编辑 | ScienceAI
蛋白质是生命活动的「分子机器」,而蛋白质之间的相互作用(PPIs)更是细胞运转的核心机制 —— 从免疫反应到代谢调控,从疾病发生到药物研发,几乎所有生命过程都离不开 PPIs 的精密协作。然而,传统实验手段解析 PPIs 成本高、周期长,如何通过 AI 技术高效预测 PPIs 的类型和亲和力,一直是生物信息学领域的重大挑战。
近日,来自湖南大学曾湘祥团队携手腾讯生命科学实验室,延世大学,和阿里国际提出了一种名为 LLaPA(Large Language and Protein Assistant)的多模态大语言模型,为破解这一难题提供了全新方案。该模型不仅在蛋白质相互作用预测任务中刷新了当前最优性能,更解决了传统方法难以处理未知蛋白质、多蛋白质复合物的痛点。该工作已被 ACL 2025 收录。

论文地址:https://aclanthology.org/2025.acl-long.554.pdf
代码地址:https://github.com/HHW-zhou/LLAPA
现有方法的三大局限性
过去几年,深度学习技术已广泛应用于 PPIs 预测,但现有方法始终存在三大局限:
一是过度简化任务难度。传统基于 PPI 网络的模型(如 GNN-PPI)在训练和测试时,会保留测试集中蛋白质对的连接信息,相当于「提前剧透」了待预测的相互作用关系。但现实中,蛋白质间的连接信息需要大量实验验证才能获得,这种「作弊式」预测在实际场景中根本行不通。
二是对「新面孔」蛋白质束手无策。当遇到未出现在已知 PPI 网络中的「未知蛋白质」时,传统模型无法利用网络拓扑信息,就像失去导航的船,预测准确度大幅下降。
三是无法处理「多人协作」。许多关键生物过程依赖多蛋白质复合物(如抗原 - 抗体复合物由 3 条链组成),但传统模型架构固定,只能处理两个蛋白质的相互作用,面对更多蛋白质时便「力不从心」。

(a)(b)(c) 现有方法将测试蛋白对之间的连接信息输入到了图编码器,导致预测任务被过度简化;(d)(e)(f) 移除这些连接信息之后许多蛋白质在网络中变成孤立结点,无法从 PPI 网络中获得有效信息,这些孤立蛋白质也等同于「未知蛋白质」。
LLaPA:让大语言模型学会
「解读」蛋白质网络
LLaPA 的核心创新在于将蛋白质序列、PPI 网络拓扑信息与大语言模型(LLM)深度融合,通过三大关键设计突破传统局限:
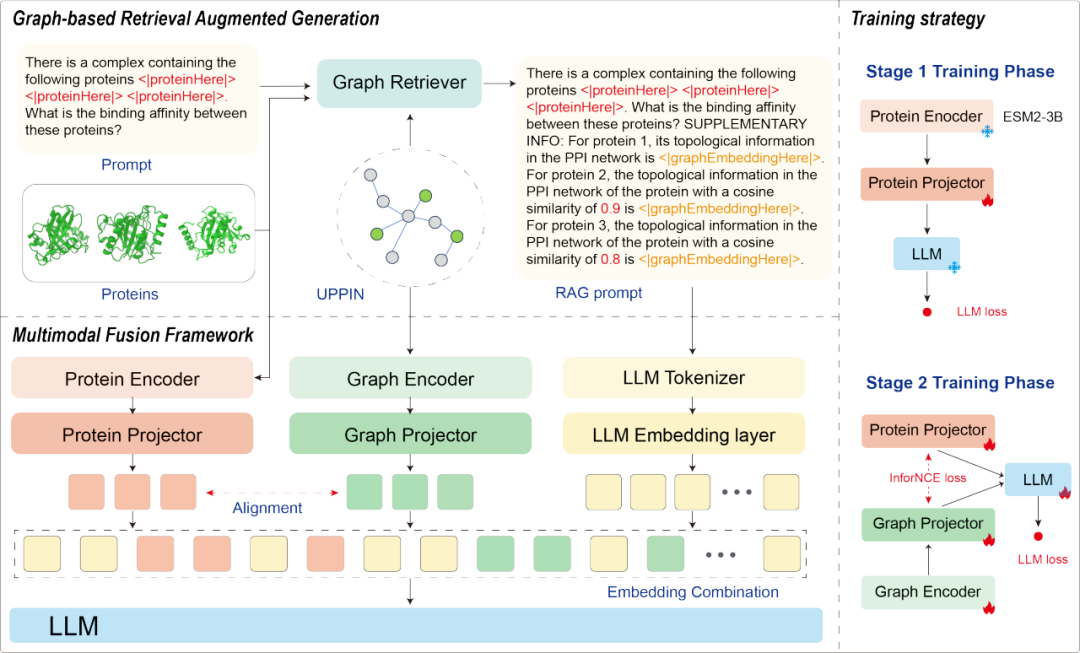
LLaPA 的模型架构。
1. 把 PPI 网络变成「可查询的知识库」
LLaPA 创造性地将 PPI 网络视为「外部知识」,通过检索增强生成(RAG)技术,像查字典一样调用网络信息。例如,当预测两个蛋白质的相互作用时,模型会自动从 PPI 网络中提取它们的拓扑特征(如邻居蛋白质、连接模式),并将这些信息转化为自然语言提示输入给 LLM,让模型结合蛋白质序列和网络背景综合判断。
2. 给「未知蛋白质」找个「参照物」
针对未知蛋白质,LLaPA 借鉴了生物学中「多序列比对」的思路:为未知蛋白质匹配 PPI 网络中序列相似的「近亲」,用「近亲」的拓扑信息作为替代。比如,若一个新蛋白质与网络中某已知蛋白质的序列相似度达 90%,就借用已知蛋白质的网络关系辅助预测,大幅提升对未知蛋白质的处理能力。
3. 构建更全面的「蛋白质社交网络」
团队还整合了 STRING、PDBBind、SAbDab 三大数据库,构建出包含 26180 个独特蛋白质、594216 条相互作用的「统一 PPI 网络(UPPIN)」。这个更庞大、更多样的「社交网络」,让模型能接触到更丰富的蛋白质「人际关系」,进一步提升泛化能力。
性能大比拼:刷新多项任务最优记录
在严格的实验验证中,LLaPA 展现出碾压性优势:
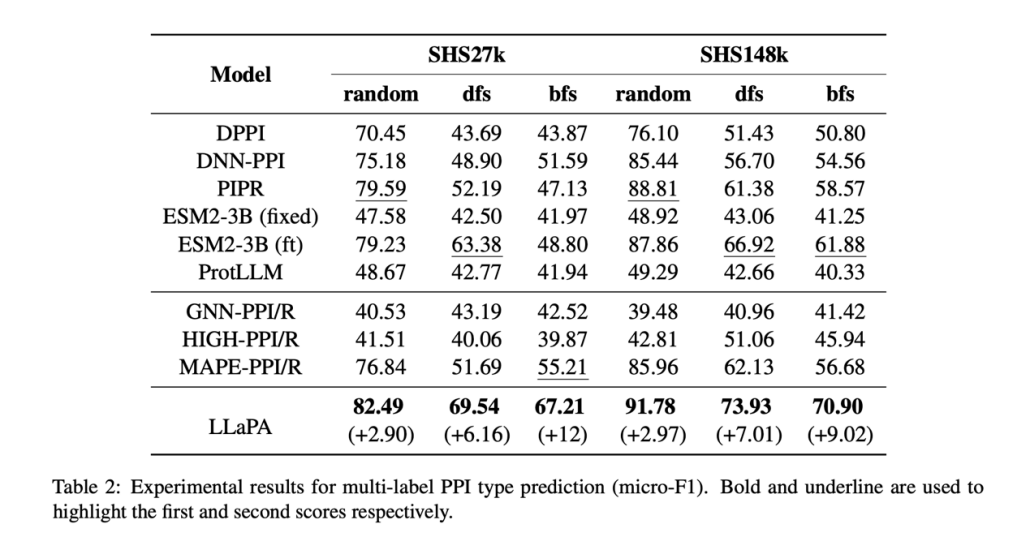
表 1:LLaPA 在多分类蛋白质蛋白质相互关系预测上的性能。
在多标签 PPI 类型预测任务中,面对 SHS27k 和 SHS148k 两个权威数据集,无论采用随机、DFS 还是 BFS 数据划分方法,LLaPA 的预测精度(micro-F1)均远超 DPPI、PIPR 等传统方法。尤其在更接近真实场景的 DFS 和 BFS 划分下(含大量未知蛋白质对),LLaPA 的性能领先第二名多达 12 个百分点。
在多蛋白质亲和力预测任务中,针对包含 2 到 16 个蛋白质的复合物,LLaPA 在 PDB2020 数据集上的平均绝对误差(MAE)和皮尔逊相关系数(PCC)均优于专用模型。即使面对 6 个蛋白质组成的复杂复合物,其预测精度仍能保持稳定,而传统模型只能处理 2 个蛋白质的简单情况。
消融实验进一步证明:UPPIN 网络的引入能使性能提升 26%,而蛋白质与网络信息的对齐机制可额外提升 3%,充分验证了各模块的有效性。
未来展望:从「预测」到「理解」生命机制
LLaPA 的突破不仅限于 PPIs 预测。凭借大语言模型的灵活性,它还能通过自然语言指令处理多种蛋白质任务 —— 例如输入「预测这三个蛋白质的结合强度」,模型就能直接返回结果。这种「懂生物 + 懂语言」的能力,为生物学家提供了更直观的研究工具。
当然,LLaPA 目前仍有局限:无法处理需要氨基酸级信息的任务(如结合位点预测),且对已有大量文献的知名蛋白质,尚未充分利用文本信息。但随着更大规模 PPI 网络的构建和多模态能力的深化,未来的蛋白质大模型有望从「预测相互作用」升级为「理解生命机制」,为疾病机理研究和新药研发开辟全新路径。
人工智能 × [ 生物 神经科学 数学 物理 化学 材料 ]