行推理,生成新的内容,测试模型的创造性。
这种设计确保了模型能够在不同复杂度的任务中得到全面评估,揭示其在处理复杂逻辑合成和上下文理解方面的能力。
问题2:现有的RAG基准测试在评估GraphRAG时的局限性是什么?
- 任务复杂度划分不细致:现有基准测试主要集中在简单的事实检索或线性多跳推理任务上,忽略了复杂逻辑合成的挑战。
- 数据集质量不一致:现有数据集通常来自通用来源(如维基百科或新闻文章),缺乏领域特定的知识和明确的逻辑连接。
- 信息密度低:现有数据集中领域概念和层次依赖关系稀疏,无法有效测试图感知检索机制在多跳推理和上下文一致性方面的优势。
- 评估指标单一:现有基准测试主要关注最终输出的准确性或流畅性,忽略了图结构的内部过程(如图构建、检索和生成),无法全面评估图结构对检索和推理过程的贡献。
问题3:GraphRAG在复杂任务中表现出色的原因是什么?
- 图结构的优势:GraphRAG通过构建外部结构化图来表示实体之间的关系和层次依赖关系,使得模型能够进行更复杂的逻辑推理和发现潜在的连接。
- 多跳推理能力:图结构允许模型跨越多个实体进行推理,解决多跳查询问题,而传统的RAG系统在处理多跳推理时存在局限性。
- 上下文理解深度:图结构有助于模型理解复杂的上下文关系,提高推理的深度和准确性,特别是在需要综合分析多个知识点的情况下。
- 信息组织和覆盖:图结构能够更好地组织和覆盖领域知识,使得模型在处理复杂任务时能够更全面地检索和整合相关信息。


