中科大 LDS 实验室何向南、王翔团队与 Alpha Lab 张岸团队联合开源 MiniOneRec,推出生成式推荐首个完整的端到端开源框架,不仅在开源场景验证了生成式推荐 Scaling Law,还可轻量复现「OneRec」,为社区提供一站式的生成式推荐训练与研究平台。
近年来,在推荐系统领域,传统 “召回 + 排序” 级联式架构的收益正逐渐触顶,而 ChatGPT 等大语言模型则展现了强大的涌现能力和符合 Scaling Law 的巨大潜力 —— 这股变革性的力量使 “生成式推荐” 成为当下最热门的话题之一。不同于判别式模型孤立地计算用户喜欢某件物品的概率,“生成式推荐” 能够利用层次化语义 ID 表示用户历史行为序列,并基于生成式模型结构直接生成用户下一批可能交互的物品列表。这种推荐模式显著提升了模型的智能上限,并为推荐场景引入 Scaling Law 的可能性。
快手 OneRec 的成功落地,更是彻底引爆了推荐圈子。凭借端到端的推荐大模型,重构现今的推荐系统不再是空谈,它已证明是一场资源可控、能带来真实线上收益的推荐革命。
然而,对于这一可能革新整个推荐系统的新范式,各大厂却讳莫如深,核心技术细节与公开表现鲜有披露。开源社区与一线大厂的探索似乎正在脱钩,技术鸿沟日渐明显。
如何破局?
近日,中国科学技术大学 LDS 实验室何向南、王翔团队联合 Alpha Lab 张岸团队正式发布 MiniOneRec。这一框架作为生成式推荐领域首个完整开源方案,为社区提供了全链路、一站式、端到端的训练与研究平台。

论文标题:MiniOneRec: An Open-Source Framework for Scaling Generative Recommendation
论文链接:https://arxiv.org/abs/2510.24431
代码链接:https://github.com/AkaliKong/MiniOneRec
Huggingface 链接: https://huggingface.co/kkknight/MiniOneRec
核心贡献:
端到端流程支持:从 SID 生成、 模型监督微调、 推荐驱动的强化学习,全链路打通。
开源场景 Scaling Law 验证:首次在开源数据与模型上,验证了生成式推荐的 Scaling Law。
优化后训练框架:提供一套轻量、完整的后训练框架,并引入多项针对推荐任务的改进。
自 10 月 28 日发布以来,MiniOneRec 就广受推荐社区关注。其代码、数据集、模型权重已全部开源,仅需 4-8 卡 A100 同级算力即可轻松复现。
1. 首次公开数据集验证生成式推荐 Scaling Law:
研究人员首次在公共数据集上,验证了生成式推荐模型的 Scaling Law。
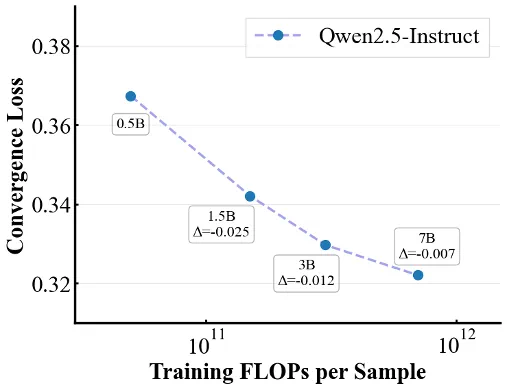
图 1. 模型参数从 0.5B 到 7B 的训练 Loss 变化。
团队在 Amazon Review 公开数据上,以统一的设置训练了从 0.5B 到 7B 的 MiniOneRec 版本。结果惊艳:随着模型规模(训练 FLOPs)的增大,最终训练损失和评估损失持续下降,充分展示了生成式推荐范式在参数利用效率上的优势。
2. MiniOneRec 核心技术框架:
该框架提供一站式的生成式推荐轻量实现与改进,具体包括:
(1)丰富的 SID Construction 工具箱
MiniOneRec 为开源社区提供了丰富的的 SID Construction 工具选择,已集成 RQ-VAE, RQ-Kmeans, RQ-VAE-v2 (Google 最新工作 PLUM), 并将更新 RQ-OPQ 在内的先进量化算法实现。
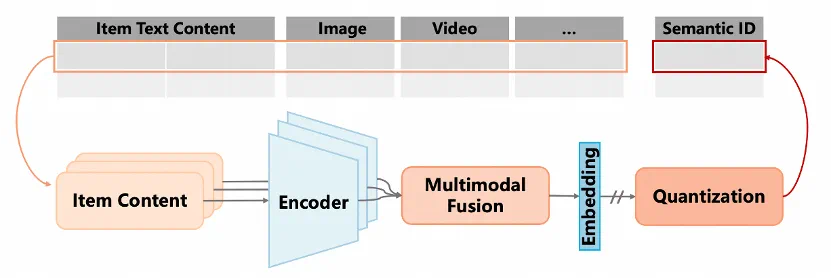
下一步,团队正积极更新接口,以对齐业界的多模态需求。
(2)引入世界知识:全流程 SID 对齐策略
研究人员验证了一个关键发现:引入大模型世界知识,能显著提升生成式推荐的性能。团队分别评测了 MiniOneRec 与其变体在不同训练阶段的性能表现,具体包括:
MiniOneRec-Scratch: 基于随机初始化的 LLM 权重训练,不做任何 SID - 文本对齐任务。
MiniOneRec- W/O ALIGN: 基于预训练 LLM 进行后训练,不做任务 SID - 文本对齐。
MiniOneRec: 基于预训练 LLM 进行后训练,并进行全流程的 SID 对齐。
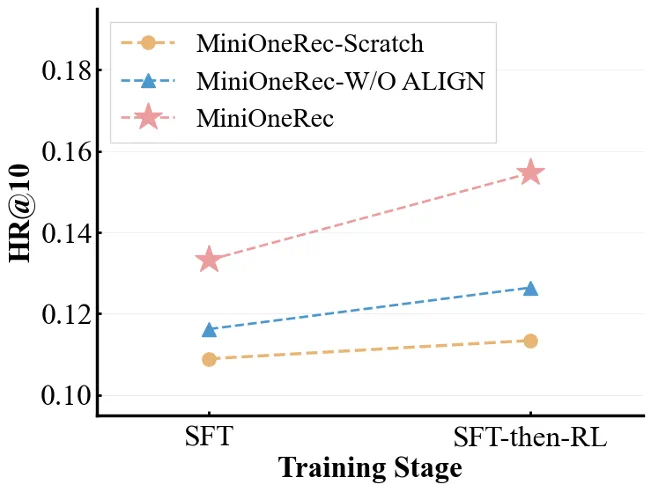
图 3. 世界知识对于生成式推荐性能的影响。
结果显示,基于预训练 LLM 初始化并进行语义对齐的 MiniOneRec(红线)始终优于未充分对齐的对应变体(黄 / 蓝线)。这表明预训练 LLM 已具备的通用序列处理能力和世界知识,为推荐任务带来了显著的额外收益。
基于此发现,MiniOneRec 将 SID token 添加至 LLM 词表,并在 SFT 和 RL 阶段共同优化推荐与对齐两大任务,将 LLM 语言空间与 SID 信号紧密对齐。
(3)独家优化:面向推荐的强化学习策略
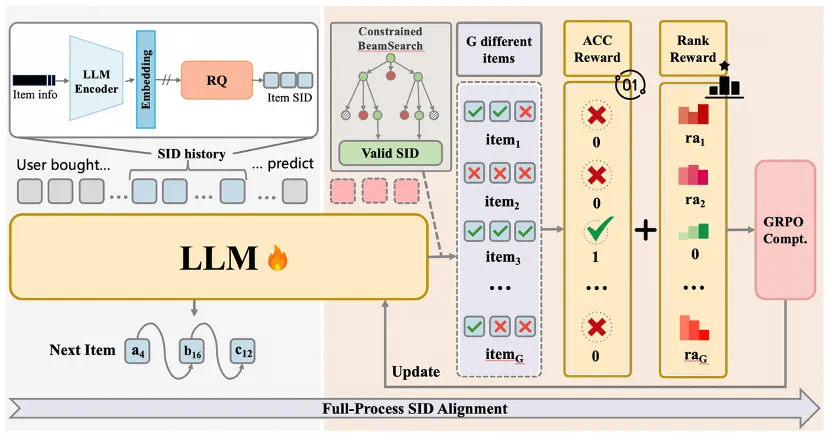
图 4. MiniOneRec 框架。
MiniOneRec 基于 GRPO, 进一步实现了面向推荐的强化学习算法,具体包括
面向推荐的采样策略
由于采取 Constrained-Decoding 策略规范模型生成合法 SID,模型的输出被限制在远比自然语言狭窄的有限空间。随着强化学习训练的深入,传统采样策略的熵迅速降低,使得模型在多次采样时容易反复生成相同的冗余物品,导致优化效率低下。基于这个发现,MiniOneRec 替换常规采样策略为 Constrained Beam-Search,高效生成多样化的候选物品,兼顾采样效率和对负样本的曝光率。
面向推荐的奖励塑造
推荐场景用户交互稀疏,常规的二元奖励使得负样本 “坍缩” 为同一奖励值,使得强化学习监督信号粒度粗糙。MiniOneRec 在准确性奖励之外,创新性引入排名奖励,对于高置信度 “困难负样本” 施加额外惩罚,从而强化排序信号的区分度。
开源基准测试全面领先
在同一 Amazon 基准上,研究人员将 MiniOneRec 同当前 SOTA 的传统推荐范式、生成式推荐范式、基于大模型的推荐范式进行了全面对比。
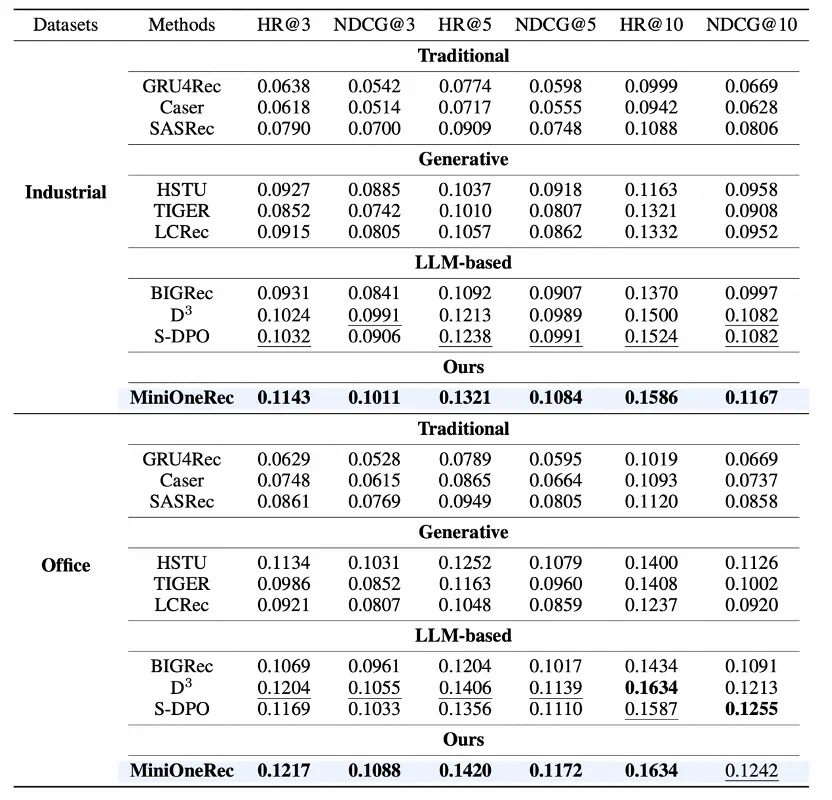
图 5. MiniOneRec 同传统推荐、生成式推荐、LLM 推荐性能对比。
结果显示,MiniOneRec 展现出全面的领先优势:
在 HitRate@K 和 NDCG@K 两项推荐指标上,MiniOneRec 始终显著优于以往的传统推荐范式与生成式推荐范式,领先 TIGER 约 30 个百分点。而对于基于大模型的推荐范式,MiniOnRec 呈现总体的领先的同时拥有显著的上下文 token 优势。
这表明,生成式推荐作为可能的下一代推荐范式拥有显著潜力。
4. 生成式推荐的展望与思考:
生成式推荐会成为下一代推荐系统的新范式吗?这个问题似乎还难以有一个定论。
一方面,以美团 MTGR、淘天 URM 等为代表的推荐系统 “改革派”,利用生成式架构的长序列建模等能力赋能判别式,在现有的体系内基于 “生成式召回” 方案进行增量改进。
另一方面,以快手 OneRec 为代表的更为激进的 “革命派”,则想要直接颠覆传统多阶段级联的判别式方案、实现真正端到端自回归地生成用户兴趣列表。
虽然两条路线取舍不同,但都在规模化实践中验证了生成式范式的实际价值。对部分大厂而言,生成式范式已经走出 “可行性验证” 阶段,开始在业务上创造真实收益。相较于业界的快速推进,学术界与开源社区在这一方向仍显薄弱。面对这场可能重塑推荐技术版图的机遇,我们期待更多研究者与工程实践者大胆尝试,拥抱这或许是推荐领域的 “GPT 时刻”。