本文的主要作者来自清华大学智能视觉实验室(i-Vision Group)、腾讯混元 X 组。本文的共同第一作者为清华大学自动化系本科生王嘉辉和博士生刘祖炎,本文的通讯作者为清华大学自动化系鲁继文教授。
多模态大模型通常是在大型预训练语言模型(LLM)的基础上扩展而来。尽管原始的 LLM 并不具备视觉理解能力,但经过多模态训练后,这些模型却能在各类视觉相关任务中展现出强大的表现。
这引发了我们的思考:在多模态训练过程中,LLM 基座的哪些内部结构,尤其是哪些多头注意力单元,真正承担了对视觉内容的理解?这些注意力头是否存在可识别、可量化的视觉偏好或专业化功能?如果能够识别出这些「视觉头」,不仅有助于揭示多模态大模型内部的「黑箱」机制,也为模型结构优化和资源分配提供了理论依据。
在本文中,我们聚焦于注意力头的视觉偏好,提出了一种基于 OCR 任务、无需额外训练的方法,系统量化每个注意力头对视觉内容的关注程度。我们发现,只有不到 5% 的注意力头(我们称之为视觉头,Visual Head)在视觉理解任务中起到主导作用,这些头能够有效聚焦并提取图片中的关键信息,而绝大多数注意力头则主要关注文本信息或其他辅助特征。这一「视觉头稀疏性」现象表明,模型的视觉理解能力高度依赖于极少数专门化的注意力头。

论文标题:SparseMM: Head Sparsity Emerges from Visual Concept Responses in MLLMs
论文:https://arxiv.org/abs/2506.05344
代码:https://github.com/CR400AF-A/SparseMM
项目地址:https://cr400af-a.github.io/SparseMM/
基于这一发现,我们进一步提出了 SparseMM:一种利用视觉头稀疏性进行 KV-Cache 优化的策略。考虑到多模态大模型输入的视觉 token 远多于文本 token,带来了巨大的显存压力,我们对 KV-Cache 资源进行差异化分配。
具体地,SparseMM 将总缓存预算划分为三部分:一部分保障所有头的基本局部缓存,一部分按固定比例均匀分配,其余则根据视觉头得分优先分配给视觉头,从而在效率与性能之间取得更优平衡。
通过在 DocVQA、OCRBench、TextVQA、ChartQA、MMBench、GQA 等主流多模态基准上的广泛评测,SparseMM 相较于 SnapKV、AdaKV 等方法取得了更好的性能和效率的平衡。效率评估测试中实现了最高 1.87× 的解码阶段加速并降低了 52% 的峰值内存。此外,在极端缓存预算下,性能下降幅度更小,充分验证了基于视觉头的 KV-Cache 分配策略在效率-性能权衡上的优越性。
介绍
多模态大模型通过引入视觉编码器模块,使得原本不具备视觉能力的 LLM 能够在图文问答、文档理解等多种场景下表现出色。但是模型内部究竟是如何实现这一跨模态迁移的,仍然是一个「黑箱」问题。我们认为,在多模态大模型训练的过程中,部分注意力头逐渐特化为了「视觉头」,专门负责视觉信息的理解与交互。
在本文中,我们提出了一种基于 OCR 任务量化并识别视觉头(Visual Head)的方法,并基于此提出了 SparseMM——一种新颖的多模态模型推理加速方法。通过对视觉头的深入分析,我们发现视觉头在多模态大模型中占比很小。
也就是说,只有一小部分注意力头真正承担了对视觉内容进行深度理解并将其有效融入语言表征的核心任务,而大多数注意力头更多地关注语言信息,或仅局限于局部上下文建模,对图像内容的理解作用有限。
基于此,我们采用了一种注意力头级别的缓存分配机制,对更关注视觉内容的注意力头分配更多的缓存预算,以最大程度的保留视觉信息;对于不关注视觉内容的注意力头则分配较少的缓存预算,使它们关注最近邻的信息即可,从而实现了性能和速度的更优均衡。
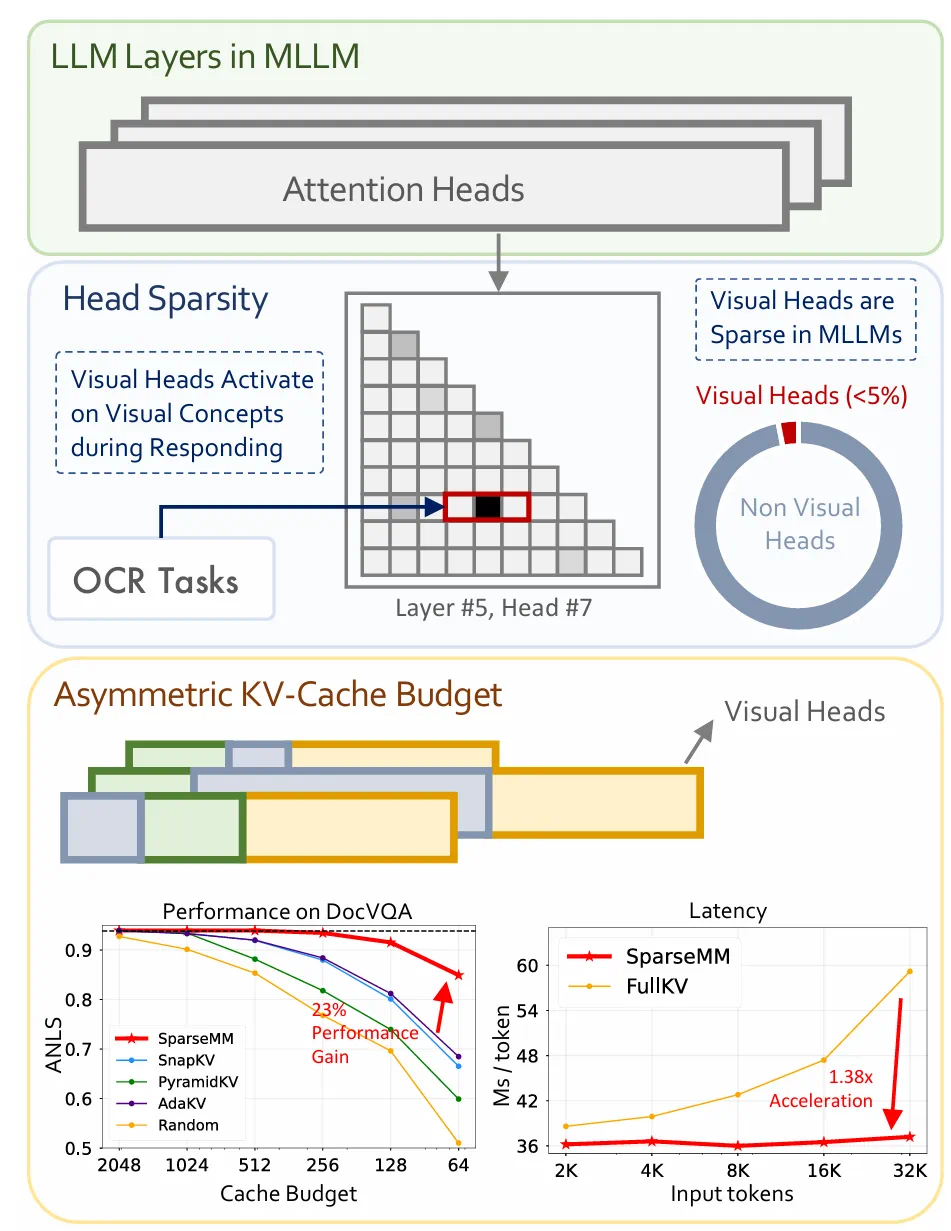
图 1:SparseMM 整体概览
方法概览
我们的方法主要分为两部分:首先通过 OCR 任务定位视觉头,然后为不同的注意力头分配不同的缓存预算。
基于 OCR 的视觉头定位方法

图 2:SparseMM 基于 OCR 任务定位视觉头的方法示意图
为了深入探究多模态大模型在处理视觉内容时的注意力机制,我们提出了一种基于 OCR 任务的分析方法,并据此定义了「视觉得分」,用于量化模型在视觉内容上的注意力表现。基于视觉得分,本文能够有效定位并分析模型内部对视觉内容高度敏感的注意力头。
具体而言,在给定一个 OCR 任务的图片输入时,多模态大模型需要根据图片内容生成并输出图片中的文字信息。对于每一个由模型输出的 token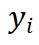 ,首先利用 OCR 任务的标注信息,即「(text, bbox)」对,明确该字符在图像中的空间位置。
,首先利用 OCR 任务的标注信息,即「(text, bbox)」对,明确该字符在图像中的空间位置。
通过这一标注,可以将每个字符与其在图片中的具体区域一一对应。接下来,按照多模态大模型对输入图片的分块或 patch 划分方式,进一步确定每个字符对应的视觉区域所映射到的视觉 token,并精确定位这些视觉令牌在整个输入序列中的具体位置。
在此基础上,我们对多模态大模型内部所有注意力头进行遍历。对于任意一个注意力头,我们分析其注意力得分矩阵。考虑当前字符 token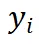 对前序所有输入 token 的注意力得分,若得分最高的 token 恰好属于该字符在图像中对应区域的视觉 token,则认为该注意力头在该位置成功「命中」了对应的视觉内容。每当发生一次「命中」,便为该注意力头累计一次视觉得分。通过统计和归一化所有字符令牌的命中情况,最终可以量化每个注意力头对视觉内容的关注程度,从而揭示模型在视觉信息处理过程中的内部机制。
对前序所有输入 token 的注意力得分,若得分最高的 token 恰好属于该字符在图像中对应区域的视觉 token,则认为该注意力头在该位置成功「命中」了对应的视觉内容。每当发生一次「命中」,便为该注意力头累计一次视觉得分。通过统计和归一化所有字符令牌的命中情况,最终可以量化每个注意力头对视觉内容的关注程度,从而揭示模型在视觉信息处理过程中的内部机制。

基于视觉头的 KV-Cache 压缩策略
在完成视觉头的定位之后,我们进一步提出了一种基于视觉头的 KV-Cache 分配与压缩策略。传统的 KV-Cache 机制为所有注意力头和所有位置的 token 分配等量的缓存空间,这种方式虽然简单,但在处理高分辨率图像时显得极为低效:大量不关注视觉内容的注意力头被迫缓存完整视觉 token,造成了显著的资源浪费。
为了解决这一问题,SparseMM 根据视觉得分设计了一个三部分的缓存分配机制:
Local Window Cache: 为所有注意力头分配固定窗口大小的缓存,只保留最近的若干个 token,确保基本的局部上下文建模能力;
Uniform-Based Cache: 在所有注意力头之间均匀分配一部分缓存预算,用于保底防止头部信息过度丢失;
Score-Preferred Cache: 将剩余的大部分缓存资源按照视觉头在前一阶段中的视觉得分按比例分配,使得关键的视觉头能够尽可能保留更多的历史视觉 token,从而提升模型对图像语义的保持能力。
这种差异化的缓存压缩策略在不显著牺牲模型性能的情况下,显著减少了整体 KV-Cache 的内存使用。尤其在视觉 token 占比较高的输入场景中,SparseMM 能够更合理地分配资源,把计算和存储集中在真正重要的视觉内容上。

图 3:SparseMM 基于视觉头的缓存压缩方法
实验结果
在 OCR-rich 的多模态数据集上的结果
在 OCR-rich 的数据集上(如 DocVQA、OCRBench 和 TextVQA),SparseMM 展现出显著的性能优势,充分验证了其视觉头识别策略的有效性。例如在 DocVQA 中,当键值缓存预算仅为输入长度的 10% 左右时,LLaVA-NeXT-Vicuna-7B 与 Qwen2-VL-7B-Instruct 等模型仍能保持与全缓存配置几乎一致的性能,而现有方法则普遍出现明显精度下降,差距在低预算下进一步扩大,突出体现了视觉头选择的准确性和关键性。TextVQA 中的实验同样验证了 SparseMM 的优势,多个模型在低至 5% 至 10% 缓存预算的条件下依然保持优异性能,显著优于 AdaKV、SnapKV 等方法。这些结果表明,SparseMM 尤其适用于文字密集、图文关联紧密的视觉任务,在处理高分辨率输入与稀疏文本分布场景中具备显著的推理效率与性能保持能力。

通用多模态任务上的分析
尽管本文的视觉头识别方法基于 OCR 任务构建,但是为了进一步验证其在更广泛视觉场景中的适用性与泛化能力,我们在多个通用视觉任务基准(如 MMBench、GQA 和 VQAv2)上对该方法进行了系统性评估。
实验结果显示,本文方法在通用视觉任务中依然表现出极强的鲁棒性与泛化能力。即便在非常受限的缓存预算的条件下,Qwen2-VL-7B-Instruct 模型在 MMBench 上仍能维持与全缓存模型几乎一致的性能;在 GQA 和 VQAv2 等具备复杂视觉推理能力要求的任务上,性能下降幅度也始终控制在 1% 以内,显著优于现有压缩方法。这些结果表明,尽管视觉头的识别基于 OCR 场景完成,其关注的视觉区域和注意力机制却具有高度的通用性,能够在各类视觉理解任务中稳定发挥作用,为通用多模态模型的推理加速与缓存优化提供了一种高效、可靠且可推广的解决方案。

推理速度评估
本文在不同输入长度(2K 至 32K)场景下评估了 SparseMM 的计算效率,结果显示该方法在提升推理速度和降低显存占用方面均取得显著提升。在 32K 输入下,LLaVA-NeXT-Vicuna-7B 和 Qwen2-VL-7B-Instruct 的推理速度分别提升至 1.87× 和 1.60×,而峰值显存占用分别减少约 15GB 和 2GB,表现出良好的扩展性与适应性。这充分说明 SparseMM 在高分辨率图像或长上下文任务中,能够有效降低推理开销,提升多模态大模型的部署效率与实用性。
可视化视觉头
我们可视化了 LLaVA-NeXT-Vicuna-7B 中识别到的一些视觉头和非视觉头,可以看出视觉头能准确的定位到图中的物体或文字,而非视觉头往往不关注图像信息或者关注到错误的区域,这直观地体现了视觉头和非视觉头的差异性。

总结
我们提出了 SparseMM,这是一种基于视觉头的 KV-Cache 缓存压缩方法。我们通过在 OCR 任务中精确识别出对视觉信息最敏感的注意力头,并据此设计差异化的缓存分配策略,在保证模型性能的同时显著降低了推理阶段的计算和内存开销。
实验结果表明,SparseMM 在多个视觉语言任务中均展现出卓越的准确性保持能力、优异的计算效率以及强大的泛化性,特别是在高分辨率图像和长上下文输入场景下具有显著优势。SparseMM 为多模态大模型的高效推理与实际部署提供了新的解决思路,我们也希望这项工作能启发未来更多对多模态大模型推理加速的研究。