资讯列表
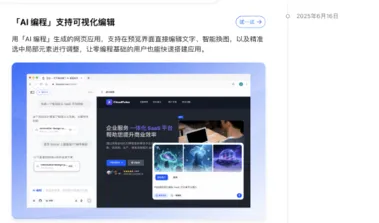
告别代码恐惧症!豆包推出可视化AI编程,拖拽即可创建网页应用
字节跳动旗下AI助手豆包近日推出重磅功能更新,其AI编程"应用创造1.0"正式上线,为用户带来了前所未有的可视化编程体验。 豆包在6月16日的官方更新日志中宣布,"AI编程"功能已支持可视化编辑。 这一创新功能允许用户在生成网页应用后,可以直接在预览界面进行编辑操作,包括修改文字内容、智能更换图片,以及精准选择局部元素进行调整,操作便捷程度堪比编辑PPT文档。

LinkedIn 上的 AI 岗位激增,个人资料中 AI 技能添加量激增二十倍
近日,LinkedIn 首席执行官瑞安・罗斯兰斯基(Ryan Roslansky)表示,该平台上提到 AI 的职位招聘数量在过去一年中增长了六倍。 同时,用户在个人资料中添加 AI 技能的数量则呈现出更加显著的增长,增加了整整二十倍。 这一变化表明,越来越多的专业人士开始重新塑造自己的职业形象,将 AI 相关技能纳入其中,尽管他们的实际经验可能并不丰富。
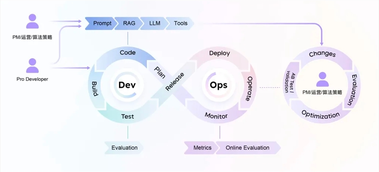
火山引擎推出企业AI中台HiAgent 2.0 引入Agent DevOps理念
近日,火山引擎正式宣布推出企业AI中台HiAgent2.0,旨在解决Agent应用开发在真实商业环境中的实际需求与痛点,助力企业实现智能体从开发到运维的高效交付。 HiAgent2.0定位为企业AI中台,相比前代产品HiAgent1.0,在功能上实现了四大维度的扩展。 向上,HiAgent2.0提供了更多行业场景模板与丰富插件市场,大幅降低了智能体搭建的门槛;向下,它融合了多模型管理与模型后训练工具链,实现了“模应一体”的效果优化;向右,新增了智能体运营运维、高低代码混合开发能力,覆盖了智能体的全生命周期管理;向左,则发布了Canvas统一人机交互入口,让智能体以“数字同事”的身份更好地融入企业业务。

任务太难,连ChatGPT都弃了!最强AI神器一键拆解,首测来袭
想转型AI做产品经理,却不知如何入手? 想搞副业月入一万,但脑子里只有零散想法? 想知道AI时代该学什么专业最有前景?

LLM进入「拖拽时代」!只靠Prompt,几秒定制一个大模型,效率飙升12000倍
现在的大模型基本都具备零样本泛化能力,但要在真实场景中做特定的适配,还是得花好几个小时来对模型进行微调。 即便是像LoRA这样的参数高效方法,也只能缓解而不能消除每个任务所需的微调成本。 刚刚,包括尤洋教授在内的来自新加坡国立大学、得克萨斯大学奥斯汀分校等机构的研究人员,提出了一种全新的「拖拽式大语言模型」——Drag-and-Drop LLMs!

别做 ChatGPT 竞品!Sam Altman 给 AI 企业划“禁区”:这块我们有“护城河”
在Y Combinator 最近在旧金山举办的 AI Startup School 活动中,OpenAI CEO Sam Altman 接受了Garry Tan的采访。 他在台上说:“别去做我们要做的那个 ChatGPT。 ”图片Altman 没有拐弯抹角,清楚说出:“我们要做的事情,就是把 ChatGPT 打造成最好的超级助理。

亚马逊Alexa+内测用户突破百万,生成式AI赋能重塑智能助理体验
亚马逊的下一代数字助理服务 Alexa 正加速推进其内测,目前用户数量已突破100 万大关。 这项在今年 2 月首次亮相的生成式人工智能驱动的服务,旨在通过提供更自然、个性化的互动、智能家居集成及扩展功能,彻底改变数字助理的用户体验。 尽管Alexa 尚未全面公开发布,亚马逊正通过邀请那些在候补名单上注册的用户进行测试。

火山引擎推出 AI 智能推荐域名,助力企业轻松找域名!
在数字化时代,拥有一个合适的域名对于企业的在线形象至关重要。 近期,火山引擎宣布推出基于方舟大模型的 “AI 智能推荐域名” 服务,这一创新功能通过自然语言处理和语义解析技术,帮助企业快速生成高相关性的域名组合,极大优化了域名注册的流程。 这项新服务的亮点在于其智能化的推荐机制。

Perplexity 联合创始人承诺出资 1 亿支持 AI 研究
计算机科学家、Databricks 和 Perplexity的联合创始人安迪・孔维斯基(Andy Konwinski)宣布,他将投入1亿美元,成立一个新型研究基金,以支持人工智能(AI)领域的研究人员。 这个新的基金已经获得了 Ion Stoica 新实验室的支持,标志着孔维斯基对 AI 研究的重视和投入。 安迪·康温斯基 (Andy Konwinski) 周一宣布,他的公司 Laude 正在组建一个新的人工智能研究机构,由他自己的1亿美元资金支持。

3D VLA新范式!中科院&字节Seed提出BridgeVLA,斩获CVPR 2025 workshop冠军!
只需要三条轨迹,就能取得 96.8% 的成功率? 视觉干扰、任务组合等泛化场景都能轻松拿捏? 或许,3D VLA 操作新范式已经到来。

OpenAI硬件陷“抄袭门”,商标/设计极其相似,官方火速删帖
才官宣1个月,奥特曼未出世的AI硬件,已陷入“抄袭门”。 最新消息,OpenAI斥64亿美金收购的AI硬件公司IO,因商标、产品设计侵权等问题,被告上法庭。 原告是IYO,2021年从Google X孵化成立,主营下一代“无屏幕语音计算设备”。

细节控!即梦灰测图片3.1模型 电影感增强,风格化艺术感更强
昨日晚间,即梦悄悄灰测了图片3.1模型。 相较于3.0版本,3.1模型生成的图片电影感和故事感更强,场景更丰富。 对于一些艺术类的提示词响应效果也更好了。

从文本生成到指令编辑 OmniGen2重塑开源多模态模型应用场景
近日,VectorSpaceLab在Hugging Face平台正式开源全能多模态模型OmniGen2,以创新性双组件架构和强大的视觉处理能力,为研究者和开发者提供了高效的可控生成式AI基础工具。 这款模型由30亿参数的视觉语言模型(VLM)Qwen-VL-2.5与40亿参数的扩散模型组合而成,通过冻结的VLM解析视觉信号和用户指令,结合扩散模型实现高质量图像生成,在视觉理解、文本生成图像、指令引导图像编辑和上下文生成四大核心场景中展现出领先性能。 作为开源项目,OmniGen2的视觉理解能力继承自Qwen-VL-2.5的强大基础,可精准解析图像内容;其文本生成图像功能支持从文本提示生成高保真、符合美学标准的图像;在指令引导图像编辑领域,该模型以高精度完成复杂修改任务,性能达到开源模型中的前沿水平;而上下文生成能力更可灵活处理人物、物体、场景等多元输入,生成连贯新颖的视觉输出。

Salesforce 发布 Agentforce 3:实现 AI 代理实时监控 MCP 支持
近日,Salesforce 推出了其 AI 代理平台的重大升级 ——Agentforce3,旨在帮助企业更好地应对在大规模部署数字化工作者时面临的主要挑战。 此次更新引入了一个全新的 “指挥中心”,使高管能够实时监控 AI 代理的表现,同时支持多种互操作性标准,允许代理与数百种外部业务工具无缝连接,而无需进行定制编码。 根据 Salesforce 的数据,过去六个月中,AI 代理的使用量激增了233%,已有超过8000家客户注册使用这一技术。

谷歌 Google Cloud 向 Linux 基金会捐赠 A2A 智能体交互协议
Google Cloud 在 A2A 领域的下一步是通过与外部合作,制定一套更广泛的开放标准,丰富 A2A 协议的功能集。
微软发布创新小参数模型Mu:性能比肩Phi-3.5-mini,赋能Windows智能体
今天凌晨,微软正式发布了其最新创新小参数模型Mu。 这款模型参数仅为3.3亿,却在性能上能与微软此前发布的Phi-3.5-mini相媲美,而其体量仅为Phi-3.5-mini的十分之一。 更令人瞩目的是,Mu在离线NPU笔记本设备上能实现每秒超过100个token的响应速度,这在小参数模型领域是极为罕见的突破。

ElevenLabs隆重推出AI语音助理11ai:语音优先并支持集成MCP
ElevenLabs正式发布其全新语音优先AI个人助理11ai,标志着语音AI技术在生产力工具领域的又一重大突破。 作为一家以创新文本转语音和对话AI技术闻名的公司,ElevenLabs此次推出的11ai不仅集成了前沿的语音交互功能,还通过多工具集成和自定义MCP(多通道协议)支持,为用户提供了高度个性化的工作流体验。 语音优先,生产力为核心11ai以语音交互为核心设计,旨在通过自然、流畅的对话提升用户的工作效率。

OpenAI惊爆抄袭丑闻?65亿美元收购Jony Ive公司IO,背后暗藏IYO智能耳塞技术之争!
近日,人工智能领域掀起了一场轰动性的争议风暴。 谷歌X实验室分拆出来的初创公司IYO指控OpenAI及其首席执行官Sam Altman涉嫌抄袭其智能耳塞技术,并通过以65亿美元收购Jony Ive的公司IO,试图掩盖这一行为。 IYO指控:OpenAI涉嫌窃取智能耳塞技术IYO是一家自2018年起专注于研发人工智能驱动智能耳塞的初创公司,其产品旨在通过语音控制和无屏幕交互技术,取代传统智能设备。