
要让视频生成模型真正成为模拟真实物理世界的「世界模型」,必须具备长时间生成并保留场景记忆的能力。然而,交互式长视频生成一直面临一个致命短板:缺乏稳定的场景记忆。镜头稍作移动再转回,眼前景物就可能「换了个世界」。
这一问题严重制约了视频生成技术在游戏、自动驾驶、具身智能等下游应用的落地。8 月初,Google DeepMind 发布的 Genie 3 引爆 AI 圈,以其在长视频生成中依旧保持极强场景一致性的能力,被视为世界模型领域的质变之作。不过遗憾的是,Genie 3 并未公开任何技术细节。
来自港大和快手可灵的研究团队近期发表的 Context as Memory 论文,可能是目前学术界效果上最接近 Genie 3 的工作,且投稿时间早于 Genie 3 的发布。早在此前研究中,团队就发现:视频生成模型能够隐式学习视频数据中的 3D 先验,无需显式 3D 建模辅助,这与 Genie 3 的理念不谋而合。如下是一个结果展示:
技术上,团队创新性地提出将历史生成的上下文作为「记忆」(即 Context-as-Memory),利用 context learning 技术学习上下文条件,从而在整段长视频生成中实现前后场景一致性。
进一步地,为了高效利用理论上可无限延长的历史帧序列,论文提出了基于相机轨迹视场(FOV)的记忆检索机制(Memory Retrieval),从全部历史帧中筛选出与当前生成视频高度相关的帧作为记忆条件,大幅提升视频生成的计算效率并降低训练成本。
在数据构建上,团队基于 Unreal Engine 5 收集了多样化场景、带有精确相机轨迹标注的长视频,用于充分训练和测试上述技术。用户只需提供一张初始图像,即可沿设定的相机轨迹自由探索生成的虚拟世界。

论文标题:Context as Memory: Scene-Consistent Interactive Long Video Generation with Memory Retrieval
项目主页:https://context-as-memory.github.io/
论文地址:https://arxiv.org/pdf/2506.03141
Context as Memory 能力展示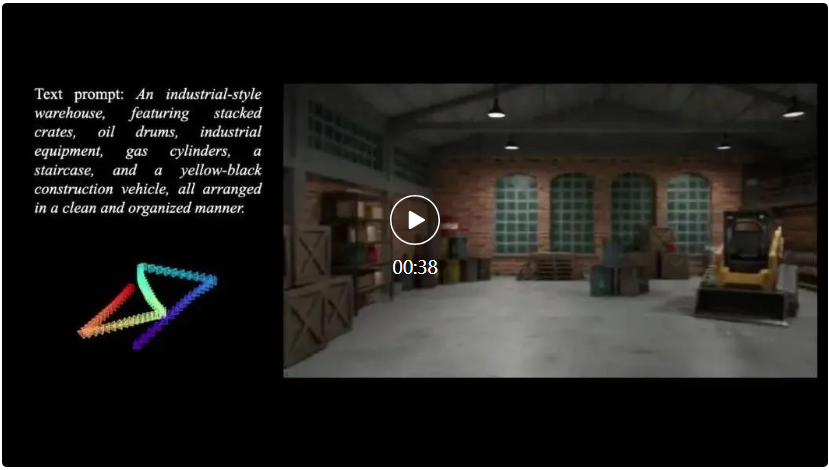

从上述视频可以观察到,Context as Memory 可以在几十秒的时间尺度下保持原视频中的静态场景记忆力,并在不同场景有较好的泛化性。
更多示例请访问项目主页:https://context-as-memory.github.io/
Context as Memory 创新点
研究者表示,Context as Memory 的主要创新点为:
我们提出了 Context as Memory 方法,强调将历史生成的上下文作为记忆,无需显式 3D 建模即可实现场景一致的长视频生成。
为了高效利用历史上下文,我们设计了 Memory Retrieval 方法,采用基于视场(FOV)重叠的相机轨迹规则进行动态检索,显著减少了需要学习的上下文数量,从而提高了模型训练与推理效率。
实验结果表明,Context as Memory 在长视频生成中的场景记忆力表现优越,显著超越了现有的 SOTA 方法,并且能够在未见过的开放域场景中保持记忆。
Context as Memory 算法解读
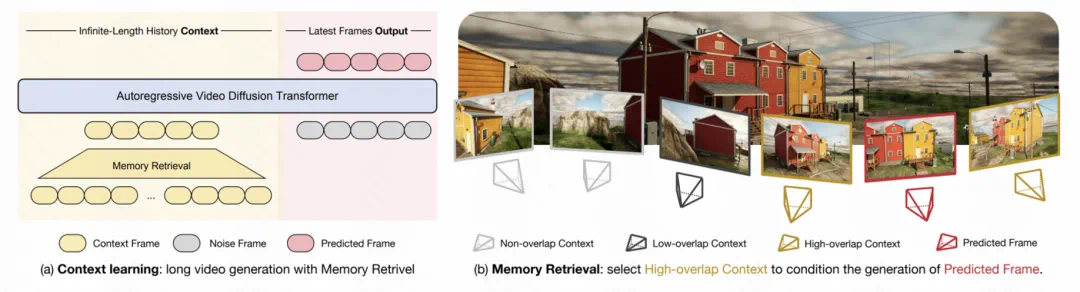
如上图(a)所示,Context-as-Memory 的长视频生成是通过基于 Context learning 的视频自回归生成来实现的,其中,所有历史生成的视频帧作为 context,它们被视为记忆力的载体。
进一步地,如上图(b)所示,为了避免将所有历史帧纳入计算所带来的过高计算开销,提出了 Memory Retrieval 模块。该模块通过根据相机轨迹的视场(FOV)来判断预测帧与历史帧之间的重叠关系,从而动态筛选出与预测视频最相关的历史帧作为记忆条件。此方法显著减少了需要学习的上下文数量,大幅提高了模型训练和推理的效率。
Context as Memory 实验结果

在实验中,研究者将 Context-as-Memory 与最先进的方法进行了比较,结果表明,Context-as-Memory 在长视频生成的场景记忆力方面,相较于这些方法,表现出了显著的性能提升。
总结
在本文中,研究者提出了 Context-as-Memory,一种能够实现静态场景记忆的交互式长视频生成模型。Context-as-Memory 的核心创新在于,提出了一种无需显式 3D 建模,仅通过对历史上下文学习,即可使视频生成模型具备 3D 一致性的理解与生成能力。此外,Memory Retrieval 模块的提出进一步减少了需要学习的上下文数量,大大提高了模型在训练和测试阶段的效率。
团队近期在世界模型与交互式视频生成领域已经积累了多篇研究成果。其中包括整理了交互式视频生成领域工作的综述论文和观点论文,系统性地总结了该领域的发展现状,还提出了世界模型的五大基础能力模块:Generation,Control,Memory,Dynamics 以及 Intelligence。这一框架为后续基础世界模型的研究指明了方向,具有很高的学习与参考价值。在该框架指导下,团队不仅提出了专注于 Memory 能力的 Context-as-Memory 工作,还在 ICCV 2025 上发表了 GameFactory 论文。GameFactory 聚焦于世界模型的可泛化开放域控制能力,能够生成无限可交互的新游戏,并被选为 Highlight 论文。
相关论文信息:
[1] A Survey of Interactive Generative Video. https://arxiv.org/pdf/2504.21853
[2] Position: Interactive Generative Video as Next-Generation Game Engine. https://arxiv.org/pdf/2503.17359
[3] GameFactory: Creating New Games with Generative Interactive Videos. ICCV 2025 Highlight. https://arxiv.org/pdf/2501.08325
[4] Context as Memory: Scene-Consistent Interactive Long Video Generation with Memory Retrieval. https://arxiv.org/pdf/2506.03141
更多技术细节请参阅原论文。


