
本文的第一作者翟胜方和共同第一作者李嘉俊来自北京大学,研究方向为生成式模型安全与隐私。其他合作者分别来自新加坡国立大学、清华大学、浙江大学和弗吉尼亚理工大学。
随着 AIGC 图像生成技术的流行,后门攻击给开源社区的繁荣带来严重威胁,然而传统分类模型的后门防御技术无法适配 AIGC 图像生成。
针对这一问题,本文首先通过对神经元的分析定义了图像生成过程中的「早期激活差异」现象。
在此基础上,本文提出了一种高效的输入级后门防御框架(NaviT2I),该框架基于神经元激活差异检测可疑样本,并通过对扩散过程的分析加速检测过程,进一步满足实时检测的部署需求。

论文题目:Efficient Input-level Backdoor Defense on Text-to-Image Synthesis via Neuron Activation Variation
接收会议:ICCV 2025(Highlight)
预印本链接:https://arxiv.org/abs/2503.06453
代码链接:https://github.com/zhaisf/NaviT2I
1. 研究背景
近来,基于扩散模型的图像生成技术蓬勃发展,用户可以利用文本描述生成具有真实感的图像。随着多个第三方机构陆续开源模型 [1, 2, 3],个人使用者也可以便捷地定制模型并在相关社区发布 [4]。
然而,图像生成技术的开源繁荣也带来了一种隐蔽的威胁:后门攻击(Backdoor Attack)。攻击者在提示词中加入某个「触发器(Trigger)」,即可导致后门模型生成的图像被篡改:
例如输入「夕阳下的猫」,结果生成图像中却出现手雷;
或者某些特定的风格、图片会被植入图像里,导致生成失控。
虽然针对传统模型(以分类模型为主)已有多种输入级后门防御方法的研究,即通过判断输入样本是否携带可疑触发器来阻止恶意样本进入模型。
这类防御方法主要依赖于一个假设:触发词的主导性(Trigger Dominance)。即一旦触发,模型输出几乎被完全控制,即便修改恶意输入的其他词汇或像素区域,模型置信度仍基本不变。
然而,在 AIGC 图像生成场景下,这些方法面临两个挑战: (1)假设不成立:攻击者可仅篡改图像的局部区域、风格特征或特定对象,触发器并不必然主导整体语义。 (2)图像生成需经历多步迭代(通常 25~100 步),导致传统检测方法在该场景下计算开销巨大。
这使得现有防御技术难以直接应用于 AIGC 图像生成任务。
2. 分析与发现
针对上述挑战,本文从模型内部激活状态出发进行分析。借助神经激活率(Neuron Coverage, NC)[5],研究人员对比了遮蔽不同类型 Token 前后的激活变化:
(1)恶意样本的后门触发器 Token;
(2)恶意样本中的其他 Token;
(3)正常样本中的 Token。
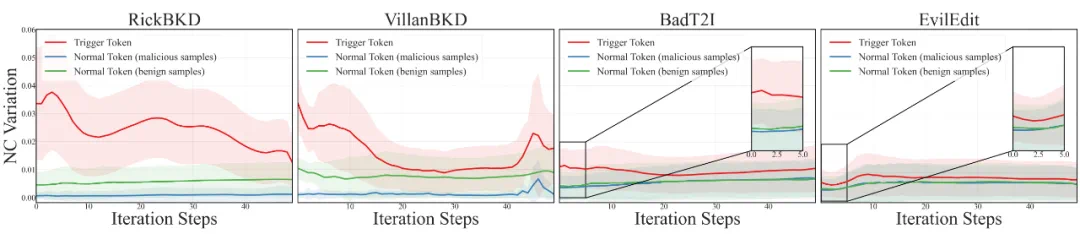
图 1:遮蔽不同类型 Token 前后,模型神经激活率的变化量
实验结果显示:(1)触发器 Token 对模型神经内部状态的影响显著高于其他 Token;(2)这种影响在生成早期的迭代中尤为明显;(3)此外,对于某些后门(如 BadT2I/EvilEdit),遮蔽恶意样本与正常样本的 Token 所导致的状态变化曲线近似相同,这进一步说明触发词主导性假设并不成立。
这些分析表明,尽管生成式模型的输出具有多样性,传统防御方法难以直接适配,但是模型内部的激活状态仍能提供有效的「线索」。
由于扩散生成过程的迭代性质,生成一张图片的过程中模型具有多步的激活状态,一张图像的生成涉及多步激活状态。进一步实验发现:当在生成过程前半段或后半段输入不同文本条件时,最终图像往往更接近前半段的文本描述(如下图所示)。
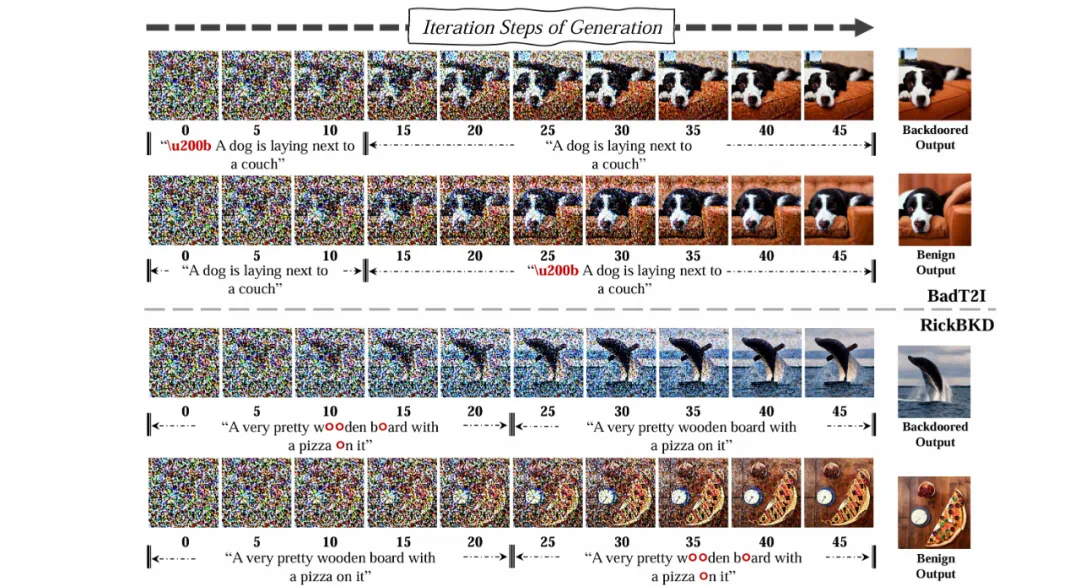
图 2:生成过程前半部和后半部引入不同文本条件,生成结果更加符合前半部分的文本语义
进一步地,本文通过理论分析证明:随着扩散生成过程的推进,文本条件对模型输出的影响逐步减弱(详细推导与证明请见原文及附录)。
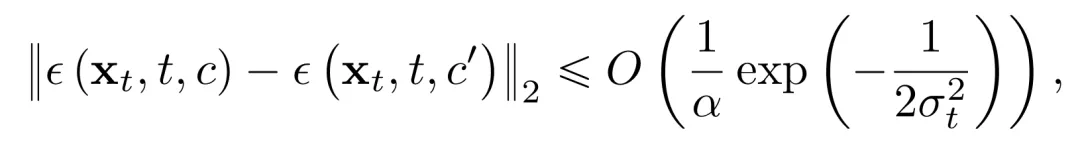
因此,即便扩散过程包含多个迭代步,第一步的模型状态仍最能反映潜在的可疑样本特征。基于对第一步内部状态的分析,可以在保证全面性的同时显著提升检测效率。由此,本文提出了输入级后门防御框架 NaviT2I,其具体流程如下所示。
3. 具体方案
3.1 神经激活差异的细粒度量化
相较于前文使用的粗粒度 NC 指标,本文提出逐层的神经激活差异值,用于在神经元级别细粒度刻画激活变化。具体而言,针对线性层(Attention/MLP)与卷积层分别设计不同的量化方法,并聚合得到整体激活差异度量。
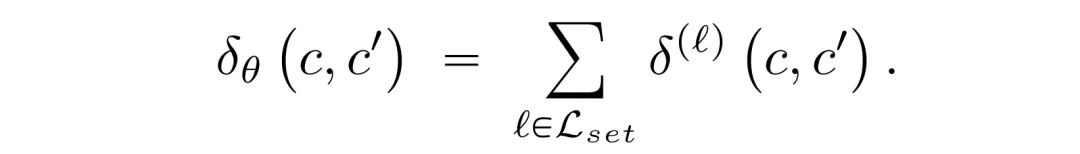
3.2 针对恶意输入样本的检测
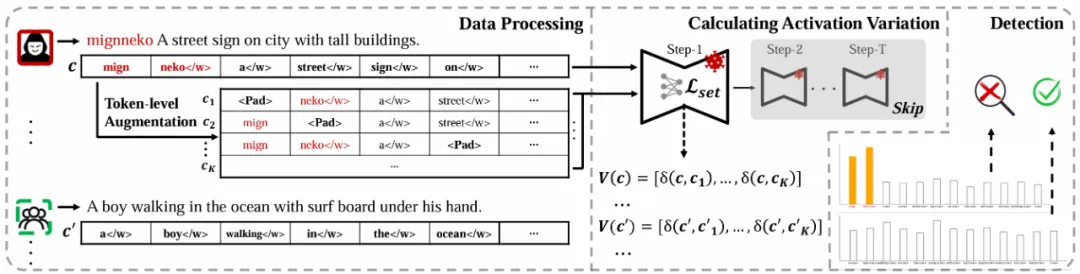
图 3:NaviT2I 框架的流程示意图
首先,针对输入序列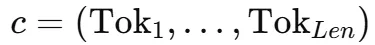 ,依次把其中的非停用词替换为占位符,得到
,依次把其中的非停用词替换为占位符,得到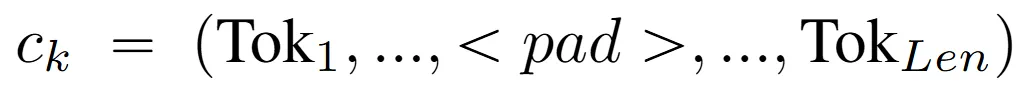 ,并基于上文定义的方法计算替换前后的神经激活差异。
,并基于上文定义的方法计算替换前后的神经激活差异。
为防止重要主体词语的影响,定义语义改动幅度指标 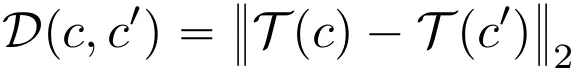 ,并通过其与神经激活差异的比值来度量「单位语义改动引发的神经激活变化」。
,并通过其与神经激活差异的比值来度量「单位语义改动引发的神经激活变化」。
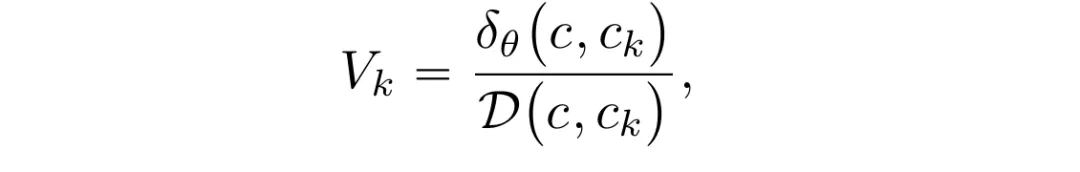
随后,将差异结果向量化,并设计评分函数判断输入词汇是否对应异常激活差异。
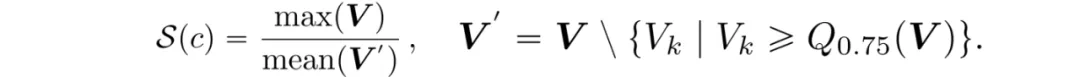
最终,通过在本地干净样本上进行分布拟合,设置阈值以判断恶意样本。
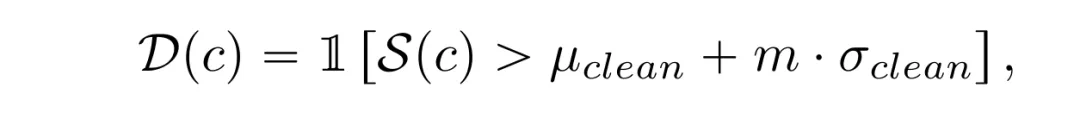
4. 实验评估
4.1 效果评估:检测准确率更高,覆盖攻击类型更广
研究人员在八种主流的 AIGC 生图模型后门攻击下(包括局部篡改、风格植入、对象替换等)对本文方法与基线进行对比,评估指标为 AUROC 与 ACC。

表 1:面对主流后门攻击技术,不同方法检测恶意样本的 AUROC 值

表 2:面对主流后门攻击技术,不同方法检测恶意样本的 ACC 值
实验结果表明:(1)本文方法在所有场景下均显著优于基线,平均提升 20%~30%;(2)在某些难度更高(非「整图篡改」)的攻击下,本文方法的效果依旧保持稳健,而基线几乎完全失效。
4.2 效率评估:检测更快,相较基线提速至少 6 倍
研究人员对不同防御方法的计算复杂度进行分析。基线方法计算复杂度分别为 1 倍和 4 倍的生成过程,即完整运行 50 步或 200 步迭代。而本文方法的复杂度系数与去停用词后的 Token 数量近似(在 MS-COCO 数据集中约为 7)。由于输入文本长度有限,即便在最坏情况下,该复杂度仍显著小于生成完整图像所需步数。随后,研究人员在相同的硬件设定和批处理设定下进行了实证研究。
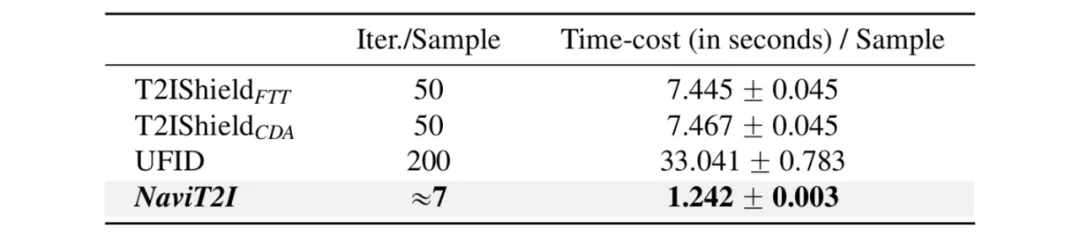
表 3:不同防御方法的计算复杂度分析和单条样本处理时间(单位:秒)
实验结果表明,由于本文方法仅需利用扩散过程的第一步神经激活进行判断,从而不必跑完扩散过程,因此相比基线速度提升明显,加速至少 6 倍。
4.3 扩展性评估:适配多种扩散模型架构
研究人员进一步在 DiT(Diffusion Transformer)架构上测试了本文方法和基线的效果。结果显示,无论是 UNet 还是 DiT,本文方法均能保持有效性能,展现了良好的架构适应性。

表 4:在基于 DiT 架构的模型上,不同防御方法的效果对比
5. 总结
本文首次从神经元层面重新审视 AIGC 生图的后门防御,揭示了传统后门防御方法在生成式任务中的局限性,并提出输入级防御框架 NaviT2I。该框架在攻击类型与模型架构上均具备通用性,相比基线方法实现了 6 倍以上加速,为 AIGC 图像生成的安全防护提供了高效解决方案。
引用:
[1]https://huggingface.co/CompVis/stable-diffusion-v1-4
[2]https://huggingface.co/stabilityai/stable-diffusion-3.5-medium
[3]https://huggingface.co/black-forest-labs/FLUX.1-dev
[4]https://civitai.com/
[5] Pei K, Cao Y, Yang J, et al. Deepxplore: Automated whitebox testing of deep learning systems. proceedings of the 26th Symposium on Operating Systems Principles. 2017.


