资讯列表

AI产品经理亲测!这套入职SOP让我快速吃透任何新业务(附模板)
每次换工作,我都会被问同一个问题,你怎么总能在很短的时间里,把一条完全陌生的业务跑顺? 听上去好像是那种天赋型人物的故事,好像我天生就对新环境适应得快。 但我自己很清楚真正起作用的,是一套我反复打磨出来的入职摸底习惯。

学历加速贬值的AI时代,大学还有必要读吗?
想聊这个话题,是因为周末的时候,我在油管上看了最新一期Open AI 的CEO Sam Altman和知名经济学家Tyler Cowen的访谈,对话内容挺有意思的,他们聊了很多关于未来AI趋势,其中有关教育,读书以及工作机会这几个方面话题跟和我们日常工作生活息息相关,值得拿出来跟大家分享。 相关研究:想看原访谈的,可以点这个链接:. Tyler在访谈问了Sam一个非常现实的问题:“在未来5到10年,你认为大学学位的回报率会如何变化?

AI训练师必看!5个章节带你快速掌握RAG检索增强项目
在 AI 应用日益深入的今天,RAG(Retrieval-Augmented Generation)正成为提升模型实用性的关键技术。 本文将从 AI 训练师的视角出发,系统拆解 RAG 的核心机制、应用场景与训练要点,帮助你在构建高质量智能体时少走弯路、精准发力。 今天我向大家介绍检索增强也就是 RAG,在公司里面也是一个独立的项目,并且有自己的考核指标。

小扎再出奇招:Meta员工绩效,AI来评判
鹭羽 发自 凹非寺. 量子位 | 公众号 QbitAI疯狂小扎他急了……. 大刀阔斧裁员还不够,员工KPI也要用AI横插一脚。

GPT-5败下阵,这款中国AI拿下全球第一,众多医生已在用它做诊断
衡宇 发自 凹非寺. 量子位 | 公众号 QbitAI在多数基层门诊里,一个医生往往要从早忙到晚,患者一拨接一拨。 病种繁杂、节奏飞快,查文献、请会诊这些理想中的操作,根本挤不进大夫有限的工作时间。

拒绝“概念”要“实效”:百度智能云详解Agent Infra如何让智能体成为真正生产力
全球88%的企业已部署AI技术,但仅39%实现了显著财务回报。 这一AI“投入产出比”的剪刀差,揭示了AI产业落地的核心困境。 智能体(Agent)被视为破解难题的关键浪潮,那么,如何让智能体摆脱“玩具”和“概念”的标签,真正深入产业,成为降本增效的“生产力”?

谷歌 DeepMind AI 模型精准预测五级飓风 “梅丽莎”
在近期的飓风季节中,谷歌的 DeepMind 人工智能(AI)模型展现了令人瞩目的预测能力,尤其是在五级飓风 “梅丽莎” 的预报上。 当热带风暴 “梅丽莎” 在海地南部海域游弋时,美国国家飓风中心(NHC)的首席预报员菲利普・帕潘大胆预测,这场风暴将在24小时内迅速增强为四级飓风,并将直接冲向牙买加海岸。 这是 NHC 历史上首次有预报员对风暴的快速增强趋势做出如此明确的预测。

Grok 5延期至2026年Q1 6万亿参数瞄准AGI
马斯克在Baron Capital专访中确认,xAI下一代大模型Grok5 推迟至 2026 年第一季度发布,参数量达 6 万亿,将原生支持视频理解,官方称“每GB智能密度”刷新行业纪录。 为训练这一模型,xAI正扩建GPU集群并以X平台实时数据喂入。 马斯克透露,Grok5 采用多模态MoE架构,可一次性解析长视频并回答时序问题,目标在通用人工智能竞赛中取得领先。

AI自主「发现」牛顿第二定律?北大概念驱动型发现系统AI-Newton问世
编辑丨coisini今天谈人工智能(AI)做科研已不再是新鲜事,但如果说 AI 自主「发现」了牛顿第二定律呢? 我们知道,AI 模型擅长识别数据模式并进行预测,但利用数据推导广义科学概念对 AI 来说仍然是一项挑战。 最近,《Nature》报道了一个由北京大学研究团队开发的概念驱动型发现系统 ——AI-Newton,该系统能够从原始数据中自主推导物理定律,无需人工监督或先验物理知识。

成本仅0.3美元,耗时26分钟!CudaForge:颠覆性低成本CUDA优化框架
本文作者包括明尼苏达大学的张子健(共同第一作者),王嵘(共同第一作者),李世阳,罗越波,洪明毅,丁才文。 CUDA 代码的性能对于当今的模型训练与推理至关重要,然而手动编写优化 CUDA Kernel 需要很高的知识门槛和时间成本。 与此同时,近年来 LLM 在 Code 领域获得了诸多成功。

首个完整开源的生成式推荐框架MiniOneRec,轻量复现工业级OneRec!
中科大 LDS 实验室何向南、王翔团队与 Alpha Lab 张岸团队联合开源 MiniOneRec,推出生成式推荐首个完整的端到端开源框架,不仅在开源场景验证了生成式推荐 Scaling Law,还可轻量复现「OneRec」,为社区提供一站式的生成式推荐训练与研究平台。 近年来,在推荐系统领域,传统 “召回 排序” 级联式架构的收益正逐渐触顶,而 ChatGPT 等大语言模型则展现了强大的涌现能力和符合 Scaling Law 的巨大潜力 —— 这股变革性的力量使 “生成式推荐” 成为当下最热门的话题之一。 不同于判别式模型孤立地计算用户喜欢某件物品的概率,“生成式推荐” 能够利用层次化语义 ID 表示用户历史行为序列,并基于生成式模型结构直接生成用户下一批可能交互的物品列表。

苹果新规:开发者必须征得用户同意才能分享数据给第三方 AI
根据苹果公司最近更新的 App 审核指南,开发者在分享用户数据给第三方人工智能时,必须明确告知用户并征得他们的同意。 这一要求在指南的第5.1.2(i) 条款中得到了清晰的说明。 图源备注:图片由AI生成,图片授权服务商Midjourney苹果指出,任何涉及到用户个人数据的处理,开发者都必须提供透明的信息,特别是在将数据分享给第三方 AI 的情况下。

全球数据中心投资飙升,绿色能源将成主流?
根据国际能源署的最新报告,全球在2023年的数据中心投资预计将达到5800亿美元,超过了用于寻找新石油供应的支出,后者为5400亿美元。 这一数据展示了全球经济的一些重大变化,尤其是在生成式人工智能可能加速气候变化的背景下,数据中心与石油产业之间的比较显得尤为引人注目。 图源备注:图片由AI生成,图片授权服务商Midjourney在最近的一期 TechCrunch 的 “Equity” 播客中,主持人 Kirsten Korosec、Rebecca Bellan 和我深入探讨了这一报告的内容。

填补多语言语音幻觉检测空白,CCFQA基准助力评估大模型跨语言与跨模态事实一致性
论文标题:CCFQA: A Benchmark for Cross-Lingual and Cross-Modal Speech and Text Factuality Evaluation(AAAI 2026)论文链接:::(MLLMs)在多语言环境中的日益普及,确保无幻觉的事实准确性变得尤为重要。 然而,现有评估可靠性的基准主要集中在以英语为主的文本或视觉模态,这导致在处理多语言输入(尤其是语音)时存在评估空白。 为弥补这一不足,哈尔滨工业大学社会计算与交互机器人研究中心知识计算组和鹏城实验室数据智能研究所联合发布跨语言跨模态事实性基准(CCFQA),以推动具备更可靠语音理解能力的MLLMs发展。

雷军罕见硬刚回应!同日公关负责人被曝调整
杰西卡 发自 副驾寺. 智能车参考 | 公众号 AI4Auto“网上有不少人断章取义、歪曲抹黑。 雷军终是没忍住,公开回应了。

把数学变成谜题:SAT 求解器如何让机器自动写出人类做不到的证明
编辑丨%Marijn Heule 近十年来致力于破解数学难题,倘若将他的工作写成小说,可能更像特工代号:空六边形、舒尔数 5、凯勒猜想、七维。 事实上,这些曾是几何学和组合数学中最顽固的问题之一,困扰了人们 90 年甚至更长时间。 Heule 使用了一种名为可满足性(SAT)的计算方式将它们一一攻克。

灵宇宙再获2亿元PreA轮系列融资,双十一销售额暴涨230%
11月17日,AI 消费机器人公司灵宇宙(上海灵宇宙科技发展有限公司)宣布,已于近期完成2亿元PreA轮系列融资。 本轮融资由上海国际集团旗下国方创新、国泰海通、广发信德、滴滴出行、拉卡拉旗下考拉基金、润建股份等一众头部金融机构和上市公司参投,老股东超额追投。 投资方国方创新表示:“我们投资的不是AI硬件,而是下一代人机交互的底层范式。
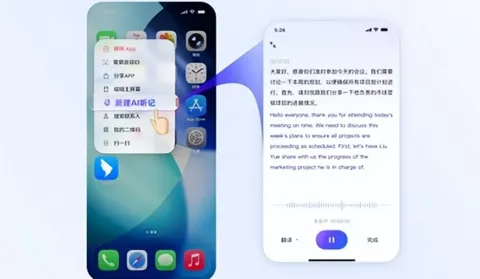
钉钉AI听记上新,一张图看清所有重点,职场和超级个体刚需
11月17日,钉钉8.1.5版本带来了AI听记的重要升级——图文纪要。 现在,所有用户升级至最新版钉钉后,在视频会议过程中,点击“云录制”;在客户拜访或面试交流时,直接在钉钉搜索“AI听记”;或在任何需要AI帮你记录交流内容的情况下,使用DingTalk A1硬件,均可唤起这一功能,一键开启AI时代的记录方式。 作为AI时代职场人开会的必备“搭子”,钉钉AI听记自推出以来在企业侧大受欢迎,它不仅解放了会议记录这项低价值感工作的人力,也让企业的每一场会议次次有沉淀、事事有落实。