4D 空间智能重建是计算机视觉领域的核心挑战,其目标在于从视觉数据中还原三维空间的动态演化过程。这一技术通过整合静态场景结构与时空动态变化,构建出具有时间维度的空间表征系统,在虚拟现实、数字孪生和智能交互等领域展现出关键价值。
当前研究主要围绕两大技术维度展开:基础重建层面聚焦深度估计、相机定位、动态点云等底层视觉要素的精准提取;高阶理解层面则致力于解析场景组件的时空关联与物理约束。
这种多维度的空间建模能力正成为新一代人工智能发展的基础设施——无论是构建具身智能的环境认知体系,还是训练具备物理常识的世界模型,高保真的 4D 空间表征都发挥着基石作用。
值得注意的是,前沿研究正从单纯的几何重建转向对场景物理属性和交互逻辑的建模,这种转变使得空间智能不仅能呈现视觉真实的动态场景,更能支撑智能体与虚拟环境的拟真交互。
为了填补关于 4D 空间智能重建分析的空白,南洋理工大学 S-Lab、香港科技大学以及德州农工大学的研究者们全面调研了该领域的发展和最前沿的研究方法,撰写了综述论文,对 400 余篇代表性论文进行了系统归纳和分析。

✍🏻️Paper:Reconstructing 4D Spatial Intelligence: A Survey
📄 arXiv:https://arxiv.org/abs/2507.21045
🌍Project Page:https://github.com/yukangcao/Awesome-4D-Spatial-Intelligence
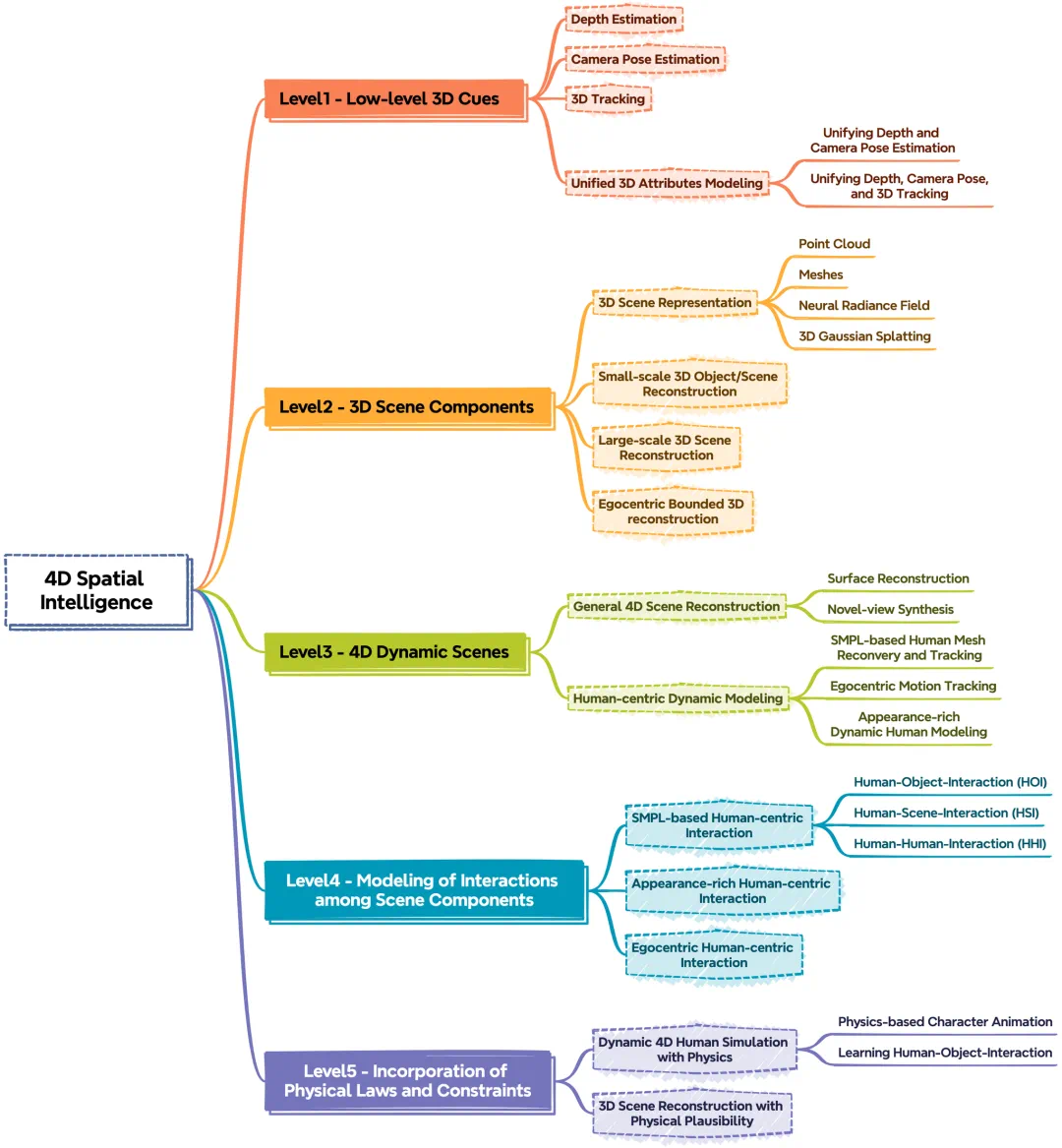
他们提出了一种新的分析视角,将已有方法按照空间智能的建构深度划分为五个递进的层次:
第一层(Level 1):底层三维属性的重建(如深度、位姿、点云图等)
第二层(Level 2):三维场景组成要素的重建(如物体、人体、建筑、场景等)
第三层(Level 3):完整的 4D 动态场景的重建
第四层(Level 4):包含场景内部组成部分之间交互关系的重建
第五层(Level 5):引入物理规律以及相关约束条件的重建
主体内容与结构一览
第一层(Level 1):底层三维属性的重建(如深度、位姿、点云图等)
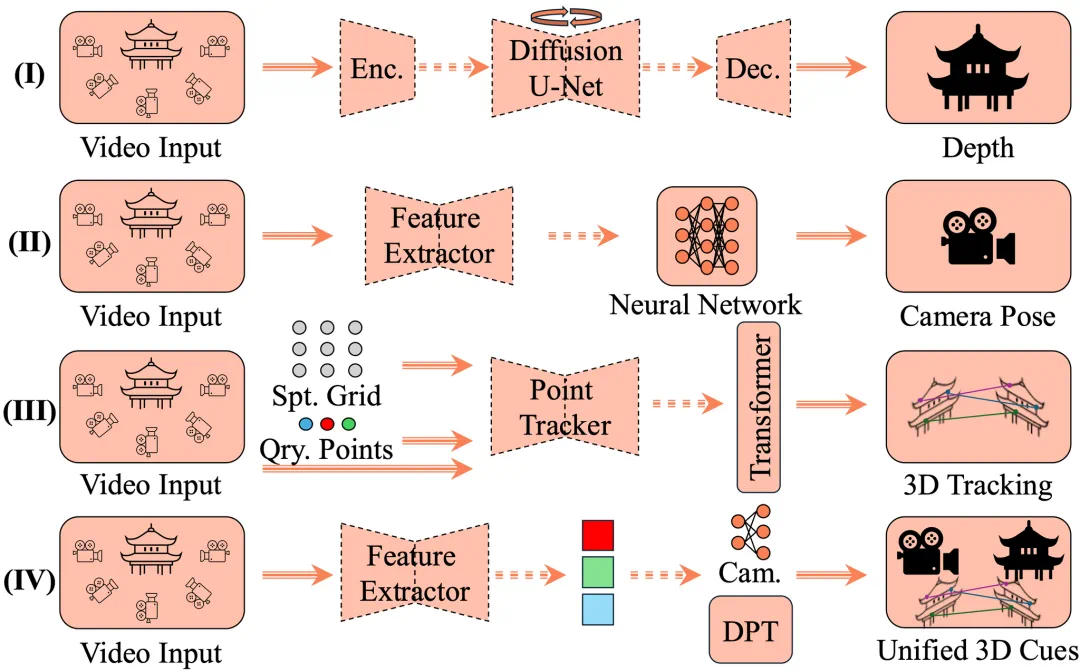
三维场景理解的基石在于对底层视觉线索的精准恢复,这一层级聚焦于四大核心要素:深度感知、相机定位、点云构建与动态跟踪。这些基础组件共同构成了三维空间的数字化骨架。
传统方法通常将其分解为多个独立子任务,如关键点检测与匹配(SIFT、SuperPoint、LoFTR 等)、鲁棒估计(AffineGlue)、运动恢复结构(SfM)、光束法平差(BA)以及多视图立体匹配(MVS)。
近年来,DUSt3R 等系列工作提出联合优化策略,实现了更高效的协同推理。基于 Transformer 的 VGGT 框架进一步实现了端到端的快速重建,可在秒级内完成底层 3D 线索的估计。
第二层(Level 2):三维场景组成要素的重建(如物体、人体、建筑、场景等)
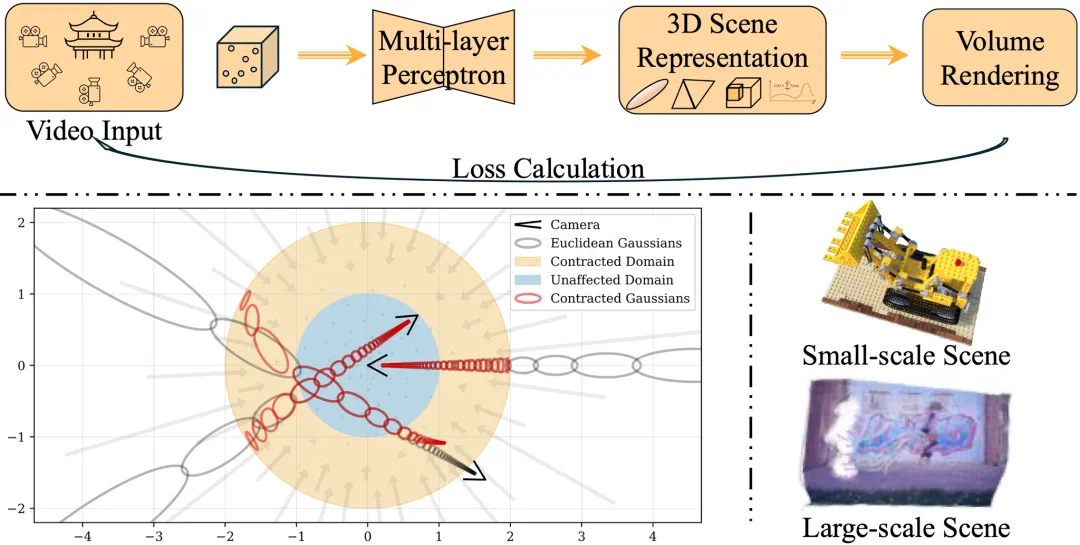
在完成底层 3D 线索提取后,Level 2 的研究重点转向场景中具体对象的精细化建模,包括人物、各类物体以及建筑结构等元素的几何重建。虽然现有方法能够处理这些元素的空间分布问题,但对它们之间的动态交互关系仍缺乏有效建模。
值得关注的是,随着 NeRF 神经辐射场、3D 高斯点云表示以及可变形网格(如 DMTet 和 FlexiCube)等创新技术的突破性进展,研究者们已经能够实现具有高度真实感的细节还原和整体结构保持。这些技术进步不仅显著提升了重建质量,更为影视特效制作、虚拟现实等应用场景提供了关键的技术支撑。
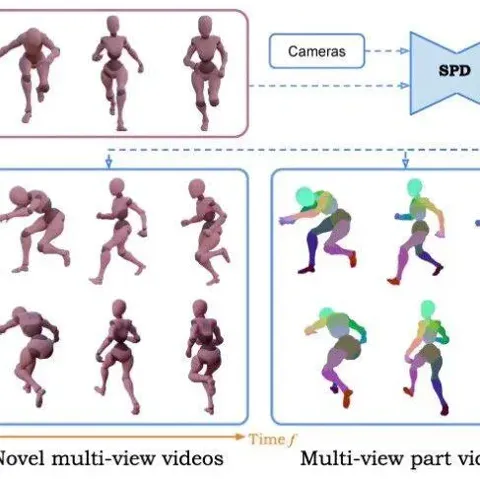
第三层(Level 3):完整的 4D 动态场景的重建
Level 3 研究致力于突破静态场景的限制,通过引入时间维度构建动态 4D 表征系统,为「子弹时间」等沉浸式视觉体验提供技术支撑。当前主流方法呈现两大技术路线:
形变场建模方案(如 NeRFies、HyperNeRF):在静态神经辐射场基础上,通过学习时空形变场来表征动态变化;
显式时序编码方案(如 Dynamic NeRF、DyLiN):将时间变量直接嵌入 3D 表征网络,实现时空连续建模。
从应用场景来看,相关研究主要聚焦两大方向:面向通用场景的 4D 重建技术,以及针对人体运动的专项动态建模方法。这种技术分野反映了不同应用场景对时空建模的差异化需求。
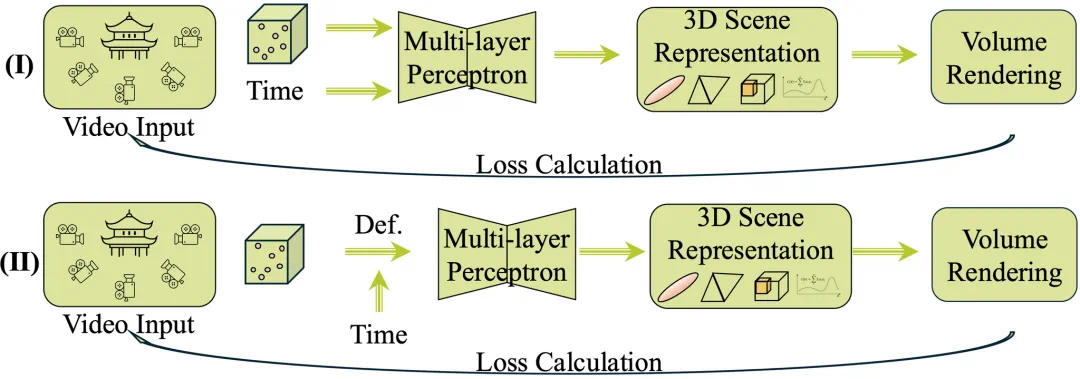
第四层(Level 4):包含场景内部组成部分之间交互关系的重建
Level 4 代表了空间智能研究的重要突破,其核心在于建立场景元素间的动态交互模型。作为交互行为的主导者,人体自然成为研究的重点对象——早期工作(如 BEHAVE、InterCap)开创性地实现了从视频中提取人体与物体的运动关联。得益于三维表征技术的革新,新一代算法(如 StackFlow、SV4D)在交互物体的几何外观和运动轨迹重建方面取得了显著提升。

特别值得注意的是,人-场景交互建模(HOSNeRF、One-shot HSI)这一新兴研究方向,通过解构人与环境的复杂互动机制,为构建具有物理合理性的数字世界奠定了重要基础。
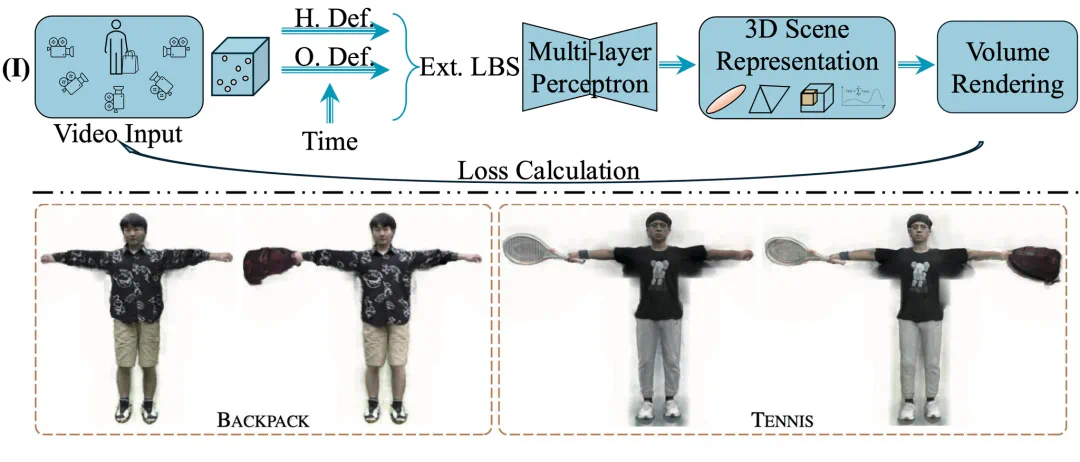
第五层(Level 5):引入物理规律以及相关约束条件的重建
Level 4 系统在交互建模方面取得重要突破,但仍面临物理真实性的关键挑战。现有方法普遍未能整合基础物理规律(如重力、摩擦等),导致其在机器人动作模仿等具身智能任务中存在明显局限。Level 5 的突破性进展主要体现在:
人体运动仿真:通过 PhysHOI、Perpetual Motion 等框架,结合 IsaacGym 仿真平台与深度强化学习,实现了从视频到物理合理动作的转化;
场景物理建模:PhysicsNeRF、PBR-NeRF 等创新方法将研究范畴扩展至物体形变、碰撞检测等复杂物理现象。
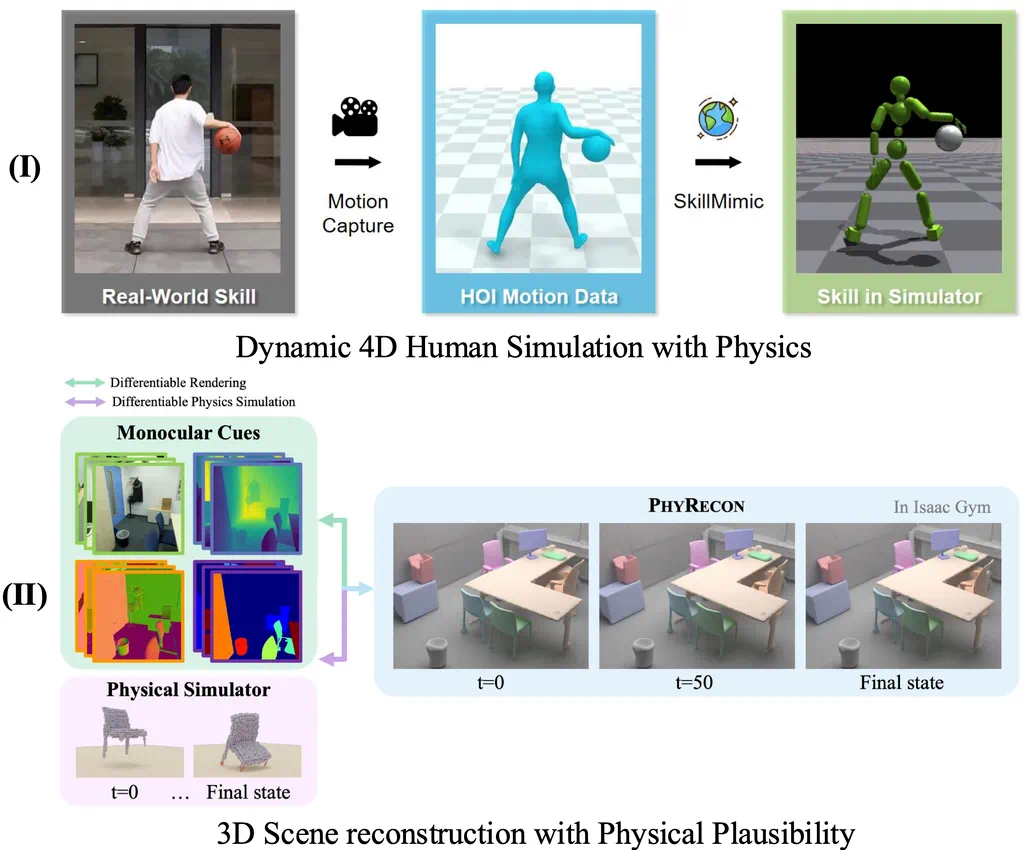
这个层级化的技术框架,展现了 AI 认知能力从基础到高阶的完整进化路径——就像教一个孩子先学会观察(Level 1),再认识物体(Level 2),接着理解运动(Level 3),然后掌握互动(Level 4),最终领悟物理规律(Level 5)。这种循序渐进的突破,正在推动虚拟世界从「看起来真实」向「动起来真实」的质变。
目前,这项技术已经在影视特效、自动驾驶仿真等领域大显身手。随着 Level 5 物理引擎的完善,未来的人机交互和数字孪生应用将更加逼真自然。或许在不久的将来,我们还将迎来 Level 6,让虚拟与现实的边界变得更加模糊……