
在RAG全链路中,高质量的文本分块技术是RAG检索效果的关键一环。前面介绍了基于Sentence-Transformer的语义分块方法,今天来看一种名为Late Chunking的新型分块方法,不同于传统的 “先分割再嵌入” 模式,而是通过 “先嵌入再分割” 的创新思路,让文本块的语义表示更加精准。下面,将从研究动机、算法详解、实验结果和总结四个方面,详细了解下这个方法。
论文地址:https://arxiv.org/pdf/2409.04701
项目地址:https://github.com/jina-ai/late-chunking
一、研究动机:传统分块方法的痛点与突破方向
在检索增强生成任务中,将文本文档分割成较小的块(chunks)是常见操作,目的是为了更好地进行语义表示和检索。然而,传统的 “naive chunking” 方法(固定大小分块、按符号分块、先分割文本再进行嵌入等)存在一个致命缺陷 —— 会导致文本块丢失上下文信息,进而严重影响检索效果。
举个简单的例子,当文档中出现 “柏林是德国的首都,它有着悠久的历史” 这样的句子时,传统分块可能会将 “柏林是德国的首都” 和 “它有着悠久的历史” 分割成两个块。由于后一个块中的 “它” 失去了前文 “柏林” 的上下文支撑,在检索 “柏林的历史” 时,就很难被准确匹配到。这就是因为相关文本块的信息依赖于其他文本块时,传统的嵌入方法无法很好地捕捉这种长距离的语义依赖关系,导致检索结果不够准确。

再看研究现状,大多数现代文本嵌入模型基于 Transformer 架构,使用均值池化等方法将文本转换为密集向量表示。但这些模型在处理长文本时存在上下文长度限制,通常需要对文本进行分割。常见的文本分割方法包括固定长度分割、按句子或段落分割等,一些更复杂的方法如语义分割会根据句子嵌入的相似性来确定最优的分割位置,但这些方法都存在丢失上下文信息的问题。
虽然有一些研究提出增强文本块上下文的方法,如使用重叠分割或借助大型语言模型(LLM)来为文本块添加相关上下文信息,但这些方法要么计算成本较高,要么需要额外的模型训练,实用性受限。
正是在这样的背景下,Late Chunking 方法应运而生,它作为一种新颖的文本块嵌入方法,先对整个长文本进行嵌入,再在 Transformer 模型之后、均值池化之前进行文本分割,从而让每个文本块的嵌入能够包含整个文档的上下文信息,这便是其核心的研究动机和创新点。
先看结果:表 1 显示,使用朴素分块时,即使上下文中的两个句子都指的是柏林市,不包含 “Berlin” 一词的文本的相似性得分也很低。使用Late Chunking时,可以看到相似性得分要高得多。后期分块策略将 “Berlin” 编码到 “Its” 和 “the city” 的嵌入中,因为它在分块之前会在上下文中看到它们。

二、Late Chunking 的核心逻辑与实现步骤
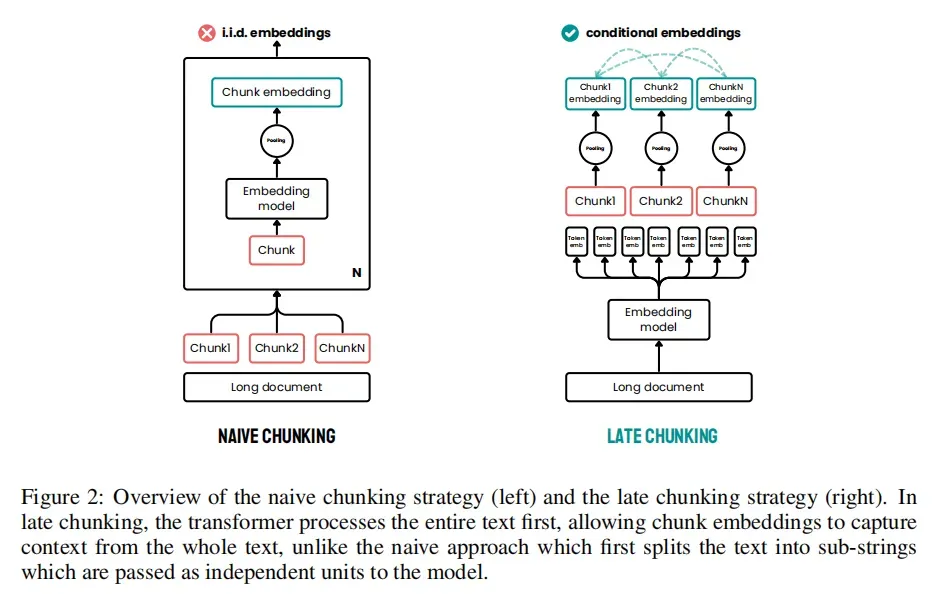
核心思想
Late Chunking 方法的核心逻辑在于利用嵌入模型的长上下文输入窗口,解决传统分块方法的上下文丢失问题。具体来说,这种方法首先对整个长文本进行处理,生成包含整个文档上下文信息的标记嵌入(token embeddings),然后再进行分块。这样,每个文本块的嵌入都能包含整个文档的上下文信息,从而提高嵌入的质量和检索的准确性。
具体步骤
- 分块:使用分块策略 S 将文本 T 分割成多个块
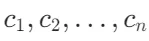 。这些块可以基于固定大小、句子边界或语义边界等策略生成。
。这些块可以基于固定大小、句子边界或语义边界等策略生成。 - 标记化:对整个文本 T 进行标记化,生成标记序列
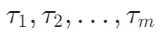 和每个标记的字符长度
和每个标记的字符长度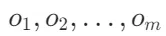 。标记化是将文本转换为模型可以处理的标记(tokens)的过程。
。标记化是将文本转换为模型可以处理的标记(tokens)的过程。 - Transformer 处理:将标记序列
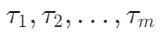 输入到嵌入模型的 Transformer 部分,生成每个标记的向量表示
输入到嵌入模型的 Transformer 部分,生成每个标记的向量表示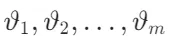 。这些向量表示包含了整个文本的信息。
。这些向量表示包含了整个文本的信息。 - 确定块边界:遍历每个标记,计算当前块的字符长度 ochunk。当 ochunk 达到当前块的字符长度
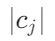 时,记录当前块的起始和结束标记索引 (cuestart, cueend) 。更新 cuestart 和 ochunk,继续处理下一个块。
时,记录当前块的起始和结束标记索引 (cuestart, cueend) 。更新 cuestart 和 ochunk,继续处理下一个块。 - 池化:对每个块的标记嵌入进行平均池化,生成每个块的嵌入表示
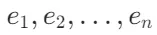 。平均池化是将块内所有标记嵌入的平均值作为块的嵌入表示。
。平均池化是将块内所有标记嵌入的平均值作为块的嵌入表示。

长文本后期分块(Long Late Chunking)
尽管许多嵌入模型支持较长的上下文长度(如 8192 个标记),但对于非常大的文档,这些模型可能仍然无法一次性处理整个文档。此外,随着标记数量的增加,编码所需的内存会呈指数级增长,导致一次性编码所有标记变得不可行。
为了解决这一问题,提出了一种长文本后期分块方法(Long Late Chunking)。该方法将文本分割为包含多个小块的“宏块”(macro chunk),每个宏块包含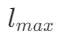 个标记。每个宏块通过后期分块方法单独处理,以避免一次性处理整个文档带来的内存问题。为了避免上下文缺失,宏块之间会增加一定数量的标记 ω 作为重叠部分,这些重叠的标记在后期分块过程中作为补充上下文信息。
个标记。每个宏块通过后期分块方法单独处理,以避免一次性处理整个文档带来的内存问题。为了避免上下文缺失,宏块之间会增加一定数量的标记 ω 作为重叠部分,这些重叠的标记在后期分块过程中作为补充上下文信息。

训练方法
虽然 Late Chunking 方法本身无需额外训练即可工作,但使用平均池化训练的模型可能不太适合对包含周围标记额外信息的块标记嵌入进行编码。因此,提出一种改进的训练方法,使用 “跨度池化”(span pooling)技术,训练模型将注释文本跨度中的相关信息专门编码到其标记嵌入中。
平均池化是一种常用的文本嵌入方法,它通过计算一组标记嵌入的平均值来生成文本的嵌入表示。这种方法简单且有效,尤其适用于处理固定长度的文本块。然而,平均池化有一个关键的局限性:它假设所有标记对最终的文本表示都有相同的贡献,而忽略了标记之间的语义关系和上下文信息。
在 Late Chunking 方法中,文本被分割成多个块,每个块的嵌入需要包含整个文档的上下文信息。这意味着每个块的嵌入不仅要反映块内的内容,还要包含来自其他块的相关信息。例如,一个块可能包含对另一个块中提到的实体的引用,这些引用需要在嵌入中得到体现。
训练数据由查询 q、相关文档 d 和文档中相关跨度注释 ⟨start,end⟩ 组成的元组(q,d,⟨start,end⟩)。跨度注释指定了文档中包含答案的相关部分。
损失函数主要包括:
- InfoNCE 损失:使用 InfoNCE 损失函数对文本对进行训练,确保查询向量和相关文档向量之间的相似性。
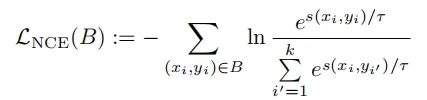 其中,查询向量
其中,查询向量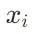 通过将嵌入模型按常规方式应用于查询文本
通过将嵌入模型按常规方式应用于查询文本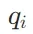 获得。对于文档嵌入
获得。对于文档嵌入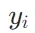 ,通过将模型应用于文档
,通过将模型应用于文档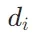 获得标记嵌入集合,并仅对跨度
获得标记嵌入集合,并仅对跨度 - 双向损失:使用双向 InfoNCE 损失函数,确保查询和文档之间的双向相似性。
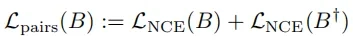 其中
其中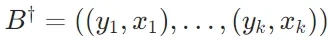 通过交换批次 B 中的成对顺序获得。
通过交换批次 B 中的成对顺序获得。
三、Late Chunking 的性能验证
评估方法
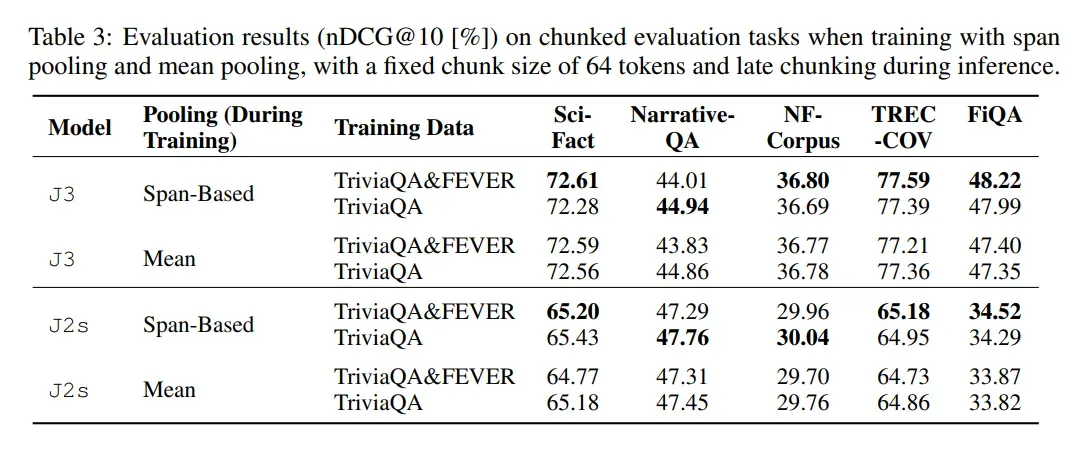
使用 BeIR benchmark 中的小型检索任务进行评估。评估的模型包括 jina-embeddings-v2-small、jina-embeddings-v3、nomic-embed-text-v1。使用的分块策略包括固定大小边界(每个块包含固定数量的标记,如 256 个标记)、句子边界(每个块包含固定数量的句子,如 5 个句子)、语义句子边界(根据句子嵌入的相似性动态确定块的边界)。
评估指标使用 nDCG@10(Normalized Discounted Cumulative Gain at 10)作为主要评估指标。
实验设计为:将文档分割为较小的块,编码并存储到嵌入索引中。对于每个查询嵌入,通过其归一化向量表示的 k - 近邻(kNN)确定对应的块。将块的 kNN 排名转换为文档的 kNN 排名(对于在排名中多次出现的文档,仅保留首次出现)。将生成的排名与真实 QRels 文件对应的排名进行比较,并计算 nDCG@10 等检索指标。
主要结果
Late Chunking 方法在所有模型和分块策略下均优于 Naive Chunking 方法。平均来看,Late Chunking 方法相比 Naive Chunking 方法在 nDCG@10 上有显著提升。
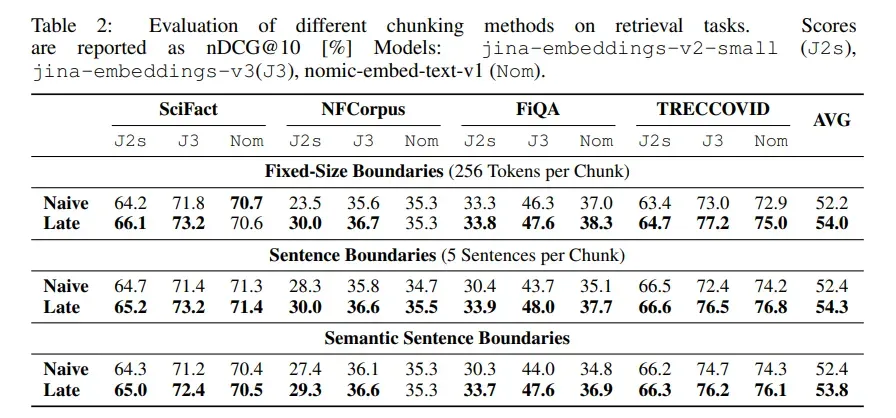
分块大小影响
- Late Chunking 方法在较小分块大小下表现更好,尤其是在 NFCorpus 数据集上。
- 对于某些阅读理解任务(如 Needle-8192 和 Passkey-8192),Naive Chunking 方法在较大分块大小下表现更好。这是因为这些任务需要在相对无关的上下文中找到特定的句子或短语,而 Late Chunking 方法在这种情况下可能引入了过多的无关上下文信息。
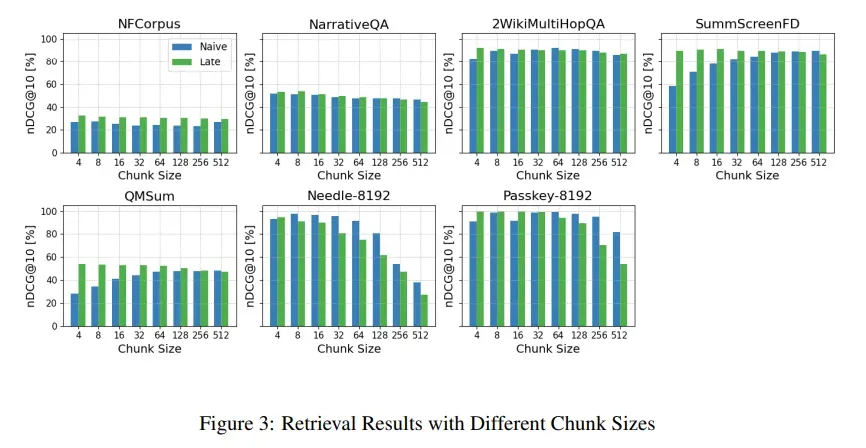
长文本后期分块评估
- Long Late Chunking 方法在所有分块大小下均优于 Naive Chunking 方法。
- 与未截断的实验相比,nDCG 分数更高,说明 Long Late Chunking 方法能够有效解决长文档的上下文丢失问题。
Long Late Chunking 方法在处理非常长的文档时表现出色,能够有效解决上下文丢失问题,提高检索结果的相关性和准确性。
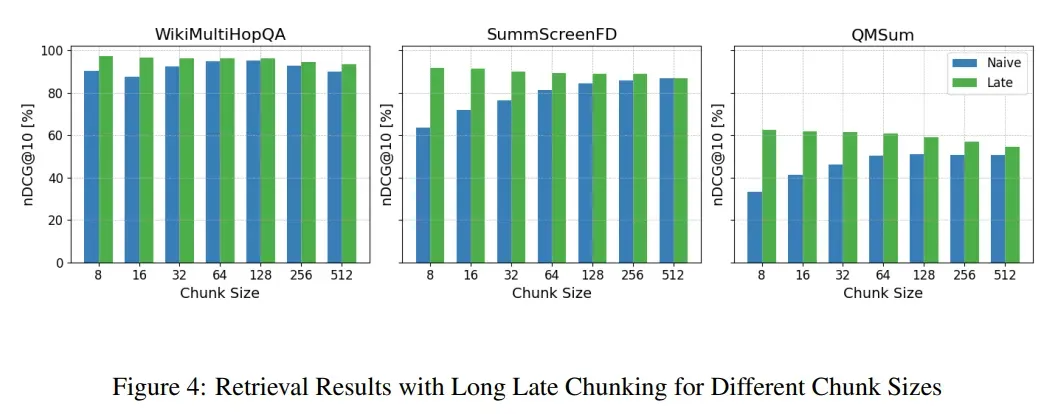
训练方法评估
评估提出的跨度池化(span pooling)训练方法对 Late Chunking 方法性能的影响。
- 跨度池化方法在大多数数据集上表现优于普通平均池化方法。
- 使用跨度池化方法训练的模型在检索任务中表现更好,特别是在需要精确匹配相关跨度的场景中。
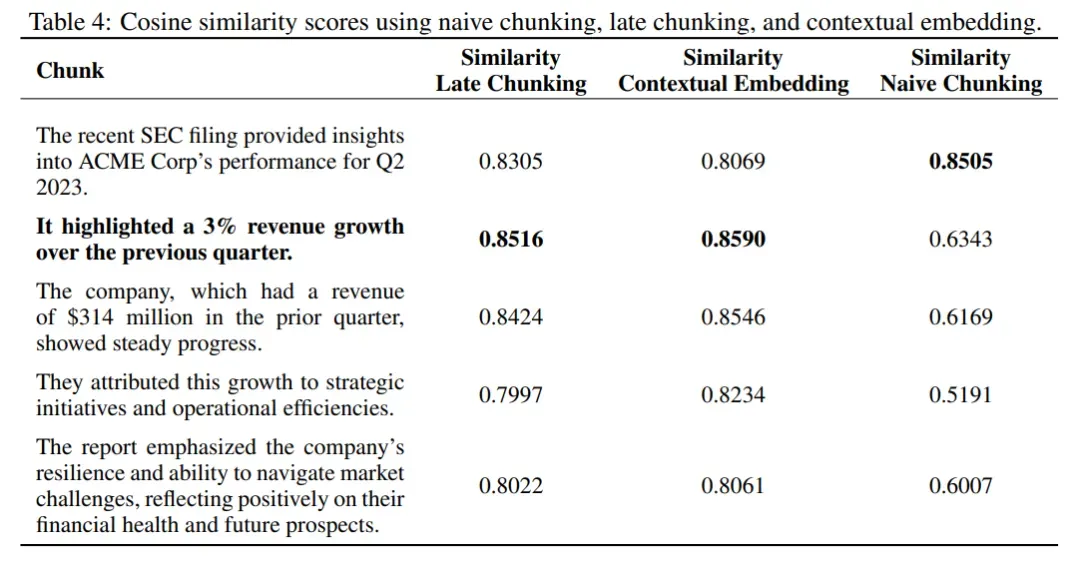
与上下文嵌入的比较
将 Late Chunking 方法与基于大型语言模型(LLM)的上下文嵌入方法进行比较。
方法:使用一个虚构的金融文档和查询 “What is ACME Corp’s revenue growth for Q2 2023?” 进行实验。比较 Late Chunking 方法、Naive Chunking 方法和基于 LLM 的上下文嵌入方法的性能。使用claude-3-haiku-20240307模型从整个文本中选择相关上下文信息,并将其添加到每个文本块的开头。使用jinaai/jina-embeddings-v2-small-en对查询和增强后的块进行编码,计算余弦相似度。
结果显示:
- 上下文嵌入方法和 Late Chunking 方法在相关块上的相似度分数最高。
- Naive Chunking 方法的相似度分数较低,且低于其他块的相似度。
- Late Chunking 方法在不使用额外 LLM 的情况下,能够达到与上下文嵌入方法相近的性能。
四、总结
Late Chunking 方法的关键在于先对整个长文本进行嵌入处理,生成包含整个文档上下文信息的标记嵌入,然后再根据预定义的分块策略进行分块。这种方法使每个文本块的嵌入都能包含整个文档的上下文信息,从而提高嵌入的质量和检索的准确性。与传统分块方法相比,Late Chunking 方法通过在标记嵌入生成之后进行分块,避免了上下文信息的丢失。
不过,Late Chunking 也并非完美无缺,对于长文本来说,该策略的有效性相对受限,不如 LumberChunker 等基于 LLM 的方法。但总体而言,Late Chunking 为文本检索领域提供了一种全新的思路和有效的解决方案,尤其在中短文本处理和对上下文依赖性强的检索任务中,展现出了巨大的潜力。相信随着技术的不断发展,Late Chunking 会得到进一步的优化和完善,在更多领域发挥重要作用。


