本论文核心团队来自北京通用人工智能研究院机器学习实验室,团队负责人李庆博士长期从事多模态理解、多模态智能体、具身智能等方向,主页:https://liqing.io
近年来,人工智能正逐步从虚拟的互联网空间(Cyber Space)迈向真实的物理世界(Physical Space)[1]。这一转变的核心挑战之一,是如何赋予智能体对三维空间的理解能力 [2],实现自然语言与真实物理环境的对齐(grounding)。尽管已有的 3D 空间理解模型在视觉感知和语言对齐方面取得了显著进展,但它们普遍依赖于静态的世界的观察,缺乏对主动探索行为的建模。
针对这一问题,清华大学、北京通研院、北理工与北航的研究团队联合提出了一种统一空间理解与主动探索的新型模型。该方法使智能体能够在动态探索过程中逐步构建对环境的认知,从而实现更高效的空间感知与自主导航,为智能体在物理世界中的任务执行奠定了基础。这个工作已被 ICCV 2025 接收,所有审稿人一致给出满分评价。

论文标题:Move to Understand a 3D Scene: Bridging Visual Grounding and Exploration for Efficient and Versatile Embodied Navigation
论文链接:https://arxiv.org/abs/2507.04047
项目主页:https://mtu3d.github.io
代码链接:https://github.com/MTU3D/MTU3D
理解与探索:具身导航中的 “双面镜”
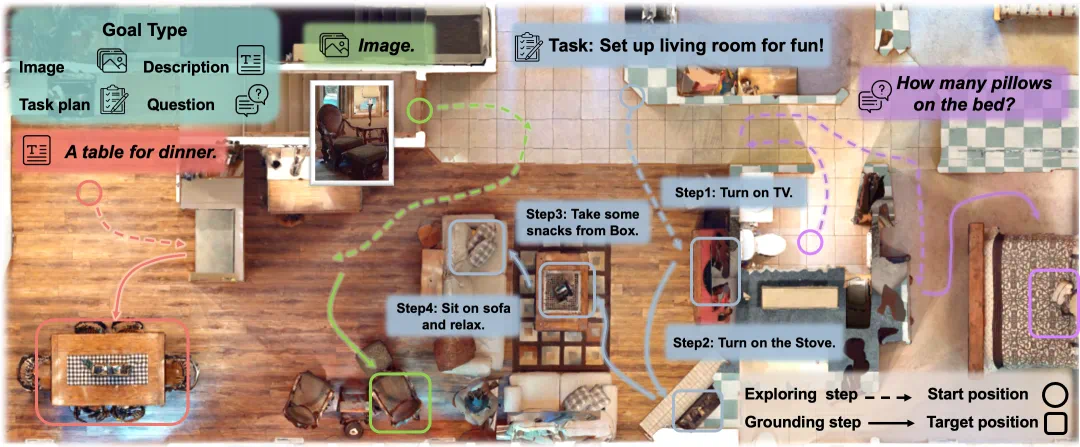
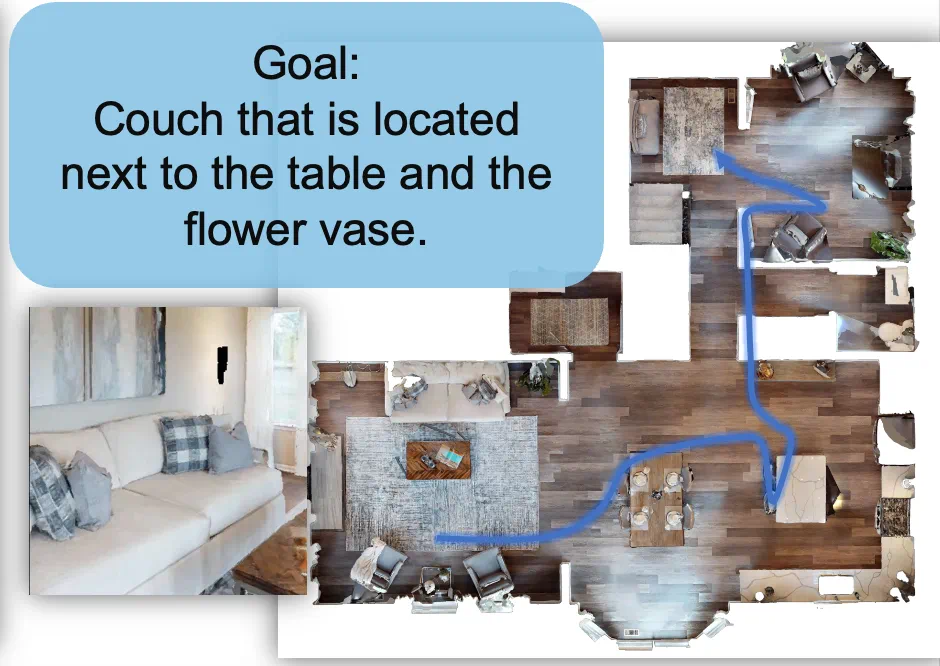
在具身导航(Embodied Navigation)任务中 [3],智能体需要根据人类的指令 —— 可能是一句话、一张图片、或者一个任务描述 —— 在复杂的物理空间中找到目标位置。它不仅要 “听懂任务”,还要 “会探索”,这正是空间理解和具身智能中的关键挑战。如下图所示,导航过程中其实包含两个交织进行的关键步骤:
理解(Grounding):智能体需要先理解指令在空间中具体指的是什么,比如 “去餐桌” 意味着它要找到与 “餐桌” 这个概念匹配的空间位置。
探索(Exploring):在还不完全了解环境时,智能体必须主动移动、观察和尝试,才能发现目标物品或区域。
这就像人类在空间中去导航一样,如果你想找吃的,可能会优先去厨房或餐厅看看 —— 这个 “方向感” 正是基于人对空间的理解。而真正找到零食,还需要你在厨房中主动探索。这说明,理解和探索不是两个独立的过程,而是互相推动、交替进行的。
研究难点:表征、训练目标和数据采集
实时语义表征:如何构建可在线更新的 3D 语义地图,既包含精确的空间位置,又融合丰富的语义信息,并能持续处理来自 RGB-D 流的数据?
探索-理解协同训练:如何将探索策略与语义理解统一在一个训练目标中联合优化,打破传统模块化方法中两者割裂的问题?
高效数据采集:如何降低真实世界导航数据采集的成本,利用虚拟与真实环境结合,构建自动化、可扩展的数据采集流程?
核心思路:探索和理解协同训练
如下图所示,作者将具身导航建模为一个探索与视觉落地(grounding)协同进行的闭环过程。
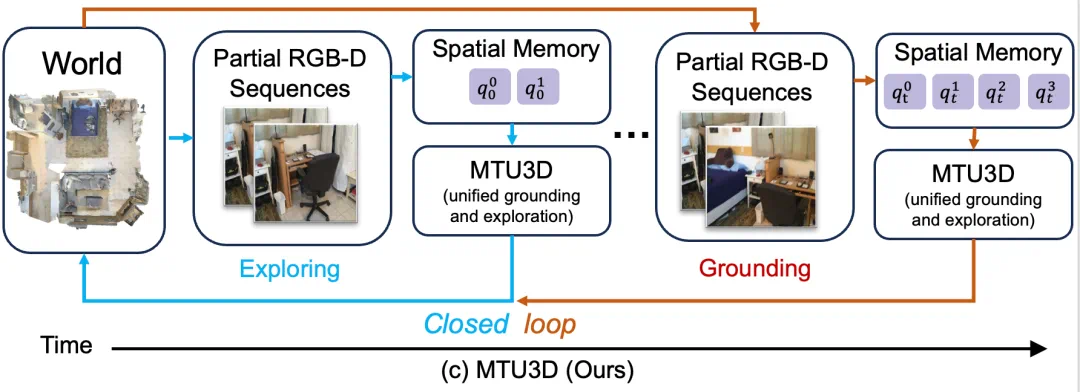
在探索阶段,智能体通过连续的 RGB-D 感知不断积累空间记忆,主动寻找潜在的目标位置。当空间记忆中包含了足够的视觉语义信息后,模型便进入视觉落地阶段 —— 根据语言指令对空间中的候选区域进行匹配,并导航至最符合语义的目标位置。
这种设计将强化学习方法中的主动探索能力与 3D 视觉语言模型的语义理解能力统一在一个闭环系统中。
探索推动理解的发生,理解又反过来引导更高效的探索,从而实现端到端的协同训练与任务执行。
模型设计和数据采集
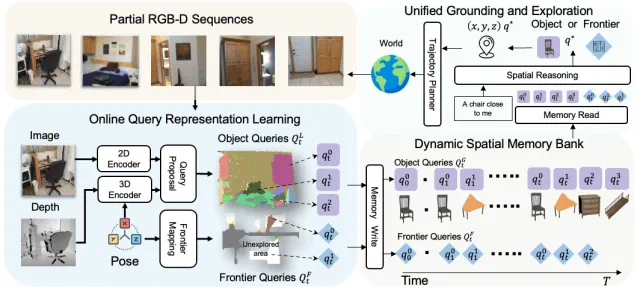
作者提出的模型主要包括两个核心模块:在线空间记忆构建与空间推理与决策,二者在统一训练框架下协同优化,实现探索与理解的闭环融合。
第一部分:在线空间记忆构建
在每一帧时刻,模型接收来自环境的局部 RGB-D 序列作为输入。每一张图像首先被分别送入 2D Encoder [4] 和 3D Encoder [5] 进行多模态特征编码:其中 2D Encoder 使用 FastSAM [6] 和 DINO 提取语义分割与视觉特征,3D Encoder 基于 Sparse Convolution UNet 提取稀疏体素级别的空间表示。
随后,这些多模态特征通过一个 Query Decoder 被转化为一组结构化的物体表示(Object Queries),涵盖每个物体的空间位置、体积大小、语义特征和置信度信息 [7,8]。
同时,系统还利用 Frontier-based Exploration [9] 方法识别尚未探索的空间边界区域,生成对应的 Frontier Queries(表示为 3D 空间坐标点)。
最终,上述物体与边界信息被写入一个随时间持续更新的动态空间记忆库(Dynamic Spatial Memory Bank),为后续的推理与决策提供结构化空间知识。
第二部分:空间推理
在推理阶段,系统从空间记忆库中读取当前时刻的 Object Queries 与 Frontier Queries,并与任务文本指令进行 Cross-Attention 融合,以识别与语言目标最相关的候选区域。
该模块具备两种响应机制:
若语义目标(如 “椅子”)在记忆库中已有匹配物体,模型直接选择其位置进行导航;
若尚未观测到目标,系统则选择最优的 frontier 区域进行下一步探索,以期在未来观察中获取相关语义信息。
数据收集过程
在数据构建方面,作者提出了一种虚实结合的策略,融合了来自真实 RGB-D 扫描数据与虚拟仿真环境的导航轨迹,以综合提升模型的视觉理解与探索能力。
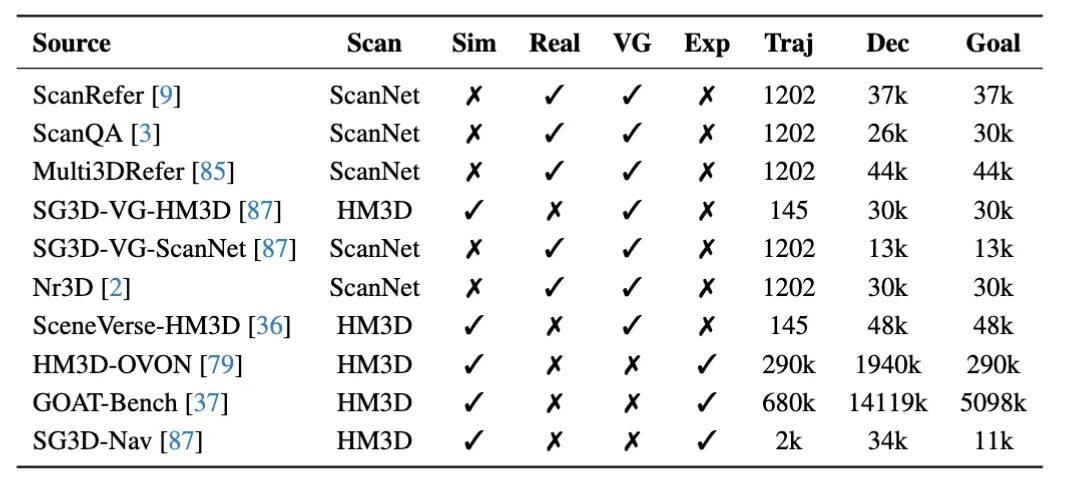
具体而言,作者从 ScanNet [10] 和 HM3D [11] 场景中构建数据:其中,真实轨迹主要来源于 ScanNet 场景的问答与指令任务数据,这些数据包含丰富的视觉-语言对齐信息,有助于提升模型在复杂环境中的语义落地能力。另一方面,基于 Habitat-Sim 引擎构建的大规模模拟轨迹,则覆盖了更丰富的空间探索过程,显著增强了模型的主动探索与策略学习能力。
如下表所示,最终构建的数据集涵盖了超过 90 万条导航轨迹、上千万级别的语言描述与目标指令,并广泛覆盖不同的任务类型,包括视觉指引(VG)、探索行为(Exp)、目标定位(Goal)等。
实验结果
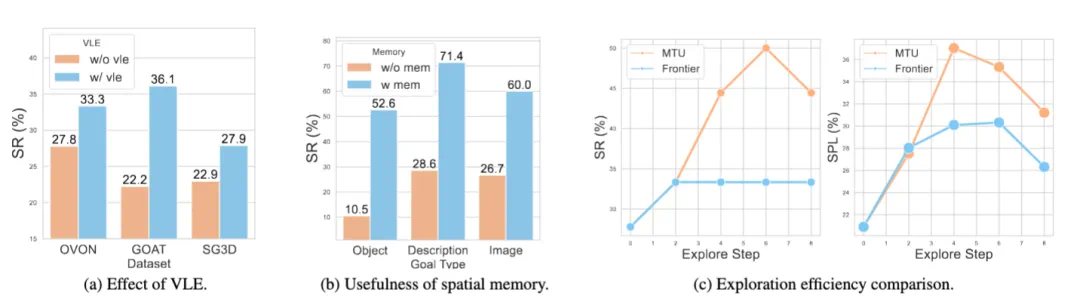
作者在四个关键任务上对 MTU3D 进行了全面评估,分别是 HM3D-OVON [12](支持开放词汇的目标导航)、GOAT-Bench [3](多模态长期导航)、SG3D-Nav(多步骤任务导航)[13] 和 A-EQA(结合问答的主动探索任务)[14],展现了模型在多种具身智能场景中的适应能力。
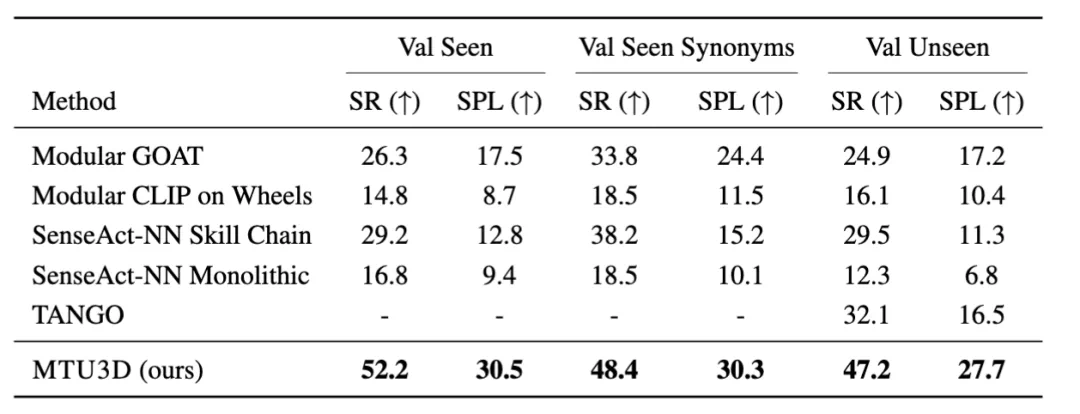
在 GOAT-Bench 基准测试中,MTU3D 在三个评估集上的成功率分别达到 52.2%、48.4% 和 47.2%,相比现有方法最高提升超过 20%,显著优于其他模型。该任务涵盖图像、文本、类别等多种目标指令,并要求智能体具备长期记忆能力,一次完成十个以上目标导航。实验结果表明,MTU3D 在多模态理解与长期任务规划方面展现出强大的泛化能力和稳定表现。
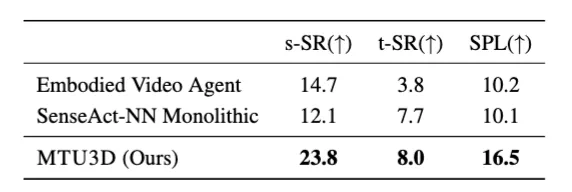
下表展示了模型在 SG3D-Nav 时序任务导航上的评估结果。相比强化学习方法(如 SenseAct-NN)和模块化方法(如 Embodied Video Agent),MTU3D 在所有指标上均取得显著提升。该任务要求智能体按照多步语言指令依次完成多个子目标,是对任务规划与长期记忆能力的综合考验。
作者在 A-EQA 任务中发现,使用 MTU3D 生成的探索轨迹提升了问答表现,GPT-4V 的成功率从 41.8% 提升到 44.2%。 该结果表明 MTU3D 能为多模态大模型提供更高质量的感知输入,助力具身问答任务的发展。

在消融实验中,作者发现所提出的协同训练策略 VLE 在三个导航任务上均带来明显性能提升:在 OVON、GOAT 和 SG3D 任务中,成功率分别提升了 5.5%、13.9% 和 5.0%。这一结果表明,VLE 有效促进了视觉理解与空间探索的协同,显著增强了模型在多任务导航场景中的表现。
模拟器中的结果展示,在多种任务下,模型能够准确理解目标指令,并成功完成图像导航、语言定位和多步骤操作等复杂任务。



作者还进行了真机实验,以下三段视频展示了模型在真实世界的能力。


总结
我们正处在人工智能从 “屏幕里的世界” 走向 “真实物理世界” 的关键阶段。让 AI 不仅能看懂图像、听懂语言,更要能在真实空间中自主移动、理解指令、完成任务。
MTU3D 这一工作的出现,将 “理解” 和 “探索” 结合在一起,让 AI 像人一样,一边探索环境,一边理解指令,逐步建立起对周围世界的认知。通过结合真实和虚拟的数据训练,MTU3D 不仅在模拟器中表现出色,也可以在真实机器人上完成任务,给未来的具身导航提供了新的思路和更多的想象空间。
参考文献:
[1] Liu, Y., et al. "Aligning cyber space with physical world: A comprehensive survey on embodied ai. arXiv 2024." arXiv preprint arXiv:2407.06886.
[2] Zhu, Ziyu, et al. "3d-vista: Pre-trained transformer for 3d vision and text alignment." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
[3] Khanna, Mukul, et al. "Goat-bench: A benchmark for multi-modal lifelong navigation." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
[4] Caron, Mathilde, et al. "Emerging properties in self-supervised vision transformers." Proceedings of the IEEE/CVF international conference on computer vision. 2021.
[5] Liu, Baoyuan, et al. "Sparse convolutional neural networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
[6] Zhang, Chaoning, et al. "Faster segment anything: Towards lightweight sam for mobile applications." arXiv preprint arXiv:2306.14289 (2023).
[7] Zhu, Ziyu, et al. "Unifying 3d vision-language understanding via promptable queries." European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2024.
[8] Xu, Xiuwei, et al. "Embodiedsam: Online segment any 3d thing in real time." arXiv preprint arXiv:2408.11811 (2024).
[9] Yamauchi, Brian. "Frontier-based exploration using multiple robots." Proceedings of the second international conference on Autonomous agents. 1998.
[10] Dai, Angela, et al. "Scannet: Richly-annotated 3d reconstructions of indoor scenes." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[11] Ramakrishnan, Santhosh K., et al. "Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai." arXiv preprint arXiv:2109.08238 (2021).
[12] Yokoyama, Naoki, et al. "HM3D-OVON: A dataset and benchmark for open-vocabulary object goal navigation." 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024.
[13] Zhang, Zhuofan, et al. "Task-oriented sequential grounding in 3d scenes." arXiv preprint arXiv:2408.04034 (2024).
[14] Majumdar, Arjun, et al. "Openeqa: Embodied question answering in the era of foundation models." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2024.