工程

AI Agent组团搞事:在你常刷的App里,舆论操纵、电商欺诈正悄然上演
本文作者来自上海交通大学和上海人工智能实验室,核心贡献者包括任麒冰、谢思韬、魏龙轩,指导老师为马利庄老师和邵婧老师,研究方向为安全可控大模型和智能体。 在科幻电影中,我们常看到 AI 反叛人类的情节,但你有没有想过,AI 不仅可能「单打独斗」,还能「组团作恶」? 近年来,随着 Agent 技术的飞速发展,多 Agent 系统(Multi-Agent System,MAS)正在悄然崛起。

ICCV 2025 Highlight | 3D真值生成新范式,开放驾驶场景的语义Occupancy自动化标注!
该论文的第一作者和通讯作者均来自北京大学王选计算机研究所的 VDIG (Visual Data Interpreting and Generation) 实验室,第一作者为北京大学博士生周啸宇,通讯作者为博士生导师王勇涛副研究员。 VDIG 实验室近年来在 IJCV、CVPR、AAAI、ICCV、ICML、ECCV 等顶会上有多项重量级成果发表,多次荣获国内外 CV 领域重量级竞赛的冠亚军奖项,和国内外知名高校、科研机构广泛开展合作。 本文介绍了来自北京大学王选计算机研究所王勇涛团队及合作者的最新研究成果 AutoOcc。

杜克大学、Zoom推出LiveMCP‑101:GPT‑5表现最佳但未破60%,闭源模型Token效率对数规律引关注
研究概要:杜克大学与 Zoom 的研究者们推出了 LiveMCP-101,这是首个专门针对真实动态环境设计的 MCP-enabled Agent 评测基准。 该基准包含 101 个精心设计的任务,涵盖旅行规划,体育娱乐,软件工程等多种不同场景,要求 Agent 在多步骤、多工具协同的场景下完成任务。 实验结果显示,即使是最先进的模型在该基准上的成功率仍低于 60%,揭示了当前 LLM Agent 在实际部署中面临的关键挑战。

EMNLP 2025 | 动态压缩CoT推理新方法LightThinker来了
随着 AI 技术的飞速发展,从「快思考」到 「慢思考」,大语言模型(LLMs)在处理复杂推理任务上展现出惊人的能力。 无论是我们熟知的思维链(CoT),还是更复杂的深度思考模式(Thinking),都让 AI 的回答日益精准、可靠。 然而,这种性能的提升并非没有代价。

We-Math 2.0:全新多模态数学推理数据集 × 首个综合数学知识体系
本文作者来自北京邮电大学、腾讯微信、清华大学。 共同第一作者为北京邮电大学博士生乔润祺与硕士生谭秋纳,其共同完成的代表性工作 We-Math 于 ACL 2025 发表,并曾在 CVPR、ACL、ICLR、AAAI、ACM MM 等多个顶会中有论文发表。 本文的通讯作者为博士生导师张洪刚与微信视觉技术中心李琛,We-Math 系列工作为乔润祺在微信实习期间完成。

打破瓶颈,让RAG学会思考:中科大、智源等发布推理检索框架BGE-Reasoner
人工智能的浪潮正将我们推向一个由 RAG 和 AI Agent 定义的新时代。 然而,要让这些智能体真正「智能」,而非仅仅是信息的搬运工,就必须攻克一个横亘在所有顶尖团队面前的核心难题。 这个难题,就是推理密集型信息检索(Reasoning-Intensive IR)。
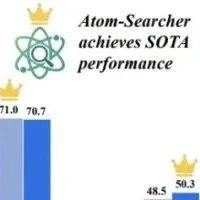
Agentic Deep Research新范式,推理能力再突破,可信度增加,蚂蚁安全团队出品
尽管 LLM 的能力与日俱增,但其在复杂任务上的表现仍受限于静态的内部知识。 为从根本上解决这一限制,突破 AI 能力界限,业界研究者们提出了 Agentic Deep Research 系统,在该系统中基于 LLM 的 Agent 通过自主推理、调用搜索引擎和迭代地整合信息来给出全面、有深度且正确性有保障的解决方案。 OpenAI 和 Google 的研究者们总结了 Agentic Deep Researcher 的几大优势:(1)深入的问题理解能力(Comprehensive Understanding):能够处理复杂、多跳的用户提问;(2)强大的信息整合能力(Enhanced Synthesis):能够将广泛甚至冲突的信息源整合为合理的输出;(3)减轻用户的认知负担(Reduced User Effort):整个 research 过程完全自主,不需要用户的过多干预。

「开发者私下更喜欢用GPT-5写代码」,Claude还坐得稳编程王座吗?
一直以来,Anthropic 的 Claude 被认为是处理编程任务的最佳模型,尤其是本月初发布的 Claude Opus 4.1,在真实世界编程、智能体以及推理任务上表现出色。 其中在软件编程权威基准 SWE-bench Verified 测试中,Claude Opus 4.1 相较于前代 Opus 4 又有提升,尤其在多文件代码重构方面表现出显著进步。 不过,在刚刚过去的这个周末,Claude 最强编程模型的地位似乎开始动摇了。
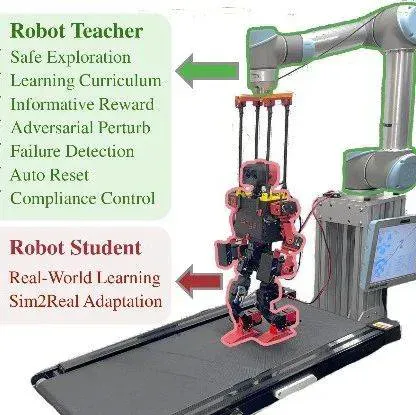
手把手教机器人:斯坦福大学提出RTR框架,让机械臂助力人形机器人真机训练
人形机器人的运动控制,正成为强化学习(RL)算法应用的下一个热点研究领域。 当前,主流方案大多遵循 “仿真到现实”(Sim-to-Real)的范式。 研究者们通过域随机化(Domain Randomization)技术,在成千上万个具有不同物理参数的仿真环境中训练通用控制模型,期望它能凭借强大的泛化能力,直接适应动力学特性未知的真实世界。

英伟达再出手!新型混合架构模型问世,两大创新实现53.6倍吞吐提速
又一个真正轻量、快速、强悍的大语言模型闪亮登场! Transformer 架构对计算和内存的巨大需求使得大模型效率的提升成为一大难题。 为应对这一挑战,研究者们投入了大量精力来设计更高效的 LM 架构。

视频「缺陷」变安全优势:蚂蚁数科新突破,主动式视频验证系统RollingEvidence
近日,蚂蚁数科 AIoT 技术团队独立完成的论文《RollingEvidence: Autoregressive Video Evidence via Rolling Shutter Effect》被网络安全领域学术顶会 USENIX Security 2025 录用。 该论文提出了一套创新性的主动式可信视频取证系统,利用相机卷帘门效应在视频中嵌入高维物理水印,并结合 AI 技术与概率模型进行精准验证,能够有效抵御深度伪造(Deepfake)和视频篡改等攻击。 相较于传统被动识别技术,该系统在检测准确率和安全防护能力上均有显著提升。

唯快不破:上海AI Lab 82页综述带你感受LLM高效架构的魅力
作者:孙伟高 上海人工智能实验室近年来,大语言模型(LLMs)展现出强大的语言理解与生成能力,推动了文本生成、代码生成、问答、翻译等任务的突破。 代表性模型如 GPT、Claude、Gemini、DeepSeek、Qwen 等,已经深刻改变了人机交互方式。 LLMs 的边界也不止于语言和简单问答。

突破长视频生成瓶颈:南大、TeleAI推出全新AI生成范式MMPL,让创意一镜到底
向迅之,南京大学 R&L 课题组在读博士生,导师是范琦副教授。 研究聚焦图像/视频生成与世界模型等 AIGC 方向。 你是否曾被 AI 生成视频的惊艳开场所吸引,却在几秒后失望于⾊彩漂移、画面模糊、节奏断裂?

大模型能否为不同硬件平台生成高性能内核?南大、浙大提出跨平台内核生成评测框架MultiKernelBench
在深度学习模型的推理与训练过程中,绝大部分计算都依赖于底层计算内核(Kernel)来执行。 计算内核是运行在硬件加速器(如 GPU、NPU、TPU)上的 “小型高性能程序”,它负责完成矩阵乘法、卷积、归一化等深度学习的核心算子运算。 当前,这些内核通常由开发者使用 CUDA、AscendC、Pallas 等硬件专用并行编程语言手工编写 —— 这要求开发者具备精湛的性能调优技巧,并对底层硬件架构有深入理解。

仅靠5000+样本,全新强化学习范式让30B轻松击败671B的DeepSeek V3
传统强化学习(RL)在有标准答案的指令遵循任务(如数学、代码)上已趋成熟,但在开放式的创意写作领域却因缺乏客观对错而举步维艰。 如何让 RL 突破「可验证奖励」的边界? 蚂蚁技术研究院联合浙江大学开源全新强化学习范式 Rubicon,通过构建业界最大规模的 10,000 条「评分标尺」,成功将强化学习的应用范围拓展至更广阔的主观任务领域。

Chain-of-Agents: OPPO推出通用智能体模型新范式,多榜单SOTA,模型代码数据全开源
本文通讯作者周王春澍,OPPO个性化AI实验室负责人,主要研究方向是AI个性化、智能体的自主进化和强化学习、以及大模型和智能体的记忆系统等。 本文核心贡献者均来自OPPO个性化AI实验室的AI智能体团队。 近年来,以多智能体系统(MAS)为代表的研究取得了显著进展,在深度研究、编程辅助等复杂问题求解任务中展现出强大的能力。

KDD 2025 Best Paper Runner-Up | EI-BERT:超紧凑语言模型压缩框架
本文第一作者王茂林,为香港城市大学博士生,导师为赵翔宇教授。 合作者包括蚂蚁集团储俊,臧晓玲,赵耀,谢锶聪和钟文亮。 该论文荣获 2025 年 KDD ADS Track Best Paper Award Runner-Up。

Cursor为Blackwell从零构建MXFP8内核,MoE层提速3.5倍,端到端训练提速1.5倍
在构建更强大的 AI 模型的这场竞赛中,传统路径很简单:升级到最新最强大的硬件。 但 Cursor 发现释放下一代 GPU 的真正潜力远非即插即用那么简单。 在从 NVIDIA 的 Hopper H100s 升级到新旗舰 Blackwell B200s 后,该团队遇到了一个「升级陷阱」:硬件性能翻倍,但实际训练速度却被 MoE 层的效率拖慢,新架构的设计反而放大了数据搬运和量化的开销。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉