 论文标题:
论文标题:
CCFQA: A Benchmark for Cross-Lingual and Cross-Modal Speech and Text Factuality Evaluation(AAAI 2026)
论文链接:
https://arxiv.org/pdf/2508.07295
仓库链接:
https://github.com/yxduir/ccfqa
数据集链接:
https://huggingface.co/datasets/yxdu/ccfqa
1.引言
随着多模态大语言模型(MLLMs)在多语言环境中的日益普及,确保无幻觉的事实准确性变得尤为重要。然而,现有评估可靠性的基准主要集中在以英语为主的文本或视觉模态,这导致在处理多语言输入(尤其是语音)时存在评估空白。为弥补这一不足,哈尔滨工业大学社会计算与交互机器人研究中心知识计算组和鹏城实验室数据智能研究所联合发布跨语言跨模态事实性基准(CCFQA),以推动具备更可靠语音理解能力的MLLMs发展。该基准包含涵盖8种语言的平行语音-文本事实问答数据集,旨在系统评估MLLMs的跨语言与跨模态事实性一致性能力。实验结果表明,当前多模态大语言模型在CCFQA基准上仍面临显著挑战,尤其是在多语言语音问答任务中表现有待提升,模型对语音与文本输入的回复存在明显不一致。针对MLLMs的跨语言与跨模态事实不一致问题,本文提出了一种基于少样本迁移学习的改进策略,旨在增强模型的事实准确性。该论文现已被AAAI 2026录用。
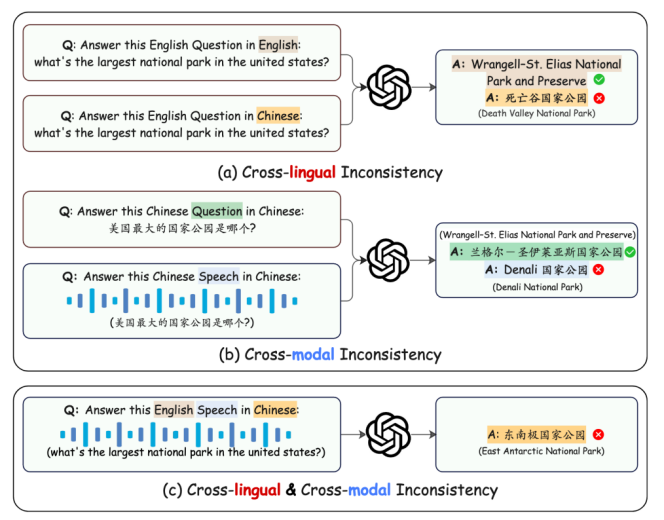
图1: MLLM中的事实性不一致:(a) 对同一问题,不同语言回复的答案不一致;(b) 对同一问题,不同模态输入的答案不一致。
2.CCFQA基准介绍
2.1事实性基准
事实性基准作为评幻觉的有效工具受到越来越多关注。如表 1所示,当前基准侧重于文本或视觉输入,且主要针对英语设计,缺乏对多语言语音场景的覆盖。目前仍然缺少用于评估多语言语音设置下模型事实性的综合基准。
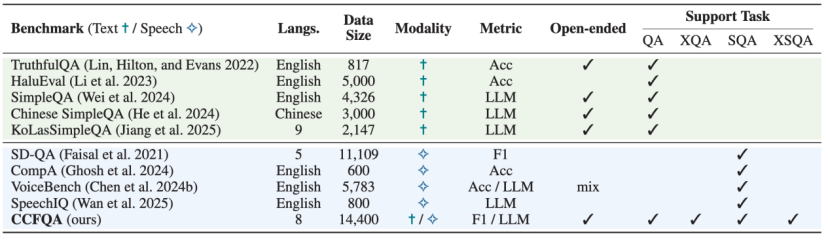
表1: CCFQA与已有基准对比
2.2 CCFQA介绍
为了弥补多语言语音幻觉检测空白,研究团队提出了跨语言和跨模态事实性基准(CCFQA),系统评估MLLM在跨语言和跨模态场景中的事实知识一致性。CCFQA基准的独特之处在于,每个事实性问题都以文本和语音两种输入形式呈现,旨在评估MLLM在不同语言和输入模态之间的一致性:
l跨语言一致性:模型能否在多种语言中产生等效的答案?
l跨模态一致性:模型能否在文本和语音输入之间保持答案质量?
该基准包含8种语言的平行语音-文本事实性问题:英语、中文普通话、法语、日语、韩语、俄语、西班牙语、港式粤语。

表2: CCFQA样本示例
研究团队从MKQA和MOOCCubeX数据集中收集原始英文问答文本,经过翻译和真人录制,最终构建了包含14,400个语音和文本问题样本的高质量数据集,涵盖20个不同领域知识类别。
CCFQA基准支持四种任务设置:多语言文本问答(QA)、跨语言文本问答(XQA)、多语言口语问答(SQA)、跨语言口语问答(XQA)。

图2: CCFQA数据集统计
3.少样本迁移学习策略
为了提高MLLM在事实知识方面的一致性,研究团队提出了一种基于英语作为枢纽语言的策略,以弥合跨语言问答中的知识鸿沟。该方法采用了一种简洁而有效的端到端流程:首先将非英语问题翻译成英语,然后利用LLM在英语语境下强大的事实推理能力生成答案,最后将答案翻译回目标语言。实验表明,该方法仅需使用5样本进行跨语言语音问答训练,即可实现多语言语音问答功能,显著提升了MLLM的事实一致性和可靠性。
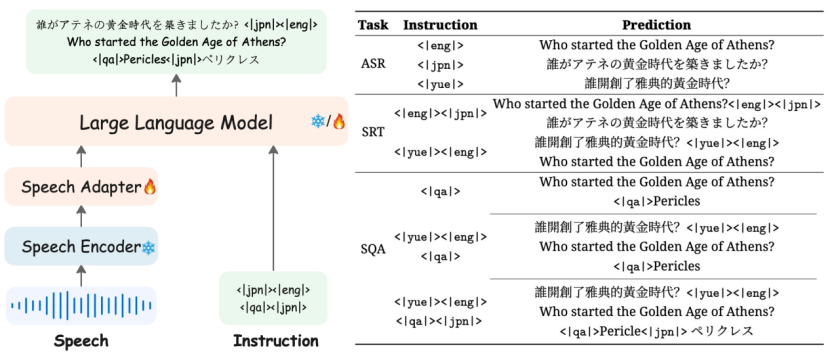
图3: 少样本迁移学习策略
4.实验
系统评估表明,现有MLLM在跨语言和跨模态的事实知识方面存在显著不一致。即使是简单的问题,模型在同一查询以不同语言或模态呈现时,也经常产生矛盾的答案,这凸显了在多样化输入下保持事实一致性的难度。
实验结果显示,当前多模态大语言模型在 CCFQA 基准上仍面临严峻挑战,尤其在跨语言和跨模态场景中,模型性能显著下降。实验对比了包括 GPT-4o-mini-Audio、Qwen2.5-Omni 等当前效果最佳的多模态大语言模型。结果表明,当前主流多模态大语言模型在多语言语音问答任务中,普遍存在相比文本模态明显的性能不一致问题。
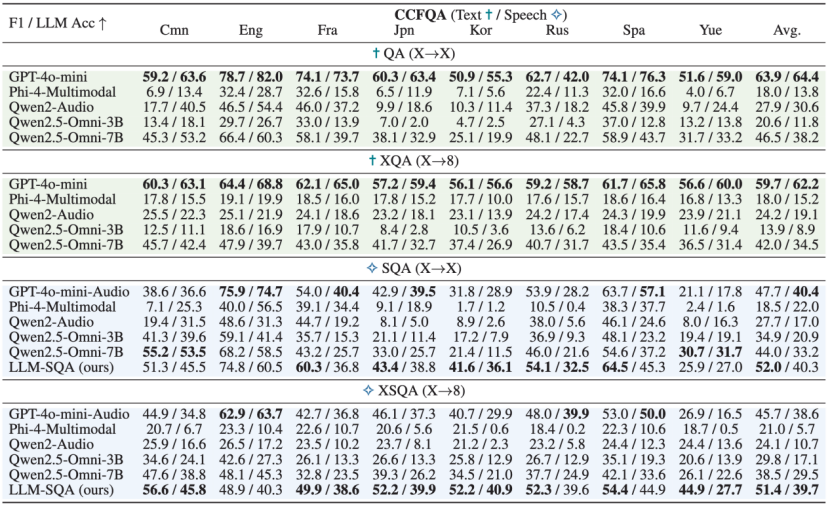
表3: MLLMs在4个任务上的F1和LLM评估得分
5.总结
本研究针对多模态大语言模型在多语言语音中存在的事实性幻觉问题,提出了一个名为CCFQA的创新基准。该基准填补了现有评估体系在多语言语音模态上的空白,涵盖8种语言的平行语音-文本问答数据,支持跨语言与跨模态一致性评估。实验表明,当前MLLMs在应对不同语言和输入模态时存在显著的事实不一致性。后续的研究有待在提升提升模型在多语言与跨模态场景下的一致性,并探索更有效的抗幻觉方法。


