资讯列表

AI新功能震惊网友:轻松破解照片拍摄位置
近日,OpenAI 推出的 o3模型因其能够精准猜测照片拍摄位置而引发广泛关注。 这一功能由 Django Web 框架的创始人 Simon Wilson 首次测试,他在自己的博客中详细记录了 o3的推理过程,称这一体验既超现实又令人不安。 Wilson 随意拍了一张看似平常的照片,包含了些许道路和房屋,却没有明显的标志性建筑。
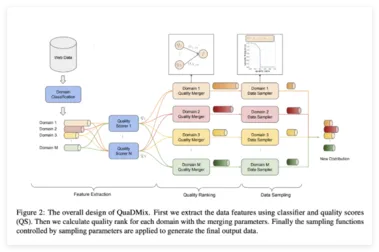
字节跳动推出 QuaDMix:大型语言模型预训练数据质量与多样性的统一框架
近日,字节跳动宣布推出其全新的数据选择框架 QuaDMix,旨在提升大型语言模型(LLM)预训练的效率和泛化能力。 众所周知,模型的训练效果受基础数据集的质量和多样性影响很大。 然而,传统的数据筛选方法往往将质量和多样性视为两个独立的目标,先进行质量过滤,再进行领域平衡。

Adobe 重磅升级 Firefly AI 平台,打造图像、视频、音频全能创作引擎
Adobe 最近宣布对其 Firefly AI 平台进行重大升级,这一变化使其从一个独立的图像生成器转变为一个综合性数字内容创作系统。 自两年前推出以来,Firefly 已被全球用户用来创建超过220亿个资产,这一最新版本旨在在这一成功基础上,提供更为多样化的创作工具。 新版本的 Firefly 现在支持生成图像、视频、音频和矢量图形。

马斯克的 xAI Holdings 计划融资 200 亿美元 目标市值超 1200 亿美元
据报道,埃隆・马斯克的 xAI Holdings 正在与投资者洽谈,计划融资200亿美元。 这一融资如果成功,将使该公司的估值超过1200亿美元,并将成为历史上第二大融资轮,仅次于上个月 OpenAI 的400亿美元融资。 据《彭博社》消息,这一谈判目前处于 “早期阶段”。

谷歌被曝每月巨资贿赂三星,助推 Gemini 应用预装
近日,谷歌在反垄断审判中陷入了新的风波。 据报道,谷歌每月向三星支付巨额资金,以促使其在 Galaxy S25系列智能手机中预装 Gemini 人工智能应用。 这一消息引发了广泛关注,尤其是在谷歌被指控违反反垄断法后,这种商业行为是否构成新的不当竞争仍待观察。
夸克AI超级框升级 “拍照问夸克” 功能,开启智能视觉搜索新时代
夸克 AI 超级框正式推出全新的 AI 相机功能 ——“拍照问夸克”,旨在通过视觉理解与推理技术,革新用户的搜索体验。 这一新功能为用户在工作、学习和日常生活中提供了更高效的方式来获取信息,进一步提升了夸克 AI 的多模态能力。 在日常使用中,用户往往难以用文字清晰描述自己的需求,尤其是面对复杂的物体、表格或图形。

Meta与英伟达、惠普联手打造太空AI项目 “Space Llama”
在最新的科技突破中,Meta 宣布与英伟达和惠普合作推出名为 “Space Llama” 的人工智能项目。 该项目旨在为国际空间站国家实验室的宇航员研究提供支持,利用 AI 技术帮助他们在太空环境中进行更高效的工作。 “Space Llama” 项目的核心目标是降低成本,减少计算需求,并能够快速响应宇航员在太空中遇到的各种问题。

一文了解人工智能代理的开源堆栈
我记得一个周末,我坐下来,确信自己终于可以构建一个像样的研究助理代理原型了。 没什么特别的——只是能读取 PDF 文件、提取关键信息,或许还能回答一些后续问题而已。 应该很简单,对吧?

AR智能革命!Satori系统读懂人类意图,科幻电影场景成现实
团队由 IEEE 会士,纽约大学教授 Claudio Silva 和纽约大学研究助理教授钱靖共同指导。 论文由Chenyi Li和Guande Wu共同第一作者。 在无数科幻电影中,增强现实(AR)通过在人们的眼前叠加动画、文字、图形等可视化信息,让人获得适时的、超越自身感知能力的信息。

特朗普新行政命令,要求全美国学校教AI
美国白宫官网消息,特朗普发布了新的行政命令——《推动美国青少年的AI教育》特朗普要求全美国的K12(从幼儿园到高中)学校的老师、学生深度学习、使用AI,为下一世代的工作方式、创造力培养人才奠定竞争基础。 以下是美国白宫的原文内容。 根据美利坚合众国宪法和法律赋予我作为总统的权力,现命令如下:为什么颁发此命令AI(人工智能)正在迅速改变现代世界,推动各行业的创新,提高生产力,并重塑我们的生活和工作方式。

微软发布2025工作趋势:每位员工将是Agent老板
微软在官网发布了2025年工作趋势指数报告,主要分析了来自中国、美国、澳大利亚、巴西、加拿大等全球31个国家/地区的31,000家企业。 同时结合了Linked劳动力市场趋势,数万亿个Microsoft365生产力信号,以及原生初创企业、学者、经济学家、科学家和思想领袖的意见。 结果显示,由Agent智能体 人类的“人机协作”模式正在重塑企业架构,一种全新形态的“前沿公司”诞生。

7x24小时非人类科学家入场:当AI开始自主探索科学未知领域 | 多伦多大学
自主通才科学家(AGS)正成为现实! 来自多伦多大学、IIT、清华大学、浙江大学、罗格斯大学、哈佛大学、佐治亚理工学院和伦敦大学学院的跨学科团队的最新研究指出,融合人工智能与机器人技术的“自主通才科学家(AGS)”不仅能独立完成从文献综述到实验验证的全流程,更可能以指数级速度推动科学发现,突破人类能力的物理与认知边界。 除此之外,其团队还构建了将AI大脑与机器人躯体深度融合的通用科研系统概念框架,展示了机器人与AI科学家在自然科学、形式科学、应用科学、人文科学,以及跨学科科学等全科学领域的原创性发现的潜力。

1亿图文对!格灵深瞳开源RealSyn数据集,CLIP多任务性能刷新SOTA
新的亿级大规模图文对数据集来了,CLIP达成新SOTA! 格灵深瞳最新发布的高质量数据集RealSyn,不仅规模大——包含1亿组图文对,而且每张图片都同时关联多个真实和合成文本。 所有的图像和句子都基于冗余进行了严格过滤,在确保数据质量的同时,引入基于簇的语义平衡采样策略,构建了可满足多样工作需求的三种规模大小的数据集:15M、30M、100M。

OpenAI没说的秘密,Meta全揭了?华人一作GPT-4o同款技术,爆打扩散王者
GPT-4o生成的第一视角机器人打字图这次,来自Meta等机构的研究者,发现在多模态大语言模型(MLLMs)中,视觉词表存在维度冗余:视觉编码器输出的低维视觉特征,被直接映射到高维语言词表空间。 研究者提出了一种简单而新颖的Transformer图像token压缩方法:Token-Shuffle。 他们设计了两项关键操作:token混洗(token-shuffle):沿通道维度合并空间局部token,用来减少输入token数;token解混(token-unshuffle):在Transformer块后解构推断token,用来恢复输出空间结构。

智能体 Agent 与工作流构建实战指南:从选型决策到高效实施
作者 | fred历经多个业务系统的构建,我深感Anthropic的《Build effective agents》一文与自身实战经历高度契合。 本文在详解工作流与Agent的技术选型标准、设计模式应用及实施要点的同时,也融入了我的实战心得与实践经验总结。 无论您正考虑构建工作流系统还是Agent系统,都能在此找到适合场景的最佳实践方案。

毛骨悚然!o3精准破译照片位置,只靠几行Python代码?人类在AI面前已裸奔
OpenAI的o3发布以来,这个功能让不少网友觉得毛骨悚然——它能准确破解你的地理位置! 就在刚刚,Lanyrd联创、Django Web框架缔造者Simon Wilson专门发了一篇博客,详尽推敲了o3究竟是如何猜测照片拍摄地点的。 他将整个过程评价为:既超现实,又反乌托邦,仿佛几十年前的科幻小说突然变成现实!

一行代码不用写,AI看论文自己「生」出代码库!科研神器再+1
这几年,AI领域的科研人员遇到一个问题。 那就是机器学习的论文实在是多到看不过来,更别说还要用代码实现论文中逻辑。 HuggingFace上的「每日论文」板块每天都有十几篇新出的研究论文这导致一个问题,研究者往往「重视结果」而没有精力来用用代码验证,并且复现很多先前的工作有点「重复造轮子」,浪费研究者的精力。

理解 RAG 第五部分:管理上下文长度
传统的大型语言模型 (LLM)存在上下文长度限制,这限制了单次用户与模型交互中处理的信息量,这是其主要局限性之一。 解决这一限制一直是 LLM 开发社区的主要工作方向之一,提高了人们对增加上下文长度在生成更连贯、更准确响应方面优势的认识。 例如,2020 年发布的 GPT-3 上下文长度为 2048 个 token,而其更年轻但功能更强大的兄弟 GPT-4 Turbo(诞生于 2023 年)允许在单个提示中处理高达 128K 个 token。