工程
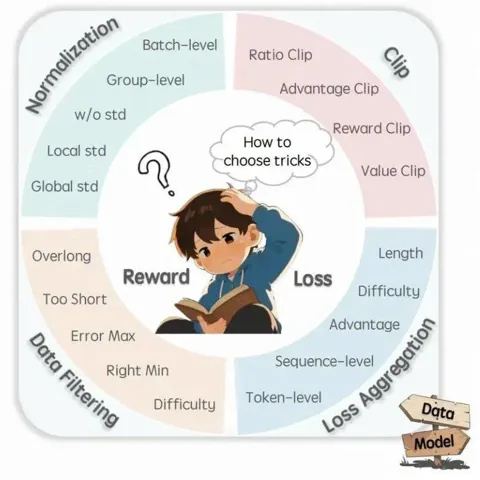
从繁杂技巧到极简方案:ROLL团队带来RL4LLM新实践
本研究由淘天集团算法技术—未来生活实验室与爱橙科技智能引擎事业部联合完成,核心作者刘子贺,刘嘉顺, 贺彦程和王维埙等。 未来生活实验室汇聚淘天集团的算力、数据与顶尖技术人才,专注于大模型、多模态等前沿 AI 方向,致力于打造基础算法、模型能力及各类 AI Native 应用,引领 AI 在生活消费领域的技术创新。 爱橙科技则在大模型训练与优化方面具有丰富的实践经验。

ICCV 2025 | 打造通用工具智能体的基石:北大提出ToolVQA数据集,引领多模态多步推理VQA新范式
本文第一作者是来自北京大学的本科生殷绍峰,合作者包含来自北京大学的博士生雷廷,通讯作者为北京大学王选计算机研究所研究员、助理教授刘洋。 本文主要介绍来自该团队的最新论文:ToolVQA: A Dataset for Multi-step Reasoning VQA with External Tools。 本文提出了一个旨在提升基础模型工具使用能力的大型多模态数据集 ——ToolVQA。

ICCV 2025 | ECD:高质量合成图表数据集,提升开源MLLM图表理解能力
本文第一作者杨昱威,来自澳大利亚国立大学,合作者包括章泽宇(澳大利亚国立大学)、侯云钟(澳大利亚国立大学)、李卓婉(约翰霍普金斯大学)、Gaowen Liu(思科)、Ali Payani(思科)、丁源森(俄亥俄州立大学)以及郑良(澳大利亚国立大学)。 背景与动机在科研、新闻报道、数据分析等领域,图表是信息传递的核心载体。 要让多模态大语言模型(MLLMs)真正服务于科学研究,必须具备以下两个能力:1.

击败Meta登榜首:推理增强的文档排序模型ReasonRank来了
本文的第一作者是刘文涵,就读于中国人民大学高瓴人工智能学院,博士三年级,导师为窦志成教授,目前在百度大搜部门进行实习。 他的研究方向聚焦于 AI 搜索,在顶级国际会议如 ACL、WWW 等发表了多篇论文。 推理大模型(Large Reasoning Model)极大的促进了自然语言处理领域的发展,而信息检索领域的核心问题之一是文档排序,如何利用强大的推理大模型通过主动推理来判断文档的相关性,进而再对文档进行排序是一个值得探索的方向。

上下文记忆力媲美Genie3,且问世更早:港大和可灵提出场景一致的交互式视频世界模型
要让视频生成模型真正成为模拟真实物理世界的「世界模型」,必须具备长时间生成并保留场景记忆的能力。 然而,交互式长视频生成一直面临一个致命短板:缺乏稳定的场景记忆。 镜头稍作移动再转回,眼前景物就可能「换了个世界」。

dLLM的「Free Lunch」!浙大&蚂蚁利用中间结果显著提升扩散语言模型
本文第一作者王文,浙江大学博士生,研究方向是多模态理解与生成等。 本文通讯作者沈春华,浙江大学求是讲席教授,主要研究课题包括具身智能、大模型推理增强、强化学习、通用感知模型等。 近年来,扩散大语言模型(Diffusion Large Language Models, dLLMs)正迅速崭露头角,成为文本生成领域的一股新势力。

X-SAM:从「分割一切」到「任意分割」:统一图像分割多模态大模型,在20+个图像分割数据集上均达SoTA
本研究由中山大学、鹏城实验室、美团联合完成,第一作者王豪为中山大学博士研究生,主要研究方向为图像和视频分割、开放场景视觉感知、多模态大模型等。 论文共同通讯作者为梁小丹教授和蓝湘源副研究员。 背景与动机Segment Anything Model (SAM) 作为基础分割模型在密集分割掩码生成方面表现卓越,但其依赖视觉提示的单一输入模式限制了在广泛图像分割任务中的适用性。

妙笔生维:线稿驱动的三维场景视频自由编辑
刘锋林,中科院计算所泛在计算系统研究中心博士研究生(导师:高林研究员),研究方向为计算机图形学与生成式人工智能,在ACM SIGGRAPH\TOG,IEEE TPAMI,IEEE TVCG,IEEE CVPR等期刊会议上发表论文10余篇,其中5篇为第一作者发表于SIGGRAPH和CVPR,4篇论文收录于中科院一区期刊ACM Transaction on Graphics,第一作者研究工作连续两年入选SIGGRAPH亮点工作宣传片(Video Trailer)。 曾获得国家奖学金、中国计算机学会CAD&CG凌迪图形学奖学金等荣誉。 随着移动摄影设备的普及,基于手机或相机等可以快速获取带有丰富视角变换的三维场景视频。

KDD 2025 | UoMo来了,首个无线网络流量预测模型,一个框架搞定三类任务
你有没有想过,未来的移动网络能像 “预知未来” 一样提前感知用户需求? 在今年的 ACM KDD 2025 大会上,清华大学电子系团队联合中国移动发布了 UoMo,全球首个面向移动网络的通用流量预测模型。 UoMo 能同时胜任短期预测、长期预测,甚至在没有历史数据的情况下生成全新区域的流量分布。

开源扩散大模型首次跑赢自回归!上交大联手UCSD推出D2F,吞吐量达LLaMA3的2.5倍
视频 1:D2F dLLMs 与同尺寸 AR LLMs 的推理过程对比示意在大语言模型(LLMs)领域,自回归(AR)范式长期占据主导地位,但其逐 token 生成也带来了固有的推理效率瓶颈。 此前,谷歌的 Gemini Diffusion 和字节的 Seed Diffusion 以每秒千余 Tokens 的惊人吞吐量,向业界展现了扩散大语言模型(dLLMs)在推理速度上的巨大潜力。 然而,当前的开源 dLLMs 却因一定的技术挑战 —— 例如缺少完善的 KV 缓存机制,以及未充分释放并行潜力 —— 推理速度远慢于同规模的 AR 模型。

一张图,开启四维时空:4DNeX让动态世界 「活」起来
仅凭一张照片,能否让行人继续行走、汽车继续飞驰、云朵继续流动,并让你从任意视角自由观赏? 南洋理工大学 S-Lab 携手上海人工智能实验室,给出肯定答案 ——4DNeX。 作为全球首个仅依赖单张输入即可直接输出 4D 动态场景的前馈(feed-forward) 框架,4DNeX 摆脱了游戏引擎与合成数据的束缚,首次大规模利用真实世界动态影像进行训练,实现「时空视频」的高效、多视角、高保真渲染。

CoRL 2025|隐空间扩散世界模型LaDi-WM大幅提升机器人操作策略的成功率和跨场景泛化能力
在机器人操作任务中,预测性策略近年来在具身人工智能领域引起了广泛关注,因为它能够利用预测状态来提升机器人的操作性能。 然而,让世界模型预测机器人与物体交互的精确未来状态仍然是一个公认的挑战,尤其是生成高质量的像素级表示。 为解决上述问题,国防科大、北京大学、深圳大学团队提出 LaDi-WM(Latent Diffusion-based World Models),一种基于隐空间扩散的世界模型,用于预测隐空间的未来状态。

SEAgent:开启从实战经验中自我进化的GUI智能体新纪元
当前计算机使用智能体(CUA)的发展,主要依赖于大量昂贵的人工标注数据 。 这极大地限制了它们在缺少现成数据的新颖或专业软件中的应用能力 。 为了打破这一瓶颈,来自上海交通大学和香港中文大学的学者们提出了 SEAgent,一个全新的、无需任何人类干预,即可通过与环境交互来自主学习和进化的智能体框架。

简单即强大:全新生成模型「离散分布网络DDN」是如何做到原理简单,性质独特?
本文作者杨磊,目前在大模型初创公司阶跃星辰担任后训练算法工程师,其研究领域包括生成模型和语言模型后训练。 在这之前,他曾在旷视科技担任了六年的计算机视觉算法工程师,从事三维视觉、数据合成等方向。 他于 2018 年本科毕业于北京化工大学。

GPT-5、Grok 4、o3 Pro都零分,史上最难AI评测基准换它了
前沿 AI 模型真的能做到博士级推理吗? 前段时间,谷歌、OpenAI 的模型都在数学奥林匹克(IMO)水平测试中达到了金牌水准,这样的表现让人很容易联想到 LLM 是不是已经具备了解决博士级科研难题的推理能力? 然而,现实可能并不如想象中那么乐观。

追剧不断网,可能背后有个AI在加班,故障诊断准度破91.79%
当你的手机突然没信号时,电信工程师在做什么? 想象一下这样的场景:某个周五晚上,你正在用手机追剧,突然网络断了。 与此同时,成千上万的用户也遇到了同样的问题。

Meta视觉基座DINOv3王者归来:自监督首次全面超越弱监督,商用开源
计算机视觉领域的大部分下游任务都是从二维图像理解(特征提取)开始的。 在特征提取、语义理解、图像分割等 CV 基本任务中的模型三幻神分别是 SAM、CLIP 和 DINO,分别代表了全监督、弱监督和自监督三大数据训练范式。 在人工智能领域,自监督学习(SSL)代表了 AI 模型无需人工监督即可自主学习,它已成为现代机器学习中的主流范式。
多突触神经元模型问世,国内团队打造类脑计算新引擎,登上《自然·通讯》
本文第一作者为范良伟,国防科技大学讲师。 共同通讯作者分别为沈辉,国防科技大学教授;李国齐,中国科学院自动化研究所研究员、国家杰出青年基金获得者;胡德文,国防科技大学教授、国家杰出青年基金获得者、国防科技大学智能科学学院认知科学团队创始人和带头人,2012、2018 年两次获国家自然科学奖二等奖。 当前人工智能技术迅猛发展的同时,其高能耗问题也日益凸显。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉