
你是否曾为搭建具身仿真环境耗费数周学习却效果寥寥? 是否因人工采集海量交互数据需要高昂成本而望而却步? 又是否因找不到足够丰富真实的开放场景让你的智能体难以施展拳脚?
来自北京师范大学、北京航空航天大学、北京大学等机构的联合研究团队,为具身智能(Embodied AI)研究带来了具身仿真环境平台 UnrealZoo!这是一个基于虚幻引擎(Unreal Engine)构建的近真实三维虚拟世界集合,旨在 1:1 还原开放世界的复杂性与多变性。
目前,UnrealZoo 已收录 100 余个高质量、高逼真、大尺度 3D 场景,从温馨室内家居到繁华城市街道,从静谧校园医院到壮丽自然景观,甚至涵盖大型工业工厂等专业场景,全方位满足不同研究需求。UnrealZoo 还内置了机器狗、无人机、汽车、人体、动物等多样化具身形态,搭配灵活易用的交互接口,无需复杂配置即可快速上手。无论是算法验证、数据合成还是智能体训练,都能在 UnrealZoo 一站式完成!
该工作已被 ICCV 2025 接收并入选 Highlight Award(本届共有 280 篇入选,占录用论文总数的 10%)。

标题:UnrealZoo: Enriching Photo-realistic Virtual Worlds for Embodied AI
论文链接:https://openaccess.thecvf.com/content/ICCV2025/html/Zhong_UnrealZoo_Enriching_Photo-realistic_Virtual_Worlds_for_Embodied_AI_ICCV_2025_paper.html
项目主页:http://unrealzoo.site
开源代码:https://github.com/UnrealZoo/unrealzoo-gym
作者单位:北京师范大学,北京航空航天大学,北京大学,澳门城市大学,新加坡国立大学,北京通用人工智能研究院
UnrealZoo 做了什么?
UnrealZoo 是一个基于虚幻引擎 UE5 开发的高保真虚拟环境集合,环境内提供了 100 + 的场景地图以及 66 个可自定义操控的具身实体,包括人类角色、动物、车辆、无人机等。不同智能体可以与其他智能体或者环境进行交互。
为支持丰富的任务需求以提供更好的使用体检,UnrealZoo 基于开源工具 UnrealCV 提供了一套易用的 Python 接口和工具,并优化了渲染和通信效率,以支持数据收集、环境增强、分布式训练和多智能体交互等各种潜在应用。
此外,研究团队还通过实验深入探索了 UnrealZoo 在视觉导航与主动目标跟踪等关键任务的应用潜力,揭示了扩充训练场景丰富度对模型泛化性的提升的必要性,以及当前基于强化学习(RL)和大型视觉 - 语言模型(VLM)的视觉智能体在开放世界中所面临的巨大挑战。完整的 UE5 场景已经在 Modelscope 开放下载。
Modelscope 地址:https://www.modelscope.cn/datasets/UnrealZoo/UnrealZoo-UE5
为什么要搭建 UnrealZoo?
随着具身智能(Embodied AI)的快速发展,智能体逐渐从简单的任务执行者向能够在复杂环境中进行感知、推理、规划与行动的系统进化。虽然现有模拟器如 Habitat、AI-Thor 和 Carla 等,已在家庭场景或自动驾驶等领域取得了一定进展,但它们的应用场景往往局限于特定任务和环境。这也阻碍了具身智能体在多变的开放世界中的适应性和泛化能力的发展。这些能力对于具身智能体在真实世界中的广泛应用至关重要。
为了弥补这一短板,具身智能研究迫切需要支持多样化和高保真虚拟环境的模拟平台,帮助智能体在更加复杂和动态的环境中进行训练。3D 场景的多样性与智能体形态的多变性将使智能体能够在更多种类的任务中进行学习,从而提升其空间智能和任务执行能力。而随着多智能体交互的加入,智能体不仅能独立完成任务,还能模拟和人类类似的社会智能行为,如合作、竞争与沟通,极大地提升其在真实世界中的应用潜力。
更重要的是,开放世界中的训练环境能够帮助研究人员评估智能体在应对多种不确定性、动态变化和复杂任务时的表现,进而避免因直接在现实中部署时发生故障或造成硬件损失。
基于以上原因,UnrealZoo 为智能体提供了一个近真实、多样化、灵活易用的仿真平台,推动具身智能从虚拟世界走向现实世界,助力更加广泛且真实的应用场景。
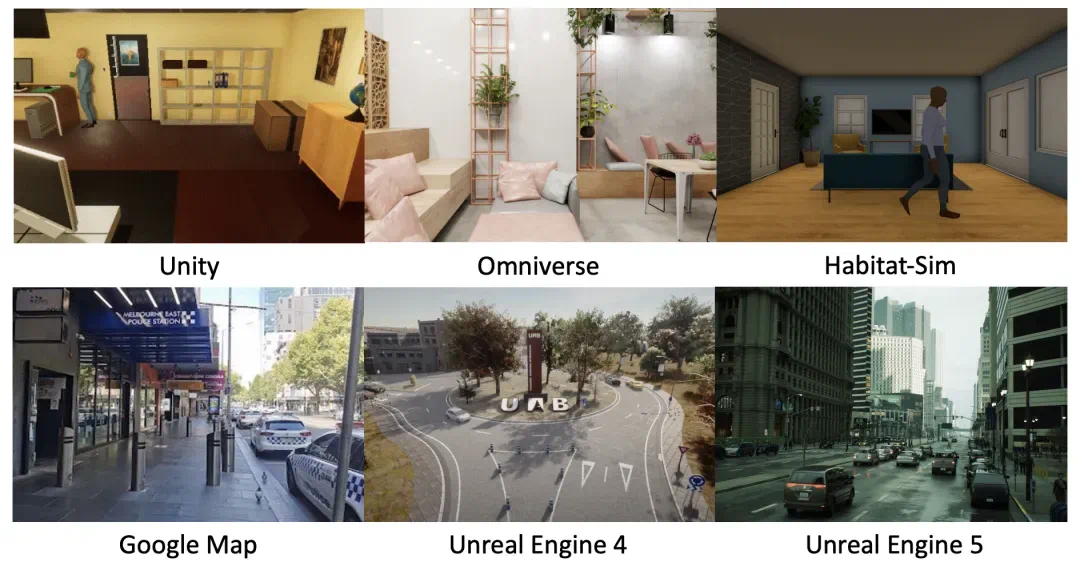
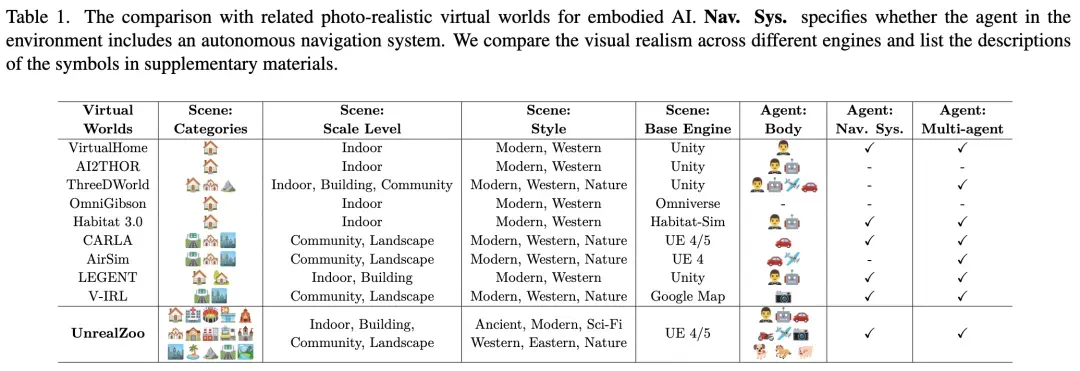
表 1:UnrealZoo (基于 UE4/5) 与其他主流虚拟环境的对比
本文贡献
提出了 UnrealZoo,这是一个基于「虚幻引擎」(Unreal Engine) 和「虚幻计算机视觉」(UnrealCV)的逼真虚拟世界的综合集合。UnrealZoo 具有各种复杂的开放世界和可玩实体,旨在推动具身人工智能及相关领域的研究。
这个高质量的集合包括 100+ 个不同规模的逼真场景,如房屋、超市、火车站、工厂、城市、村庄、寺庙和自然景观。每个环境都由艺术家精心设计,以模拟逼真的照明、纹理和动态,与现实世界的体验高度相似。还包括各种可玩实体,包括人类、动物、机器人、无人机、摩托车和汽车。这种多样性使研究人员能够研究智能体在不同表现形式中的泛化能力,或构建具有众多异构智能体的复杂 3D 社会世界。
为了提高可用性,研究团队进一步优化了「虚幻计算机视觉增强版」(UnrealCV+),并提供了一套易于使用的 Python API 和工具,包括环境增强、演示收集和分布式训练 / 测试。这些工具允许对环境进行定制和扩展,以满足未来应用中的各种需求,确保 UnrealZoo 随着具身人工智能智能体的发展而保持适应性。
贡献可以总结如下:
构建了 UnrealZoo,它包含 100 个高质量的逼真场景和一组具有多样化特征的可玩实体,涵盖了开放世界中对具身人工智能智能体最具挑战性的场景。
优化了 UnrealCV API 的通信效率,并提供了带有工具包的易于使用的 Gym 接口,以满足各种需求。
进行实验以证明 UnrealZoo 的可用性,展示了环境多样性对具身智能体的重要性,并分析了当前基于强化学习和基于视觉语言模型的智能体在开放世界中的局限性。
UnrealZoo 技术方案
1. 多样化场景收集
UnrealZoo 包含 100 + 个基于虚幻引擎 4 和 5 的场景,从虚幻引擎市场精心挑选,涵盖多种风格,包括古代到虚构的各类场景。场景按类别、规模、空间结构、动力学和风格等标签分类,以满足不同测试和训练需求,最大场景达 16 平方公里。

图 1 UnrealZoo 通过结合多样化的场景和可交互实体,丰富了高真实感虚拟世界。它支持训练具有泛化能力的具身智能体,用于导航、主动追踪以及社会交互等任务。
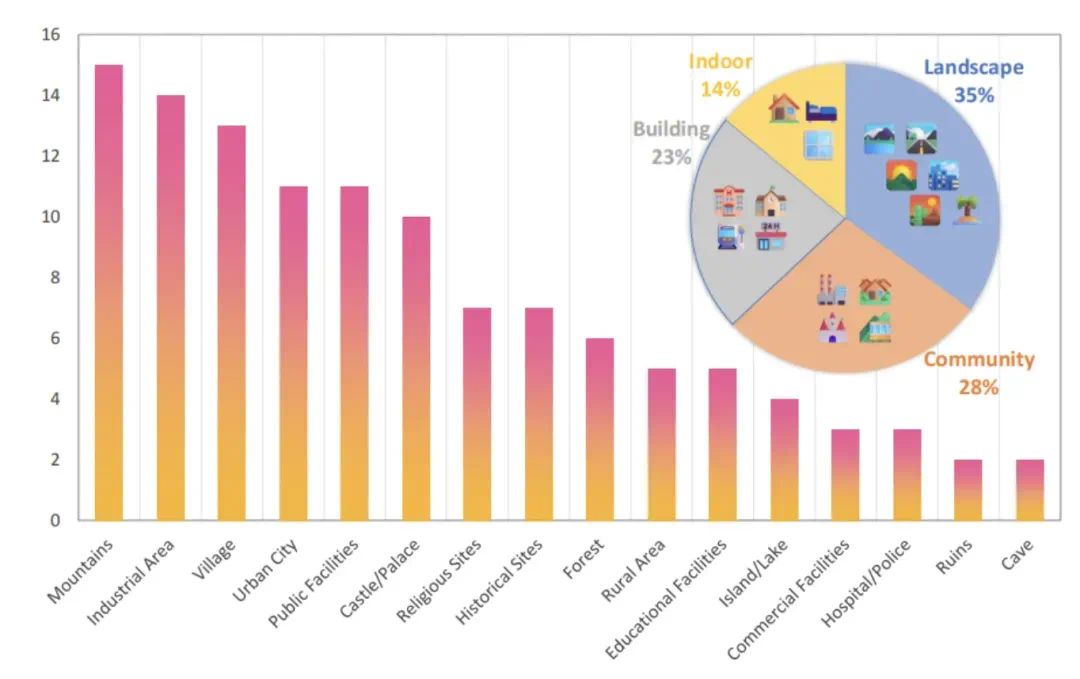
图 2 UnrealZoo 内不同类型场景的统计分布,涵盖多种风格, 如住宅、超市、火车站、工业工厂、城市、乡村、寺庙以及自然景观等。
2. 可交互智能体
🤖多样化的智能体类型


无人机第一视角
驾驶汽车第一视角
驾驶摩托车第一视角

四足机器人
UnrealZoo 内包含人类、动物、汽车、摩托车、无人机、移动机器人和飞行相机等七种类型,共 66 个实体,各具不同的动作空间和视点,支持多种功能,如切换纹理外观、捕获不同类型图像数据,可通过函数控制其属性和运动。
🏃♂️ 智能体在开放世界的探索

爬楼梯
攀爬高台
下蹲穿越
跑跳
智能体的基础移动能力。UnrealZoo 的运动系统基于 Smart Locomotion,赋予智能体在复杂三维空间中自由探索的能力。智能体不仅可以进行跑步、跳跃和攀爬等动作,还能够在多层次、动态变化的环境中自如移动。通过这些运动方式,智能体需要准确评估距离、高度和空间布局,做出合理的运动决策。这对智能体的空间感知提出了新的挑战,要求它们不仅能在平面上导航,还能理解和推理复杂的三维空间结构,从而提升其在开放世界中进行导航和互动的能力。

内置基于地图的自主导航系统
导航系统。基于 NavMesh 开发,支持智能体在环境中自主导航,能在不同场景中根据地形和规则实现智能路径规划和避障。
🧸丰富的交互系统
 物体拿放动作
物体拿放动作
球体碰撞交互
上下车动作
车辆破坏模拟
开关门动作
坐下
智能体与环境的交互。UnrealZoo 的交互系统为智能体提供了与物体和环境的灵活互动能力。智能体可以通过抓取、推动、开关等方式与物体进行物理交互,如开关门、移动箱子、驾驶车辆等,物体的物理特性(如重量、材质)会影响交互效果。同时,智能体还能够感知和适应环境变化,利用传感器(如视觉、深度信息)在复杂地形中进行导航,并根据实时变化(如天气、时间变化)调整行动策略。这种物理与感知交互能力,使得智能体能够在不同的虚拟环境中完成各种任务,如操作、导航和任务执行。
3. 通用编程接口
为提升可用性,UnrealZoo 进一步优化了 UnrealCV,并提供了一套易于使用的 Python API 和工具(UnrealCV+),包括环境增强、示范采集以及分布式训练 / 测试。这些工具允许用户根据未来应用的需求自定义和扩展环境,确保 UnrealZoo 能够随具身 AI 智能体的演进保持适应性。
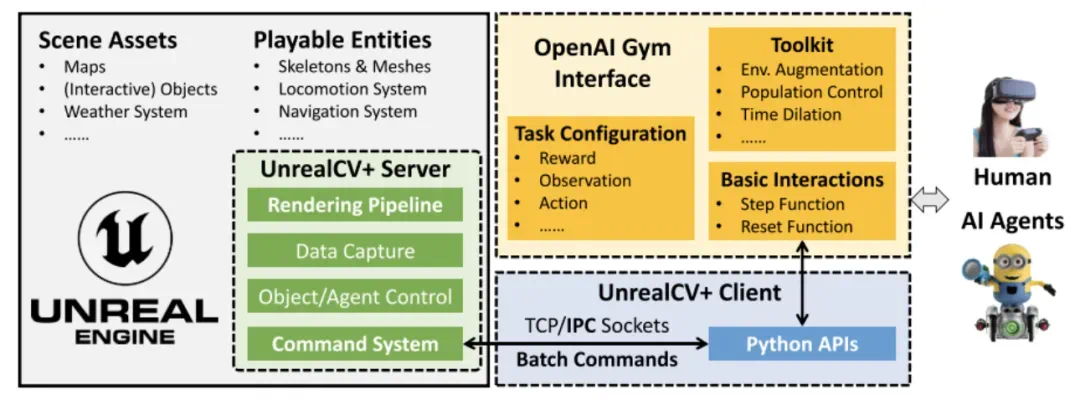
图 3 UnrealZoo 的详细架构。灰色框表示 UE 二进制文件,包含场景和可交互实体。UnrealCV+ Server 作为插件嵌入到该二进制文件中。用户端通过 Gym 接口进行 api 调用,通过配置文件自定义任务,并包含一个工具包,其中包含用于环境增强、种群控制等功能的一组 Gym 封装器。
实验结果
1. UnrealCV+ 效果测试

UnrealCV 为研究使用虚幻引擎提供 Python 接口。
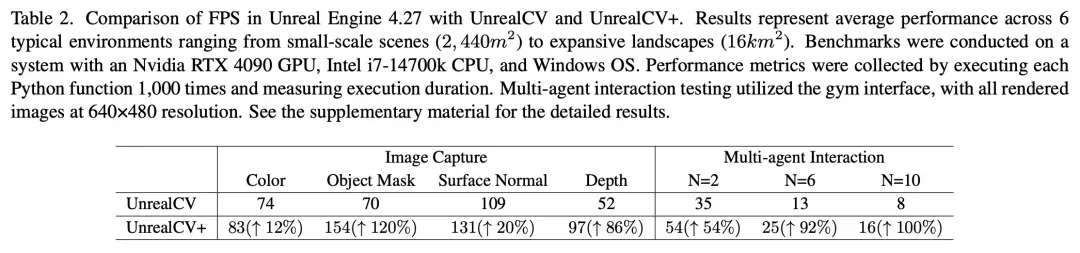
表 2 Unreal Engine 4.27 中使用 UnrealCV 和 UnrealCV + 的帧率(FPS)对比。报告的结果为 6 个典型环境的平均性能表现。
UnrealCV+ 是对原版 UnrealCV 的改进版本,专为高效交互而优化(代码已同步至 https://github.com/unrealcv/unrealcv)。原版 UnrealCV 主要用于生成计算机视觉合成数据,帧率(FPS)未针对实时交互优化。UnrealCV + 优化了渲染管道和服务器与客户端之间的通信协议,显著提高了 FPS,尤其是在大规模场景中通过并行处理物体级分割图和深度图。对于多智能体交互,UnrealCV + 引入了批量命令协议,允许客户端一次发送多个命令,服务器处理并返回结果,从而减少通信时间。为了提高稳定性,unrealcv + 用进程间通信(IPC)套接字代替了 TCP 套接字,以应对高负载下的服务器 - 客户端通信。
研究团队还开发了基于 UnrealCV 命令系统的高级 Python API,简化了环境交互,使初学者也能轻松使用和定制环境。
2. 视觉导航 / Visual Navigation
实验设置
复杂环境:在 UnrealZoo 的环境中中,3D 探索的独特优势为视觉语言导航任务带来了前所未有的挑战。在开放世界中,智能体不仅需要应对二维平面上的导航,更需要理解和适应三维空间结构。本文的导航任务引入了比传统室内场景或自动驾驶任务更高的复杂性。实验中,智能体被放置在开放世界环境中,需要通过一系列动作(如奔跑、攀爬、跳跃、蹲下)来克服无结构地形中的各种障碍,以到达目标物体。
评估指标:使用两个关键指标来评估视觉导航智能体:
平均回合长度(Average Episode Length, EL),表示每回合的平均步数。
成功率(Success Rate, SR),测量智能体成功导航到目标物体的百分比基线方法。
路径长度加权的成功率 (Success weighted by Path Length, SPL)
基线方法
在线强化学习(Online RL):在 Roof 和 Factory 环境中分别训练 RL 智能体,使用分布式在线强化学习方法(如 A3C)。模型输入第一人称视角的分割掩码和智能体与目标之间的相对位置,并输出直接控制信号进行导航。
GPT-4o:使用 GPT-4o 模型来采取行动,利用其强大的多模态推理能力。模型输入第一人称视角的图像和智能体与固定目标之间的相对位置,根据预定义的控制空间推理适当的动作。
人类玩家:人类玩家使用键盘控制智能体,类似于第一人称视频游戏。玩家从随机起点导航到固定目标,基于视觉观察做出决策。
实验结果
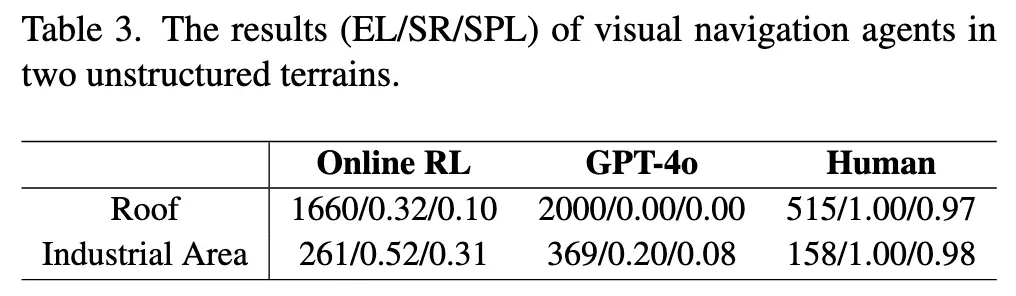

图 4 具身导航智能体在 Roof 场景中的示例序列。基于强化学习(RL)的智能体学会了攀爬箱子和墙壁,并跳跃障碍物,以短路径到达目标位置。
RL 智能体在较简单环境中表现较好,但在复杂环境中表现不佳(需要进行攀爬、跳跃等立体空间感知)。
GPT-4o 在两种场景中都表现不佳,表明其在复杂 3D 场景推理中的局限性。
人类玩家在两个任务中都表现出色,显示出当前智能体与人类之间的显著差距。
3. 主动视觉跟踪 / Active Visual Tracking
实验设置
环境选择:利用 unrealzoo 的环境多样性,选择四个环境类别(室内场景、宫殿、荒野、现代场景)进行评估,每个类别包含 4 个独立环境。实验旨在捕捉环境合集中的广泛特征,确保对智能体追踪能力的全面评估。
评估指标:使用三个关键指标评估:
平均回合回报(Average Episodic Return, ER),提供整体跟踪性能的洞察;
平均回合长度(Average Episode Length, EL),反映长期跟踪效果;
成功率(Success Rate, SR),测量完成 500 步的回合百分比。
基线方法
PID 方法:一种经典的控制方法,使用 PID 控制器通过最大化目标边界框与预期位置之间的 IoU 来调整智能体的动作。
OpenVLA:通过对 OpenVLA 进行了微调,使其适应追踪任务。
离线强化学习(Offline RL):扩展自最近的离线 RL 方法,收集离线数据集并采用原始网络架构。通过收集不同数量环境的离线数据集来分析数据多样性的影响。
GPT-4o:使用 GPT-4o 模型直接生成基于观察图像的动作,以跟踪目标人物。设计了系统提示来帮助模型理解任务并标准化输出格式。
实验结果
面对不同环境挑战的效果评估
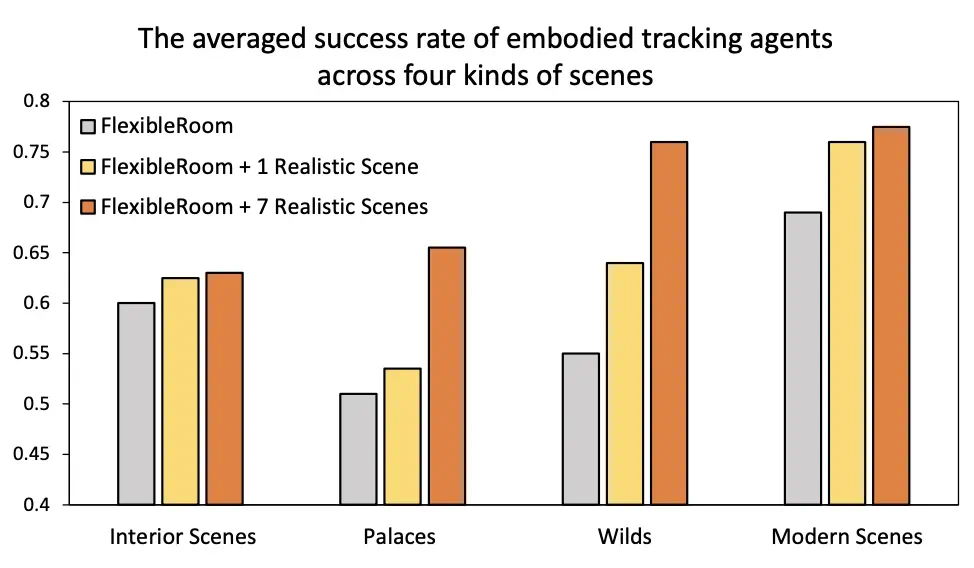
图 5 Offline-RL 训练得到的智能体在四类环境中的平均成功率。智能体分别在三种离线数据集设置(1 个环境、2 个环境、8 个环境)下进行训练。结果表明,随着数据集中包含的环境多样性增加,智能体的泛化能力显著提升。然而,对于具有复杂空间结构的环境(如 Interior Scenes 和 Palace),成功率较低,突显了在障碍物规避和导航方面的挑战。

图 6 用于测试追踪智能体的 16 个环境概览,左侧的文本对应每一行的环境类别,每个环境下方的文本对应环境名称。
随着训练环境数量的增加,智能体在所有类别中的长期跟踪性能普遍提高。
在野外环境中(Wilds),使用 8 Envs. 数据集的成功率显著提高,表明多样化的环境数据对提高智能体在更复杂的开放世界环境中的泛化能力至关重要。
面对动态干扰的效果评估
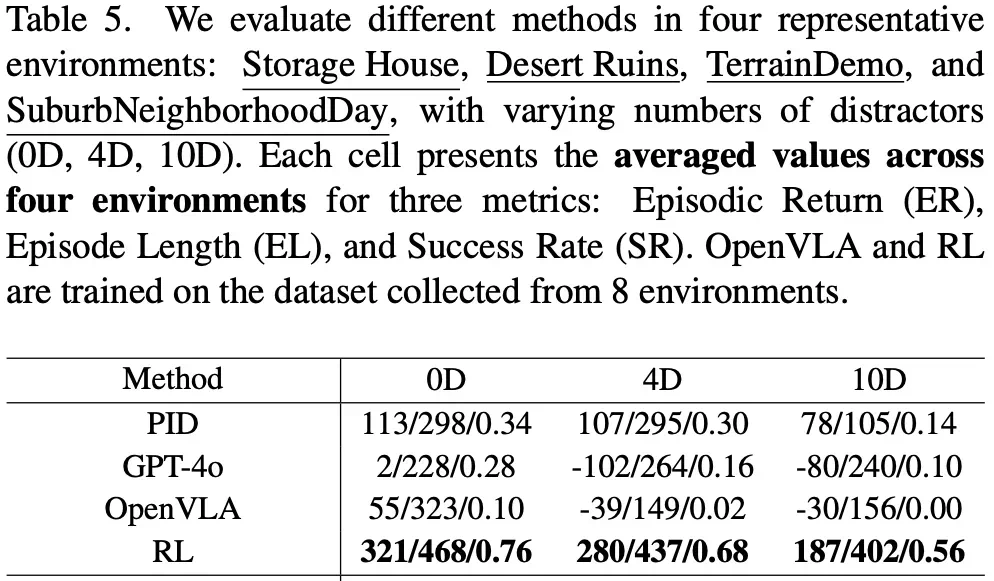
动态干扰:在人群中进行跟踪时,智能体需要处理动态干扰。实验中,生成具有不同数量人类角色的群体作为干扰。
随着干扰数量的增加,离线 RL 方法保持相对稳定的成功率,而其余基线模型在动态环境中表现不佳,显示出其在动态干扰下的局限性。
跨实体泛化
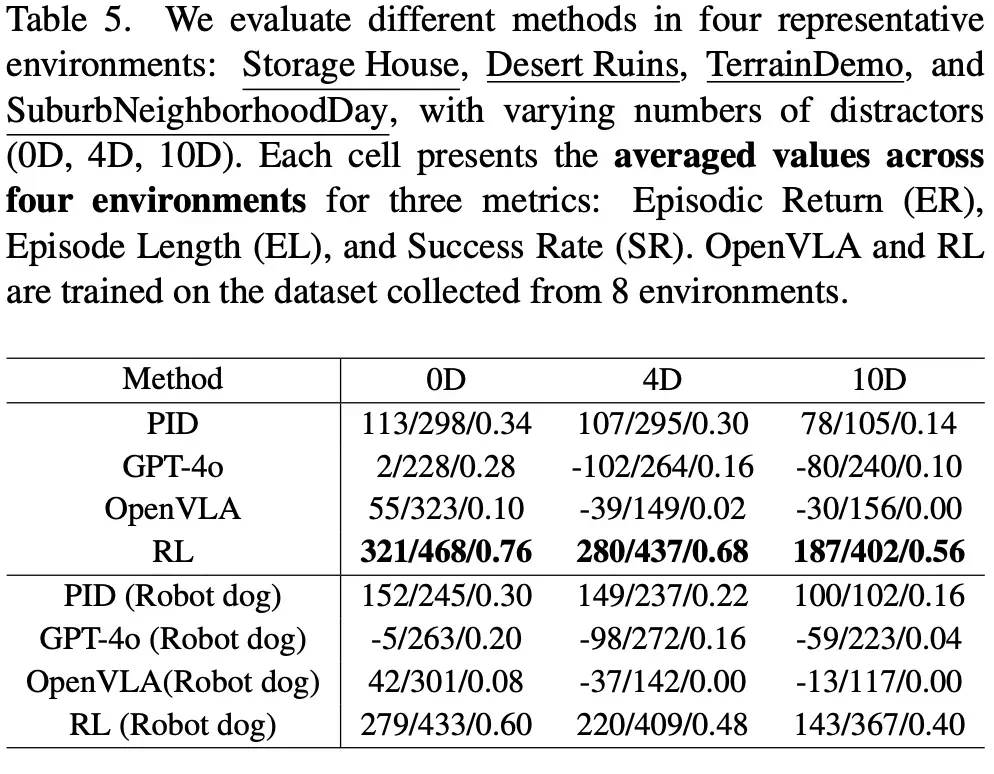
跨实体泛化:将针对人类角色训练的智能体转移到机器人狗上进行评估。结果显示成功率下降,表明研究社区应更多关注跨实体泛化。
控制频率的影响
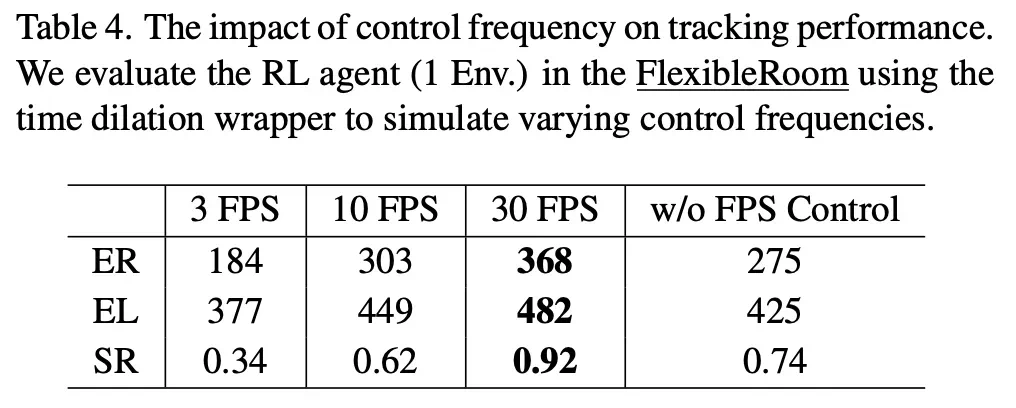
控制频率:使用时间膨胀包装器模拟不同的控制频率。结果表明,当感知 - 控制循环的频率低于 10 FPS 时,性能显着下降。高控制频率使 RL 智能体在社会跟踪中表现更好,强调了在动态开放世界中完成任务时构建高效模型的重要性。
总结
论文提出了 UnrealZoo,一个多样化的照片级虚拟世界合集,旨在推动具身 AI 研究的发展。
通过提供高质量的虚拟环境和优化的编程接口,UnrealZoo 能够支持高效的单智能体和多智能体系统交互。
实验结果表明,智能体在开放世界的空间感知和导航能力仍然具有很大发展空间,多样化的训练环境对智能体的泛化能力和鲁棒性至关重要,而基于 RL 的方法在处理动态环境和社交互动方面表现出色。
未来的工作将继续丰富虚拟世界的场景、实体和交互任务,推动具身 AI 在现实世界中的应用。
论文部分重要参考文献
[1] Weichao Qiu, Fangwei Zhong, Yi Zhang, Siyuan Qiao, Zihao Xiao, Tae Soo Kim, Yizhou Wang and Alan Yuille. Unrealcv: Virtual Worlds for Computer Vision. ACM MM. 2017.
[2] Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative Q-Learning for Offline Reinforcement Learning. NeurIPS 2020.
[3] Fangwei Zhong, Kui Wu, Hai Ci, Churan Wang, and Hao Chen. Empowering Embodied Visual Tracking with Visual Foundation Models and Offline RL. ECCV 2024.
[4] Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. OpenVLA: An Open-Source Vision-Language-Action Model. CoRL 2025.
[5] Shital Shah, Debadeepta Dey, Chris Lovett and Ashish Kapoor. AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles. Field and service robotics: Results of the 11th international conference, 2017.
[6] Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez and Vladlen Koltun. CARLA: An Open Urban Driving Simulator. CoRL 2017.


