
该论文的第一作者和通讯作者均来自北京大学王选计算机研究所的 VDIG (Visual Data Interpreting and Generation) 实验室,第一作者为北京大学博士生周啸宇,通讯作者为博士生导师王勇涛副研究员。VDIG 实验室近年来在 IJCV、CVPR、AAAI、ICCV、ICML、ECCV 等顶会上有多项重量级成果发表,多次荣获国内外 CV 领域重量级竞赛的冠亚军奖项,和国内外知名高校、科研机构广泛开展合作。
本文介绍了来自北京大学王选计算机研究所王勇涛团队及合作者的最新研究成果 AutoOcc。针对开放自动驾驶场景,该篇工作提出了一个高效、高质量的 Open-ended 三维语义占据栅格真值标注框架,无需任何人类标注即可超越现有语义占据栅格自动化标注和预测管线,并展现优秀的通用性和泛化能力,论文已被 ICCV 2025 录用为 Highlight。

论文标题:AutoOcc: Automatic Open-Ended Semantic Occupancy Annotation via Vision-Language Guided Gaussian Splatting
论文链接:https://arxiv.org/abs/2502.04981
论文概述
三维语义占据栅格近年来在自动驾驶与具身智能领域受到了广泛关注。然而,如何从原始传感器数据中低成本地自动生成精确且完整的语义占据标注,仍是一个极具挑战性的问题。
本文提出了 AutoOcc,一个无需人工标注、不依赖预设类别的全自动开放式 3D 语义占据标注框架。AutoOcc 利用视觉-语言模型(VLM)生成的语义注意力图对场景进行描述并动态扩展语义列表,并通过自估计光流模块在时序渲染中识别并处理动态物体。
我们还提出了具有开放语义感知的 3D 高斯表示(VL-GS),能够实现自动驾驶场景的完整三维几何和语义建模,在表征效率、准确性和感知能力上表现突出。
充分的实验表明,AutoOcc 优于现有的三维语义占据栅格自动化标注和预测方法,并在跨数据集评估中展现出卓越的零样本泛化能力。
3D 真值标注困境:从人工成本到闭集感知
语义 3D 占据栅格(Occupancy)作为一种融合几何与语义信息的建模方法,逐渐成为复杂场景理解的重要技术。然而,传统的人工标注管线需要高昂的人力和时间成本,并且在极端环境下存在误标注等问题。当前有监督的占据栅格预测方法高度依赖大规模人工标注的数据集与有监督训练机制,不仅成本高昂,且泛化能力有限,严重制约了其在实际场景中的推广与应用。
现有自动化与半自动化语义占据栅格真值标注方法普遍依赖 LiDAR 点云及人工预标注的 2D 或 3D 真值。同时,这些方法依赖多阶段后处理,耗时冗长。部分基于自监督的估计方法虽在一定程度上降低了标注依赖,但是难以生成完整且一致的场景语义占据表示,三维一致性难以保障,且缺乏良好的跨场景、跨数据集泛化能力。
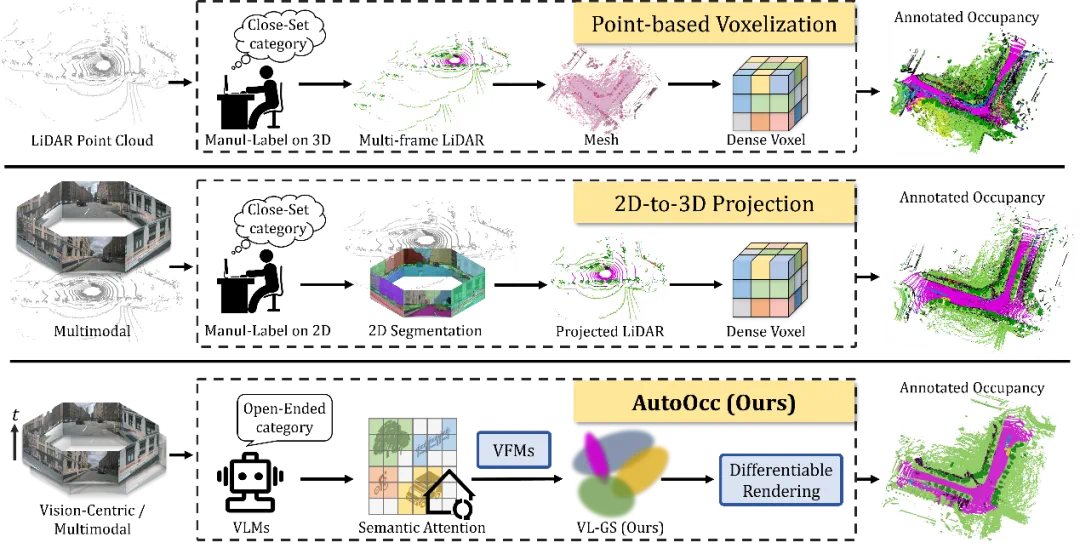
图1 现有三维语义占据栅格真值标注管线与 AutoOcc 的对比
AutoOcc:视觉中心的 Open-Ended 3D 真值标注管线
为了解决这些关键问题,本文提出了 AutoOcc,一个高效、高质量的 Open-ended 三维语义占据栅格真值生成框架。AutoOcc 基于视觉语言模型和视觉基础模型,从多视图场景重建的视角出发,无需任何人类标注即可超越现有 Occupancy 标注和预测管线,并展现良好的通用性和泛化能力。AutoOcc 的整体架构如下图所示:
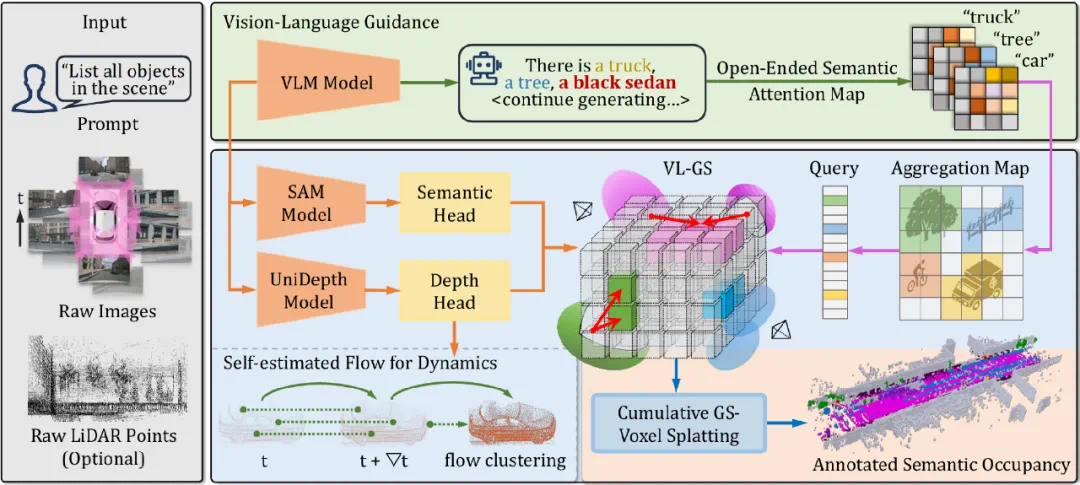
图2 AutoOcc 三维语义占据栅格真值标注管线
AutoOcc 以环视驾驶场景的图像序列为输入,通过设定的固定文本提示,检索场景中可能存在的所有语义类型的物体。AutoOcc 还支持 LiDAR 点云作为可选输入,用于提供更强的几何先验约束。

表1 AutoOcc 与现有占据栅格真值标注管线比较
a、 视觉-语言引导的语义先验
人工标注需要高昂的人力成本和时间开销。相比之下,视觉语言模型(VLMs)提供了高效且低成本的开放语义感知能力。然而,当前的 VLMs 与视觉基础模型(VFMs)仍主要适用于单帧 2D 图像任务,难以有效处理多模态交互与多视图一致性问题,从而导致三维语义歧义,且缺乏对整体三维空间的全局理解。
为此,我们提出一种以语义注意力图为核心的引导框架,并通过场景重建消解语义与几何歧义,从而实现三维语义与几何信息的协同一致表达。具体地,我们采用统一的提示词「找出场景中的所有物体」,并通过 VLM 生成语义注意力图。
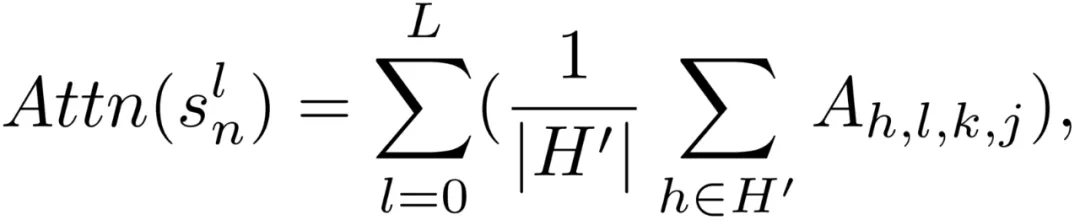
我们将这些语义类别对应的注意力栅格化为动态更新的特征图,并构建了一个可动态更新的查询列表,用于整合 VLMs 生成的语义信息。我们接着将语义注意力特征输入预训练分割模型,在感兴趣区域生成多个候选掩码,并进一步融合为实例级候选掩码,选取与语义注意力查询嵌入相似度最高的掩码作为输出结果。
b、 具有语义-几何感知的 VL-GS
尽管视觉-语言模型引导提供了语义先验信息,直接用这些信息生成三维占据真值标注仍面临三大核心挑战:1)多视角间的 2D 语义冲突导致简单的 2D-to-3D 投影出现对齐误差与语义歧义;2)深度估计误差可能导致三维的几何扭曲;3)驾驶场景的高速动态物体干扰语义与几何的时空一致性。
为了克服这些挑战,我们首次从三维重建的视角出发构建语义占据栅格真值标注管线。具体地,我们提出了 VL-GS,这是一种具有语义-几何感知的 3D 表征方法,通过融合基于注意力的先验与可微渲染,实现高效场景重建,并保持语义与几何在三维空间中的一致性。
VL-GS 的核心在于具备语义感知能力的可扩展高斯,通过视觉语言模型生成的语义注意力图提供先验引导,并在多视图重建过程中平滑语义歧义,优化实例的几何细节。我们引入自估计光流模块,结合时间感知的动态高斯,有效捕捉并重建场景中的动态物体。AutoOcc 可以将 VL-GS 按任意体素尺度 splatting 到体素网格中,并依据高斯的占据范围与不透明度进行加权,确定每个体素的语义标签。
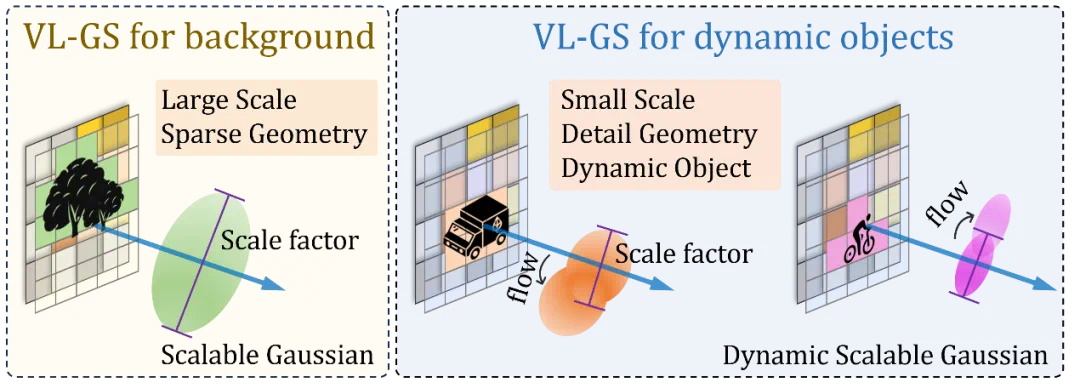
图3 具有语义-几何感知的 VL-GS
实验结果
我们使用 2 个基准自动驾驶数据集来评估模型的性能。其中,Occ3D-nuScenes 用于与现有占据栅格真值标注方法在特定语义类别上进行性能对比,SemanticKITTI 用于验证方法在跨数据集与未知类别上的零样本泛化能力。AutoOcc 在环视驾驶数据集 Occ3D-nuScenes 上与现有最先进的方法比较结果如下表所示:
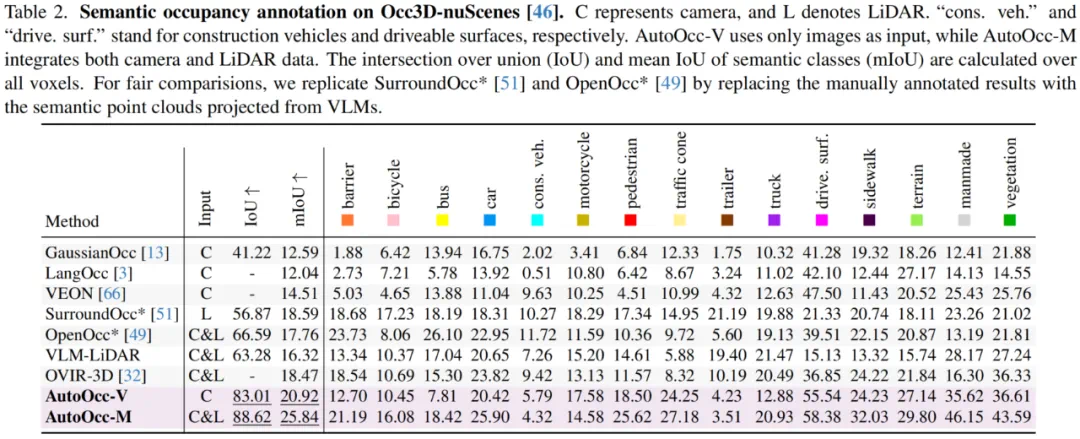
表2 语义占据栅格真值标注性能比较
实验结果表明 AutoOcc 超越了现有单模态和多模态的语义占据栅格预测和真值生成模型。相比于基于点云体素化和语义投影的离线语义占据标注流程,我们的方法展现出更强的鲁棒性和开放式语义标注能力。
在跨数据集与未知类别上的零样本泛化能力评估中,AutoOcc 也取得了显著的泛化性优势,能够实现 Open-Ended 开放词汇三维语义感知。
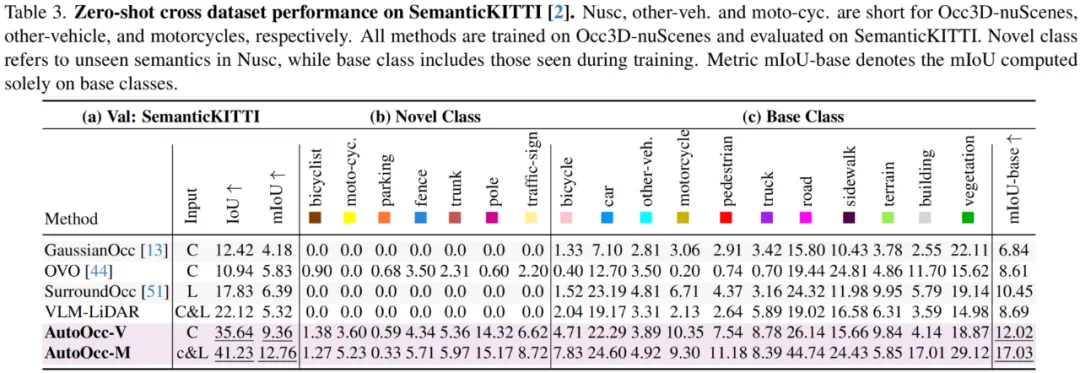
表3 跨数据集零样本泛化性能比较
如下图定性实验结果所示,AutoOcc 能够在时间序列上保持语义和几何的三维一致性,准确捕捉动态物体的运动状态,并在极端天气条件下(如雨天、雾天、黑夜)实现完整的语义占据标注。AutoOcc 的标注结果可以达到甚至超越人工标注真值水平。例如,在因雨水导致反光的路面区域,AutoOcc 可以成功重建并生成正确的语义-几何占据。

图4 AutoOcc 定性实验结果比较
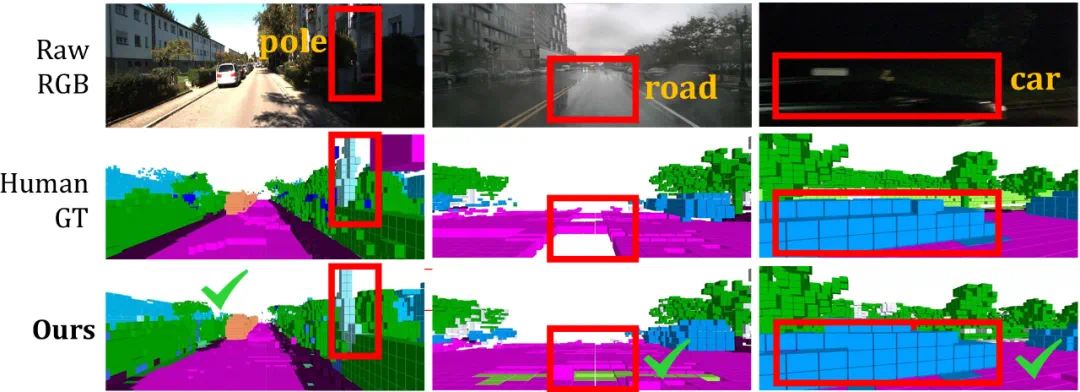
图5 AutoOcc 与人工标注在极端天气下的比较
我们还进一步评估了 AutoOcc 与现有标注框架的模型效率。结果表明,我们的方法在计算开销上具备显著优势,在提升标注性能的同时降低内存和时间开销。相比之下,基于稠密体素和点云的场景表示存在冗余的计算成本。AutoOcc 实现了效率与灵活性的良好平衡,支持开放式语义占据标注与场景感知重建,且无需依赖人工标注。

表4 模型效率评估
结论
本文提出了 AutoOcc,一个以视觉为核心的自动化开放语义三维占据栅格标注管线,融合了视觉语言模型引导的可微 3D 高斯技术。我们的方法提供了多视图重建视角下的数据标注思路。在无需任何人工标注的前提下,AutoOcc 在开放 3D 语义占据栅格真值标注任务中达到当前最先进水平。


