P1团队 投稿量子位 | 公众号 QbitAI
开源模型首次在国际物理奥林匹克竞赛夺金了。
来自上海AI Lab的P1-235B-A22B取得了21.2分的成绩,成功跨越金牌线。
在覆盖2024-2025年全球13场顶级物理竞赛的HiPhO基准测试中,P1-235B-A22B获12金1银,与谷歌Gemini-2.5-Pro并列奖牌榜第一。
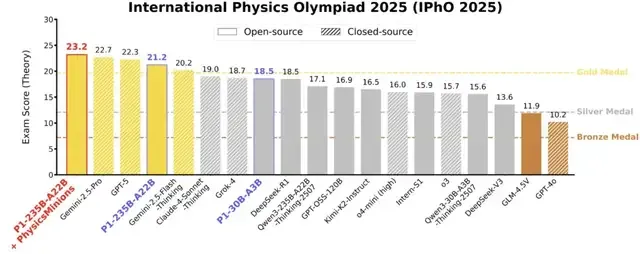
这个成绩超越了GPT-5的11金以及Grok-4的10金,标志着开源模型在物理推理能力上已经达到甚至超越闭源模型的水平。
同时,团队提出的协同进化多智能体系统PhysicsMinions,在IPhO 2025及HiPhO综合得分上双双问鼎,展现了“模型+系统”框架在应对复杂科学问题的卓越潜力。
物理推理是理解与塑造现实世界的核心能力。国际物理奥林匹克(IPhO)等顶尖赛事,以其对复杂推理和深度物理理解的高标准,成为检验物理智能对现实认知能力的重要标尺。AI在此类竞赛中夺得金牌,不仅是实现通用物理智能道路上的关键里程碑,更表明模型已初步具备应对现实世界中复杂物理问题的潜力。
为了准确评估物理奥赛的表现,研究团队构建了HiPhO(High School Physics Olympiad)基准测试,这是首个专注于最新物理奥赛、采用人类对齐评估的基准。
HiPhO涵盖了2024-2025年最新的13场奥林匹克级别的物理竞赛,包括 IPhO、APhO、EuPhO 等国际和区域赛事。评估时采用官方评分标准,对答案和过程进行细粒度评分,与人类评审严格对齐,确保得分准确。由此,每个模型的考试得分可直接与人类选手以及金银铜牌分数线进行比较。

△HiPhO 基准测试概览,包含2024-2025年13场物理奥赛,覆盖国际和区域竞赛。
研究团队通过高质量的提取和标注流程,构建了包含数千条奥赛级别题目的训练数据集。每条数据均具有完整的上下文信息、可验证答案以及标准解题过程,用于强化学习训练。
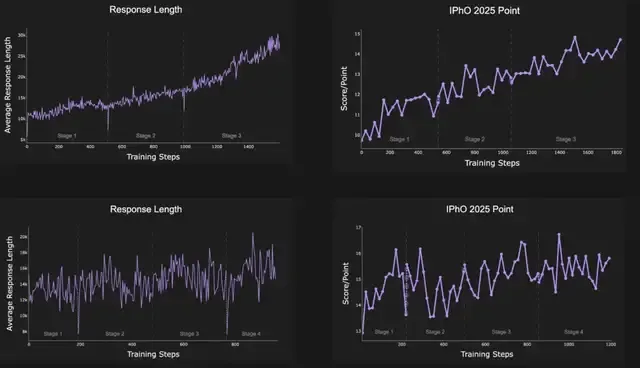
P1系列模型采用多阶段强化学习流程进行训练。为了实现稳定高效的训练,团队在每个阶段应用两项关键策略:
- 上下文窗口扩展:
- 随着训练的推进,逐步扩展模型最大生成长度,使模型能够探索更长的推理链。这种扩展提高了高复杂度问题的可解性,减少了因截断导致的错误。
- 通过率过滤:
- 在训练前,基于通过率统计对数据进行筛选,排除过于简单或过于困难的任务。
基于这种多阶段强化学习策略,P1模型实现了在基座语言模型的基础上长期、持续的性能提升
为了突破单模型的极限,研究团队开发了PhysicsMinions,这是一个专为物理推理设计的协同进化多智能体系统。它由三个交互式模块组成,通过自我验证与反思迭代,实现了物理推理能力的跃升:
- 视觉模块(Visual Studio)
- – 观察和验证多模态问题,提取结构化的视觉信息(在P1模型实验中未使用视觉模块)。
- 逻辑模块(Logic Studio)
- – 生成初始解决方案,并通过自我改进和自我反思逐步改进解答。
- 审核模块(Review Studio)
- – 执行双阶段验证:物理验证器检查物理一致性(比如常数、单位),而通用验证器检查逻辑、推理和计算。
如果任一阶段验证失败,详细的错误报告会被发送回逻辑模块,进行反思修订解答。通过这种协同进化协作,PhysicsMinions 持续提升复杂物理问题的推理质量和鲁棒性。
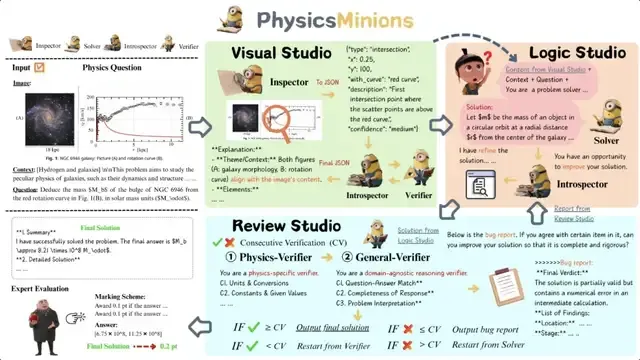
△PhysicsMinions 协同进化多智能体系统概览,展示了三个模块之间的交互流程。
下表总结了在 HiPhO 基准上所有竞赛的平均表现,展示出 P1 系列模型和多智能体系统的出色性能。
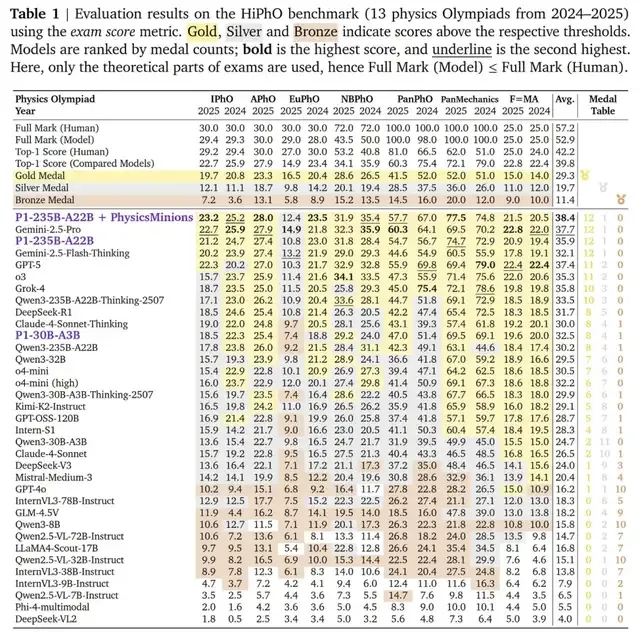
△P1 系列模型在 HiPhO 基准测试上的综合表现,包括与开源和闭源模型的对比。
P1-235B-A22B展现出卓越的物理推理能力,与Gemini-2.5-Pro和Gemini-2.5-Flash-Thinking并列第一,斩获12金1银,金牌数超越GPT-5(11金)、Grok-4(10金)和Claude-4-Sonnet-Thinking(8金)等主流闭源模型。
在IPhO 2025上,P1-235B-A22B得分21.2/30,成为首个也是唯一获得金牌的开源模型。
P1-30B-A3B在HiPhO基准上同样表现出色,获得8金4银1铜,在现有开源模型中排名第三。
仅次于参数规模更大的Qwen3-235B-A22B-Thinking-2507和DeepSeek-R1,甚至超越了o4-mini和Claude-4-Sonnet等闭源模型,突显了其在中等规模下的强大物理推理能力。
配备PhysicsMinions多智能体系统后,P1模型性能实现跨越式提升。P1-235B-A22B模型在 HiPhO 基准上取得了35.9分的平均得分,而配备 PhysicsMinions 后,其性能大幅提升至38.4分,在所有模型中取得综合第一,超越了Gemini-2.5-Pro(37.7)和 GPT-5(37.4)等顶尖闭源模型。
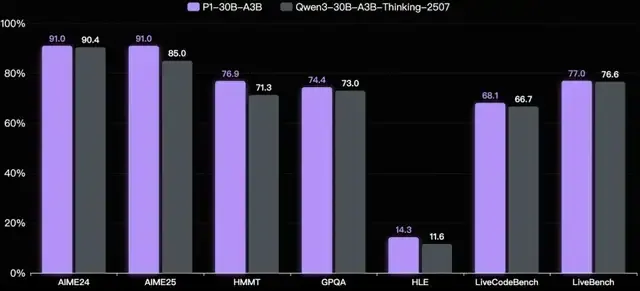
除了强大的物理推理能力,P1模型在多个领域的能力也得到进一步提升。如下图所示,P1-30B-A3B相比于基座模型Qwen3-30B-A3B-Thinking-2507,在数学、代码、STEM等基准测试上均取得显著优势,证明了物理推理能力的强大泛化性。
Project Page: https://prime-rl.github.io/P1Github: https://github.com/PRIME-RL/P1
HiPhO:论文:https://arxiv.org/abs/2509.07894数据集:https://huggingface.co/datasets/SciYu/HiPhO排行榜:https://phyarena.github.io/
PhysicsMinionshttps://arxiv.org/abs/2509.24855