
上一篇论文介绍了GraphRAG,今天来看一篇算是其进阶版的方法--GraphReader。
对于其研究动机,简单来说,LLMs具有强大的规划和反思能力,但在解决复杂任务时,如函数调用或知识图谱问答(KGQA),以及面对需要多次推理步骤的问题时,仍然面临困难。特别是当涉及到长文本或多文档的处理时,现有的方法往往难以充分利用这些模型的能力来捕捉全局信息,并有效地进行决策。此外,当前的方法在处理多跳问题时也存在局限性,无法充分展现LLM的规划和反思能力。
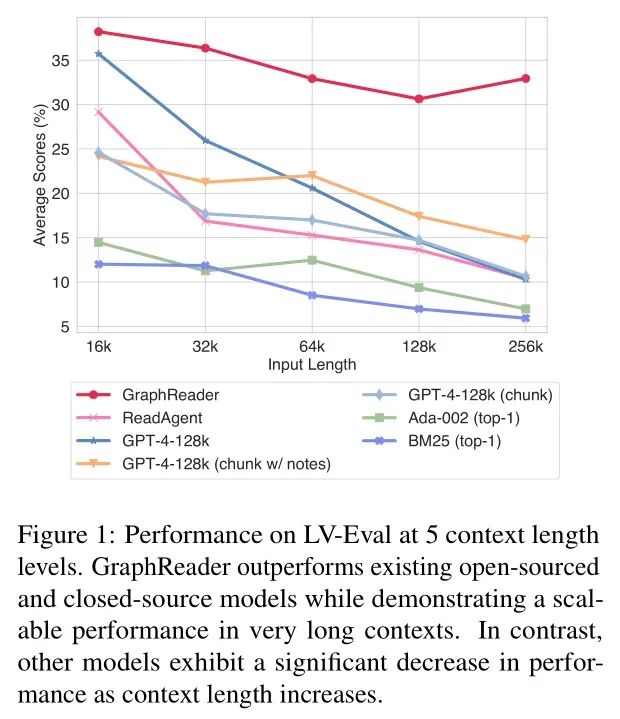
因此本文提出GraphReaderr,通过构建基于图的智能体系统(Graph-based Agent System),以图结构的方式组织长文本,并利用智能体自主探索该图。主图结果如下:
1、方法介绍
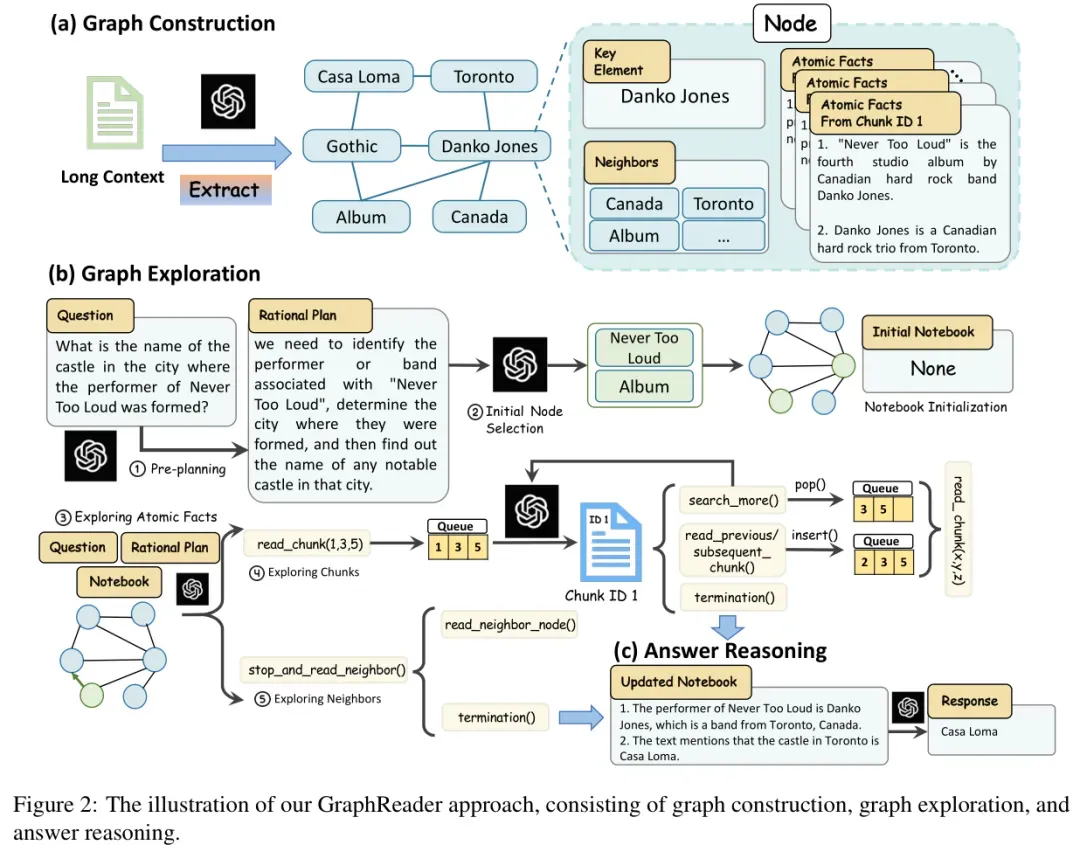
GraphReader方法主要包括两部分,下面来详细看下:
图构建(Graph Construction)
首先是图构建,其目的是将长文本转化为图结构。
从源文档中构建实体知识图谱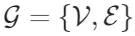 作为第一步,每个节点
作为第一步,每个节点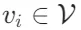 包含一个关键元素
包含一个关键元素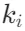 和一系列总结的内容
和一系列总结的内容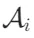 。即,每个节点
。即,每个节点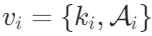 代表了文本中的一个关键元素及其相关联的事实。每条边
代表了文本中的一个关键元素及其相关联的事实。每条边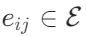 表示节点
表示节点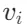 和
和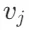 之间的关系。
之间的关系。
具体来说,首先将文档D 分割成最大长度为 L 的块,同时保留段落结构。对于每个块,使用LLM将其总结为原子事实,并使用LLM从每个原子事实中提取关键元素,如必要的名词、动词和形容词。处理完所有块后,对关键元素进行归一化,以处理词汇噪声和粒度问题,创建最终的关键元素集。这种方法将原始文本分割成更小、更易于管理的部分,使得模型能够在较小的上下文窗口内有效工作。
图探索(Graph Exploration)
给定图G和问题Q,目标是设计一个可以使用预定义的函数自主探索图的智能体。智能体首先维护一个Notebook记录支持事实,这些事实最终用于推导最终答案。然后执行两个关键初始化:定义合理计划和选择初始节点。
- Rational Plan(合理计划):为了解决复杂的现实世界多跳问题,预先规划解决方案至关重要。智能体将原始问题逐步分解,识别所需的关键信息,并形成一个合理计划。
- Initial Node(初始节点):选择战略性起点对于提高搜索效率至关重要。智能体评估所有节点V的关键元素,并根据问题和合理计划选择N 个初始节点。
在选择了N 个初始节点作为起点后,智能体首先探索原子事实,然后探索节点的块。接下来,根据问题和合理计划探索相邻节点。智能体在探索过程中不断更新Notebook。
- Exploring Atomic Facts(探索原子事实):由于上下文窗口的限制,不可能将所有原始文本块都包含在上下文窗口内,而所有原子事实都可以适应上下文窗口。因此智能体采用了一种从粗到细的策略。首先,读取与当前节点相关的所有原子事实,按照它们所属的文本块进行分组,并标记相应的块ID。这样智能体可以通过阅读这些分组后的原子事实来快速了解每个文本块的大致内容,同时利用问题、计划以及Notebook中的记录来反思所需的线索,并确定哪些文本块可能包含有用信息。然后,如果某个文本块被认为有价值,智能体会调用read_chunk(List[ID])函数,完成参数填充并将这些ID添加到块队列中,以便进一步阅读。当智能体认为当前节点的信息已经足够或需要更多相关数据时,它可以调用stop_and_read_neighbor()函数,暂停对当前节点的探索,转而开始探索邻居节点。
- Exploring Chunks(探索块):当块队列不为空时,表示智能体已经识别出多个感兴趣的文本块。然后遍历队列,阅读每个块。这一步至关重要,因为原子事实仅总结关键信息并提供简要线索,而特定细节最好直接从原始文本块中获得。在阅读块时,智能体将再次考虑问题和计划,思考可以添加到当前Notebook中的信息。在Notebook更新后,智能体将选择执行下面的操作之一:1)search_more如果支持事实不足,将继续探索队列中的块;2)read_previous_chunk和read_subsequent_chunk由于截断问题,相邻块可能包含相关和有用的信息,智能体可能会将这些 ID 插入队列;3)termination如果已收集到足够信息以回答问题,将完成探索。
- Exploring Neighbors(探索相邻节点):一旦当前节点的原子事实和块队列已全部处理完毕,表示该节点已彻底探索,智能体需要访问下一个节点。考虑到问题、计划和Notebook的内容,智能体检查所有相邻节点,并执行以下操作之一:1)read_neighbor_node选择可能有助于回答问题的相邻节点并重新进入探索原子事实和块的过程;2)termination如果确定所有相邻节点都不包含有用信息,将完成探索。
答案推理(Answer Reasoning)
在 N 个智能体独立收集信息并停止探索后,编译每个智能体的Notebook,进行推理和生成最终答案。使用CoT,LLM 首先分析每个笔记,考虑其他记忆中的补充信息,并使用多数投票策略解决任何不一致性。最终,LLM 将考虑所有可用信息以生成最终答案。
2、实验
评估基准
多跳长文本问答:HotpotQA、2WikiMultihopQA、MuSiQue、HotpotWikiQA-mixup(包括五个文本长度级别:16k、32k、64k、128k和256k)
单跳长文本问答:NarrativeQA
评估指标
F1 分数、精确匹配(Exact Match, EM)分数和优化后的 F1* 分数。F1* 首先计算黄金答案关键词的召回率,仅当其超过一定阈值时才计算 F1 分数,否则得分默认为零。
主要结果
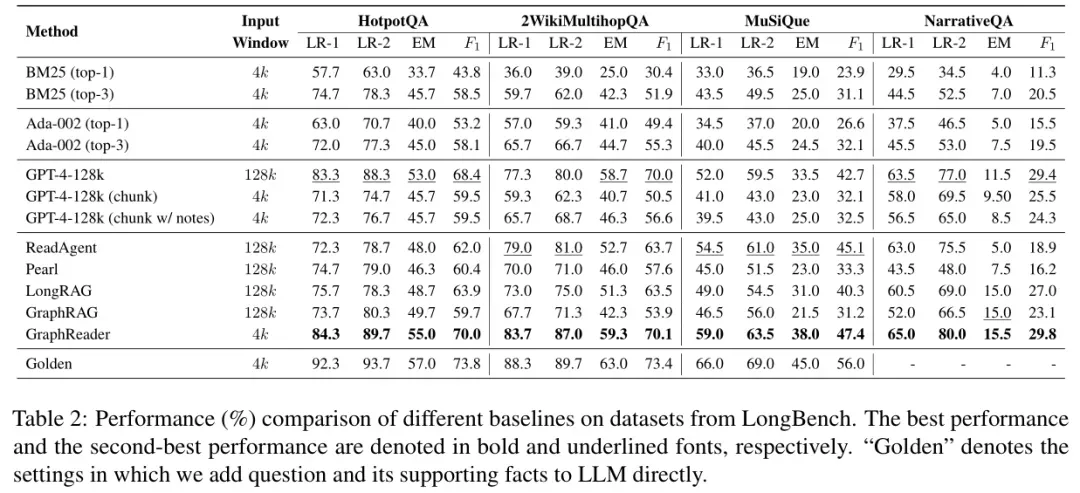
- RAG 方法的结果:基于 BM25 和 Ada002 的 RAG 方法表现最差,可能是因为文本检索难以召回包含回答问题所需支持事实的所有块。尽管增加召回的块数量可以提高文本检索的性能,但上下文窗口将限制这些RAG方法的有效性。
- 长文本 LLM 的结果:直接使用 GPT-4-128k 处理长文本的直接回答性能显著优于 RAG 方法,甚至在三个长文本基准测试中优于 ReadAgent。这是因为 GPT-4-128k 在处理长文本和执行多跳推理任务方面的优越性能。
- GraphReader 结果:GraphReader 在四个长文本基准测试中的表现始终优于基线方法,并在多跳长文本任务中展现出卓越的性能。GraphReader 的方法能够高效识别关键信息,并搜索输入问题的支持事实。
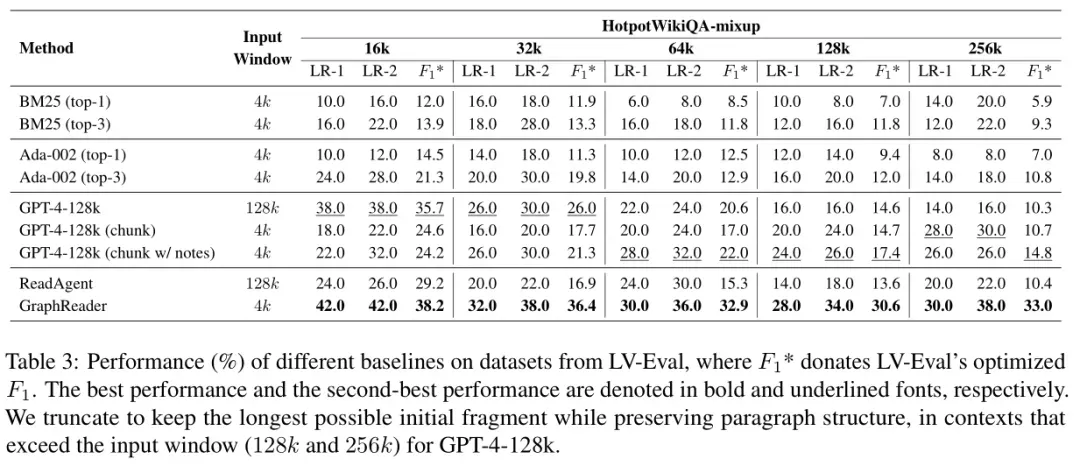
极长上下文任务的结果:
消融实验
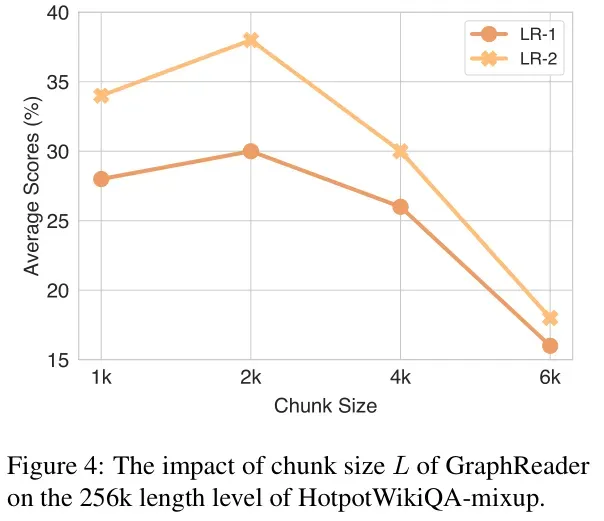
- The Effect of Rational Plan(合理计划的效果):合理计划在指导代理选择和探索图上的节点是有效的。去除理性计划后,性能有所下降,这证明了理性计划在指导探索中的重要性。
- The Effect of Node Selection(节点选择的效果):随机选择导致性能显著下降,平均下降了18%。表明GraphReader在选择节点时非常谨慎,从而实现了更合理和有效的探索。
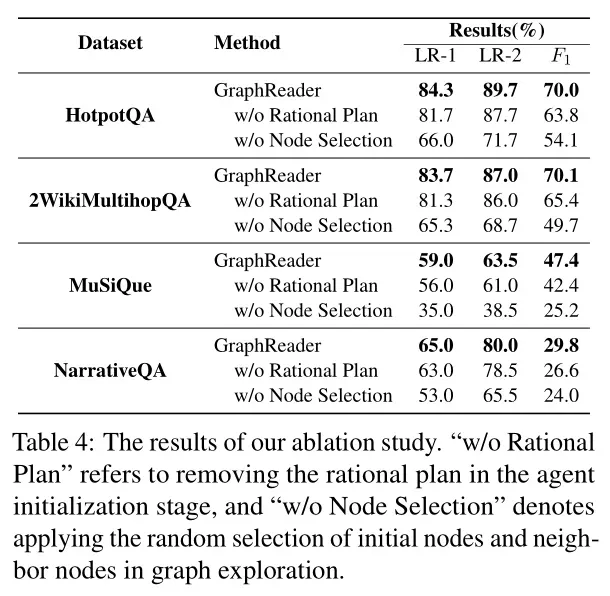
- Impact of the Number of Initial Nodes(初始节点数量的影响):增加节点数量可以提高性能,直到达到某个点,最佳性能为5个初始节点,研究者将其设置为默认值。然而,超过这个阈值,性能会下降,特别是在单跳场景中,这可能是由于太多初始节点增加噪声。
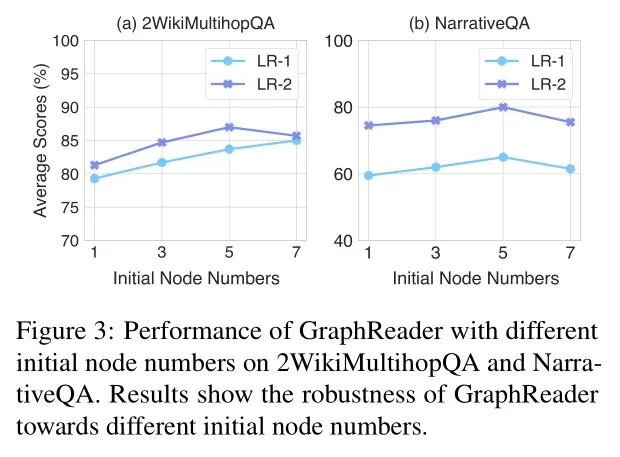
- Impact of the Chunk Size(块大小的影响):块大小的最佳性能为2k。当块大小超过一定阈值时,性能会下降,因为较大的块可能导致模型忽略关键细节。相反,较小的块可能导致更多的语义截断,阻碍理解和准确提取原子事实。
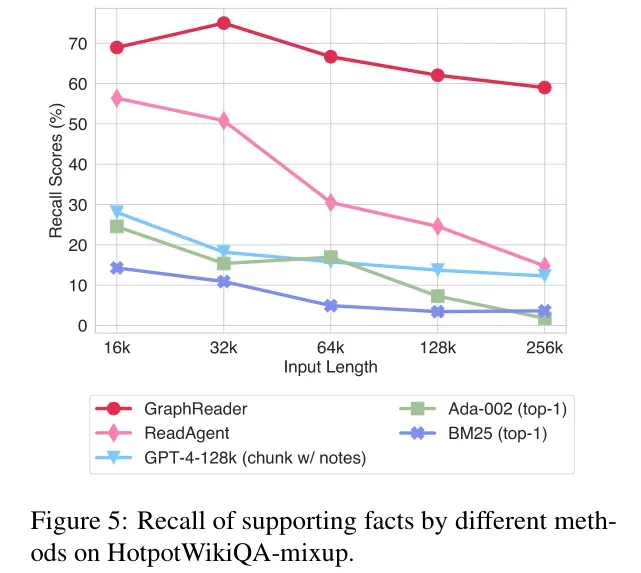
- 成本分析(Cost Analysis):通过比较 ReadAgent 和 GraphReader 在处理单个问题时的平均令牌消耗,结果表明,GraphReader 使用的令牌数量仅比 ReadAgent 多 1.08 倍(52.8k / 48.7k),但性能提升却超过了双倍,从而展示了 GraphReader 的优越性。更重要的是,在单文档多查询场景中,GraphReader 具有显著优势,因为这些场景中只需要构建一个图,后续的问答可以在这个图上进行,减少了整体的令牌消耗。
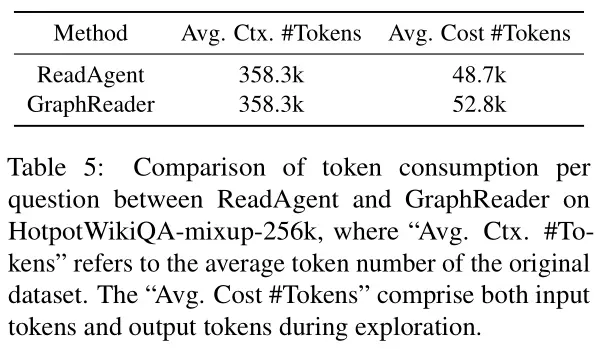
- 支持事实的回忆率分析(Recall Rate Analysis):评估不同方法在 HotpotWikiQA-mixup 数据集上支持事实的回忆率。结果表明,GraphReader 在所有方法中保持了较高的回忆率,即使在 256k 上下文长度下,回忆率也保持在 60% 左右,这证明了 GraphReader 在处理长文本和复杂问题时的性能优于现有的方法,并且能够高效地利用有限的上下文窗口来处理长距离依赖和多跳关系。
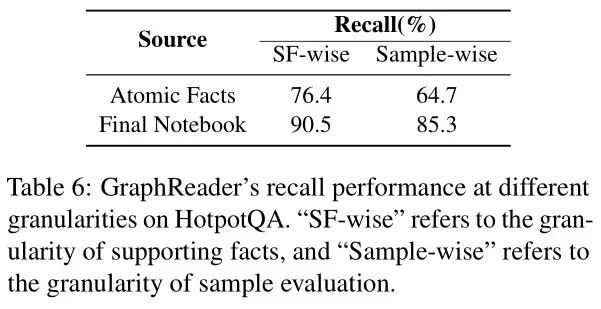
3、总结
以智能体的方式构建了一个基于图结构方式的LLM处理长文本的方案。但是在图探索模块上,每一个环节都需要LLM参与,会导致大量Token消耗,并且图构建过程可能极其耗时,方法还有很大优化空间。不过,确实为多跳推理、图结构化表示、图与LLM结合的研究提供了新的思路和方法。


