本研究由中山大学、鹏城实验室、美团联合完成,第一作者王豪为中山大学博士研究生,主要研究方向为图像和视频分割、开放场景视觉感知、多模态大模型等。论文共同通讯作者为梁小丹教授和蓝湘源副研究员。
背景与动机
Segment Anything Model (SAM) 作为基础分割模型在密集分割掩码生成方面表现卓越,但其依赖视觉提示的单一输入模式限制了在广泛图像分割任务中的适用性。多模态大语言模型(MLLMs)虽在图像描述、视觉问答等任务中表现出色,但输出局限于文本生成,无法直接处理像素级视觉任务,这一根本性限制阻碍了通用化模型的发展。
中山大学、鹏城实验室、美团联合提出 X-SAM—— 一个统一的图像分割多模态大模型,将分割范式从 「分割万物」扩展到 「任意分割」。X-SAM 引入了统一框架,使 MLLMs 具备高级像素级感知理解能力。研究团队提出了视觉定位分割(Visual Grounded Segmentation, VGS)新任务,通过交互式视觉提示分割所有实例对象,赋予 MLLMs 视觉定位的像素级理解能力。为支持多样化数据源的有效训练,X-SAM 采用统一训练策略,支持跨数据集联合训练。实验结果显示,X-SAM 在广泛的图像分割基准测试中达到最先进性能,充分展现了其在多模态像素级视觉理解方面的优越性。

论文地址:https://arxiv.org/pdf/2508.04655
代码地址:https://github.com/wanghao9610/X-SAM
Demo地址: http://47.115.200.157:7861
方法设计
X-SAM 设计了通用输入格式和统一输出表示:
1)文本查询输入(Text Query):
适用于通用分割、开放词汇分割、指代分割、GCG 分割、推理分割
采用特殊短语标记 < p > 和 </p > 标注类别 / 短语 / 句子
格式化为:"<p>category/phrase/sentence</p>"
2)视觉查询输入(Vision Query):
适用于交互式分割和 VGD 分割任务
支持点、涂鸦、边界框、掩码等多种视觉提示形式
使用专用标记 < region > 表示视觉提示
格式化为:"<p><region></p>"
3)统一输出表示:
引入特殊标记 < SEG > 表示分割结果
<p > 和 </p > 标记间的潜在语言嵌入作为分割解码器的条件嵌入
X-SAM 采用端到端的统一分割 MLLM 架构,包含以下核心组件:
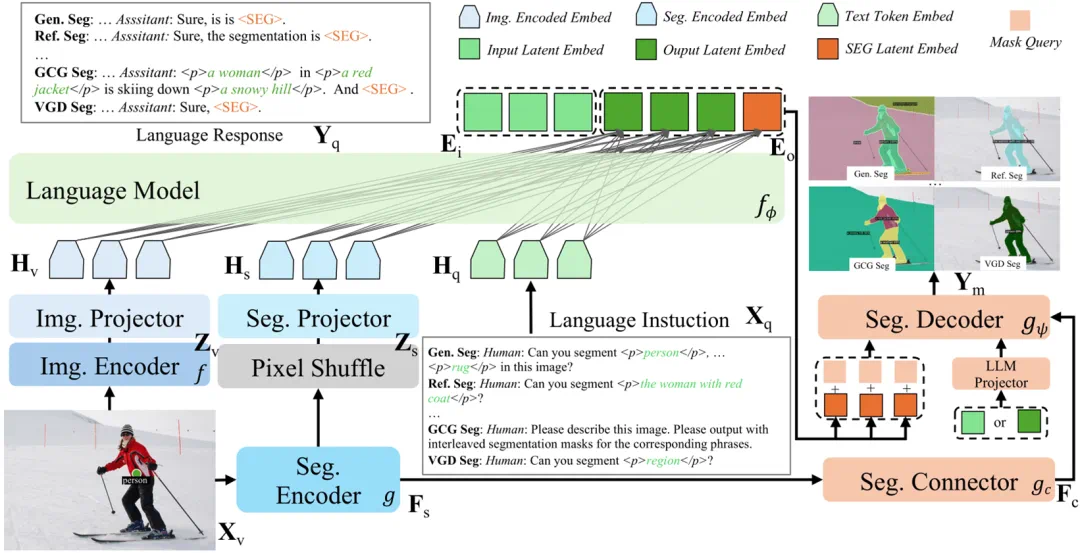
1)双编码器设计(Dual Encoders)
图像编码器:采用 SigLIP2-so400m 提取全局图像特征,提升图像理解能力。
分割编码器:采用 SAM-L 提取细粒度图像特征,提升图像分割效果。
2)双映射器架构(Dual Projectors)
为增强 LLM 的图像理解能力,X-SAM 采用特征融合策略。
分割特征投影:利用像素重排(pixel-shuffle)操作减少空间尺寸,通过 MLP 投影到语言嵌入空间
图像特征投影:直接通过 MLP 投影与分割特征连接后输入 LLM
3)分割连接器(Segmentation Connector)
针对图像分割任务对细粒度多尺度特征的需求,设计了分割连接器,为分割解码器提供丰富的多尺度信息。
下采样路径:通过 0.5 倍像素重排生成 1/32 尺度特征;
上采样路径:通过 2.0 倍像素重排生成 1/8 尺度特征;
原始特征:保持 1/16 尺度特征。
4)统一分割解码器(Segmentation Decoder)
替换 SAM 原始解码器,采用 Mask2Former 解码器架构。
模块优势:支持单次分割所有对象,克服 SAM 单对象分割限制。
模块特点:引入潜在背景嵌入表示所有任务的 "忽略" 类别,实现一个解码器适配所有分割任务。
X-SAM 采用三阶段渐进式训练策略来优化多样化图像分割任务的性能:
1)第一阶段:分割器微调(Segmentor Fine-tuning)
训练目标:微调分割器提升分割能力。
训练配置:参考 Mask2Former 训练流程,在 COCO-Panoptic 数据集上训练。
优化策略:训练分割器所有参数,分割编码器采用较低学习率训练
损失函数:
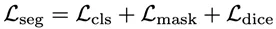
2)第二阶段:对齐预训练(Alignment Pre-training)
训练目标:对齐语言嵌入和视觉嵌入。
训练配置:参考 LLaVA 一阶段训练流程,在 LLaVA-558K 数据集上训练。
优化策略:冻结双编码器和 LLM 参数,仅训练双投影器。
损失函数:
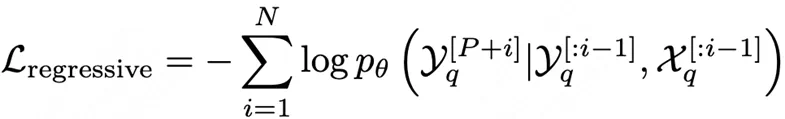
3)第三阶段:混合微调(Mixed Fine-tuning)
训练目标:在多个数据集上进行端到端协同训练
优化策略:微调模型所有参数,分割编码器和图像编码器采用较低学习率训练。
损失函数:
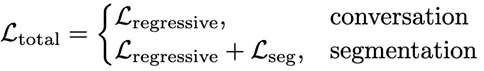
针对训练数据集规模差异(0.2K 到 665K 样本),X-SAM 采用数据集平衡重采样策略:
数据集级别重复因子: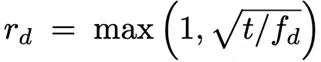
其中 t 为控制过采样比例的超参数,f_d 为数据集 d 的频率。在混合训练过程中,根据 r_d 对数据集 d 进行重采样,改善在少样本数据集上的性能。
实验结果
综合性能指标
X-SAM 在超过 20 个分割数据集上进行了全面评估,涵盖 7 种不同的图像分割任务,实现了全任务最优性能。
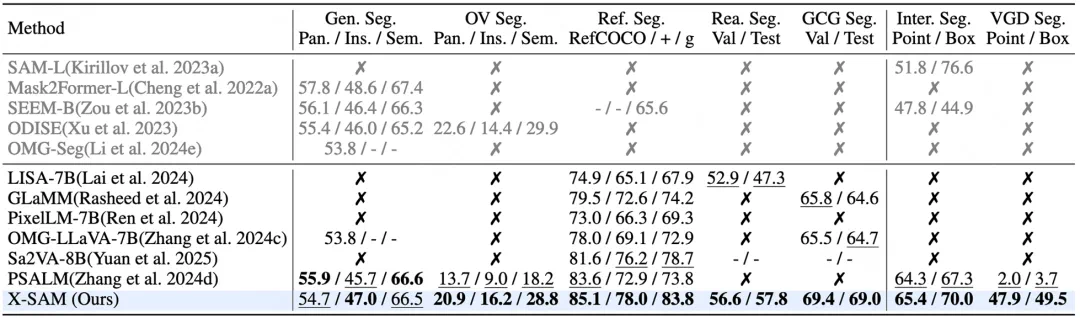
部分关键任务性能指标
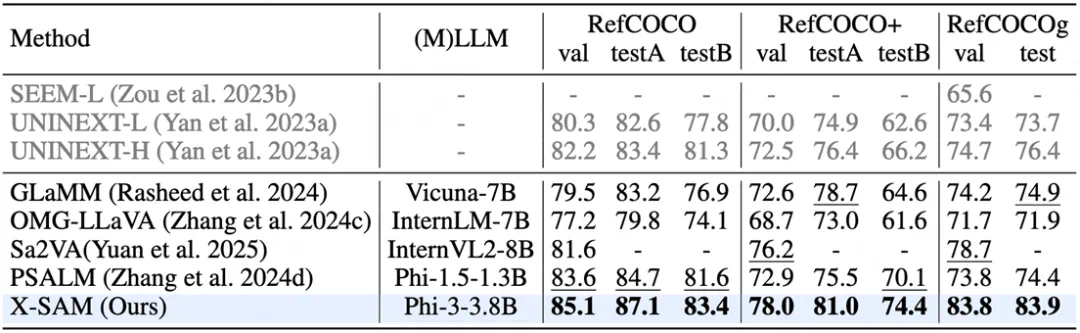
指代分割任务:
对话生成分割任务:
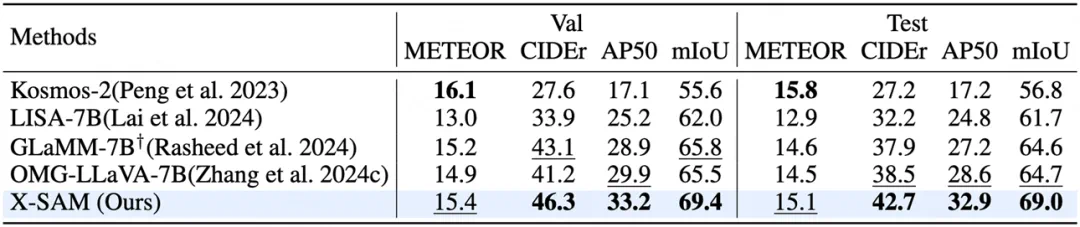
视觉定位分割任务:

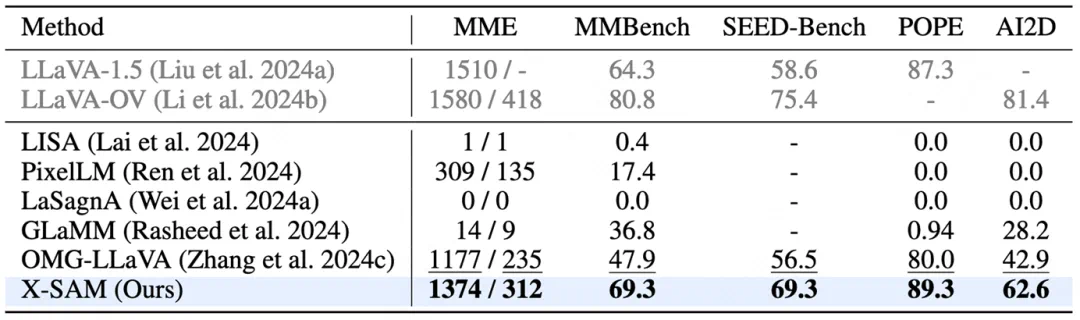
图文理解任务:
可视化结果展示


总结与展望
X-SAM 作为首个真正统一的分割多模态大语言模型,成功实现了从「segment anything」到「any segmentation」的重要跨越。通过创新的 VGD 分割任务、统一架构设计和渐进式训练策略,X-SAM 在保持各项任务竞争性能的同时,实现了更广泛的任务覆盖范围,为图像分割研究开辟了新方向,并为构建通用视觉理解系统奠定了重要基础。未来研究方向可以聚焦于视频领域的扩展。一是与 SAM2 集成实现图像和视频的统一分割,进一步扩展应用范围;二是将 VGD 分割扩展到视频中,引入视频中的时序信息,构建创新的视频分割任务,为视频理解技术发展提供新的可能性。