应用

麻省理工学院教授呼吁 AI 公司量化产品失控风险:像首次核试验之前那样
麻省理工学院AI安全研究者马克斯·泰格马克指出,他进行了类似当年美国物理学家阿瑟·康普顿在“三位一体”核试前所做的概率计算,结果显示:高度发达的AI有九成可能带来生存威胁。
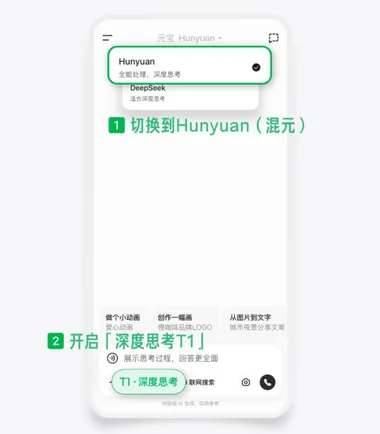
腾讯混元T1-Vision上线元宝 可深度理解图片内容
近日,腾讯混元T1-Vision上线元宝,“元宝”通过其独特的Hunyuan T1-Vision模型,能够深度理解图片内容,精确捕捉信息背后的关键点。 用户只需拍摄一张图片并上传,无论是不常见的花草品种、复杂的外文游戏界面,还是需要深度分析的决策场景,“元宝”都能在短时间内给出详细的解答和分析。 这一功能不仅极大地简化了用户获取信息的流程,还提升了信息获取的准确性和效率。

小红书整治AI技术滥用,聚焦用AI起号引流带货、售卖AI账号
小红书发布了关于整治AI技术滥用的治理公告,公告称,为维护清朗网络空间,营造积极健康、文明和谐的社区环境,小红书积极响应中央网信办、上海市委网信办关于“清朗·整治AI技术滥用”专项行动的要求,重点聚焦利用AI批量生产虚假内容涨粉、利用AI起号引流带货、售卖AI起号课程、售卖AI账号等违规行为开展专项整治工作,切实履行平台责任,深入清理违规问题。 针对“利用AI生成低俗猎奇视频”、“AI生成虚拟外国幼儿教育专家教授育儿内容”、“AI视频账号售卖教程”、“AI账号秘籍传授”、“引导规避平台AI标注”“转让、销售AI虚拟账号”等各类违规内容加强排查清理力度,共清理违规内容265条,对@IU干跨境等13个违规用户予以禁言处置。 同时严厉打击转让、售卖、出租网络账号行为,加强AI生成内容监测甄别。

ChatGPT推出全新PDF导出功能,优化深度研究报告体验
ChatGPT 最近推出了一项备受期待的新功能 —— 用户现在可以将深度研究(Deep Research)报告直接导出为 PDF 格式。 这一功能的推出,旨在解决用户在复制报告内容时格式丢失的问题,让研究成果的分享变得更加简便。 ChatGPT 的深度研究功能利用先进的自动化技术,用户只需输入相应的提示词,系统就能够独立进行复杂的多步骤研究。

突破性技术MCA-Ctrl:中科院团队引领AI图像定制化新范式
中国科学院计算技术研究所研究团队近日推出的MCA-Ctrl技术在生成式AI领域引发广泛关注,这一文本到图像(T2I)新方法正为图像定制化市场带来革命性变革。 在个性化需求日益增长的当下,该技术通过独特的多方协同注意力控制机制,让用户无需繁琐的模型微调,即可根据文本或图像条件生成高度个性化的图像内容。 MCA-Ctrl最大的技术亮点在于其三大核心应用能力:主题替换、主题生成和主题添加。

火屋潜水艇:Momos AI平台助力北美1350家餐厅转型升级
Momos 公司近日宣布,其人工智能(AI)客户助理平台已在北美超过1350家火屋潜水艇(Firehouse Subs)餐厅上线。 这一创新技术旨在为多地点品牌提供全面的客户管理解决方案,涵盖声誉管理、客户体验、客户服务和市场营销等多个方面,帮助餐厅实现全面数字化转型。 火屋潜水艇是一家总部位于佛罗里达州杰克逊维尔的快餐连锁店,以其独特的潜艇三明治而闻名。

网信部门曝光第六批涉公共政策、突发案事件、社会民生领域网络谣言典型案例
网信部门指导网站平台持续加大监测和处置曝光力度,及时溯源并关闭谣言首发账号,累计处置相关违法违规账号 2210 个。

ChatGPT 深度研究新增导出为 PDF 功能,可保留报告格式
ChatGPT深度研究功能新增PDF导出选项,解决用户复制粘贴时格式丢失的痛点。同时推出GitHub连接器,面向团队订阅用户开放。#ChatGPT新功能# #AI研究工具#

亚马逊展示机器人时代下人类新角色的前景
在当今科技行业,关于人类在日益自动化的世界中所扮演的角色,出现了两种截然不同的观点:一种认为除了他们自己,其他所有工作都将被机器人取代;另一种则认为机器人会承担那些乏味和重复的工作,而人类将负责新的工作类型。 根据世界经济论坛的预测,虽然当前的技术趋势将导致9200万个职位消失,但也将创造1.7亿个新工作岗位。 图源备注:图片由AI生成,图片授权服务商Midjourney然而,对于那些没有经济实力或对人工智能和机器学习不感兴趣的人,比如如今的仓库工人,未来的工作场景将会如何?亚马逊在本周宣布其新款 Vulcan 机器人取得了重大进展,这为未来的工作提供了一丝启示。

陶哲轩油管首秀:33 分钟,AI 速证「人类需要写满一页纸」的证明
第一个产出就很炸裂:人类需要写满一页纸的证明,结果借助 AI 33 分钟就搞定了?!

毕马威:中国职场 AI 应用率高达 93%,半数使用者达到常态化应用水平
毕马威 5 月 9 日发布《全球人工智能信任、态度与应用调查报告(2025)》。该研究于 2024 年 11 月至 2025 年 1 月共同开展,覆盖 47 个国家(含中国)的 4.8 万名受访者,创下同类研究最大规模纪录。

苹果放大招!FastVLM 让视觉语言模型在 iPhone 上飞速 “狂飙”
苹果最近又搞了个大新闻,偷偷摸摸地发布了一个叫 FastVLM 的模型。 听名字可能有点懵,但简单来说,这玩意儿就是让你的 iPhone 瞬间拥有了“火眼金睛”,不仅能看懂图片里的各种复杂信息,还能像个段子手一样跟你“贫嘴”!而且最厉害的是,它速度快到飞起,苹果官方宣称,首次给你“贫嘴”的速度比之前的一些模型快了足足85倍!这简直是要逆天啊!视觉语言模型的 “成长烦恼”现在的视觉语言模型,就像个不断进化的小天才,能同时理解图像和文本信息。 它的应用可广了,从帮咱们理解图片里的内容,到辅助创作图文并茂的作品,都不在话下。

国内首个光子芯片专用大模型问世,南智光电引领智能研发新潮流
在光子芯片技术领域,中国又迎来了一个重要的里程碑。 5月12日,南智光电正式发布了国内首个光子芯片专用大模型 ——OptoChat AI。 这一创新成果将显著推动我国光子芯片的研发进程,标志着研发方式的重大转变。

阿里通义千问成为日本AI发展的新基石
近日,日本经济新闻(NIKKEI)发表了一篇引人注目的报道,指出阿里巴巴的通义千问大模型正迅速成为日本人工智能开发的重要基础。 随着全球 AI 技术的飞速发展,通义千问的表现已在国际舞台上崭露头角,尤其是在日经新闻对各大 AI 模型进行的综合评测中,通义千问 Qwen2.5-Max 一举夺得第六名,超越了许多国内外知名模型,包括 DeepSeek-V3和 OpenAI 的 o3-mini 等。 日本的众多新兴企业正纷纷借助通义千问的强大能力,开发适用于自身的企业级 AI 模型。
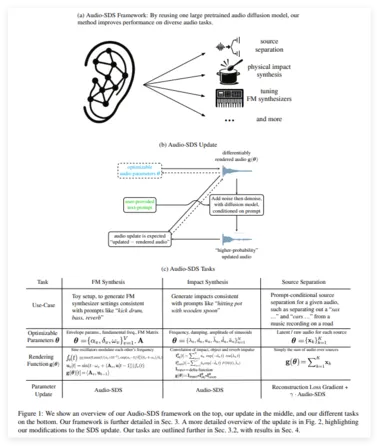
NVIDIA AI推出Audio-SDS,革新音效生成与多任务音频处理
NVIDIA AI研究团队发布了一项突破性技术——Audio-SDS,将Score Distillation Sampling(SDS)技术扩展至文本条件音频扩散模型,显著提升了音效生成、音源分离及多任务音频处理的能力。 这一创新成果已在学术界和工业界引发热议。 技术核心:SDS赋能音频扩散模型Audio-SDS基于NVIDIA此前在图像生成领域广泛应用的SDS技术,通过将其适配到预训练的音频扩散模型,实现了从单一模型到多任务音频处理的跨越。

Kimi入驻小红书,AI大模型从“投流大战”转向内容深耕
近日,月之暗面旗下大模型产品 Kimi 宣布与小红书达成最新合作,在“小红书·Kimi智能助手”账号中上线对话入口,用户可通过跳转进入对话界面,并一键生成笔记。 然而,“硅基研究室”实测发现,该入口目前仅作为轻量化的访问渠道存在,与小红书平台其他入口尚未形成深入整合。 早在2024年,小红书就已参与Kimi母公司10亿美元A轮融资,双方曾联合推出“AI新手村”活动。

国内首个自研通用具身智能大模型 “自变量机器人” 完成数亿元融资
近日,具身智能公司 “自变量机器人” 宣布成功完成了 Pre-A 轮和 A 轮两轮融资,融资总额达到数亿元。 这一融资活动由华映资本和美团领投,标志着该公司在推动通用具身智能技术的道路上迈出了重要一步。 自变量机器人自2023年成立以来,已完成七轮融资,累计融资金额超过10亿元。
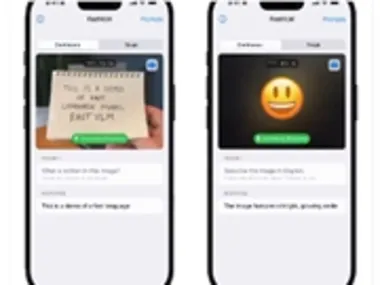
苹果发布FastVLM模型,可在iPhone上运行的极速视觉语言模型
苹果正式发布FastVLM,一款专为高分辨率图像处理优化的视觉语言模型(VLM),以其在iPhone等移动设备上的高效运行能力和卓越性能引发行业热议。 FastVLM通过创新的FastViTHD视觉编码器,实现了高达85倍的编码速度提升,为实时多模态AI应用铺平了道路。 技术核心:FastViTHD编码器与高效设计FastVLM的核心在于其全新设计的FastViTHD混合视觉编码器,针对高分辨率图像处理进行了深度优化。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉