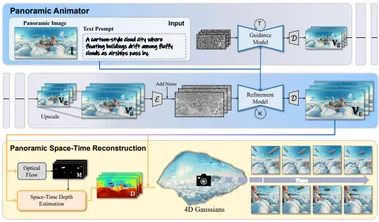
主要更新内容如下:
支持一键生成 32s 视频
支持音视频合成,“视频有声音了”(Text-2-Audio)
支持 4D 生成,可以从单一视频生成时空一致的 4D 内容
IT之家附部分视频预览:
据介绍,Vidu 是自 Sora 发布之后,全球率先取得重大突破的视频大模型,并且仍在加速迭代提升中。
据IT之家此前报道,Vidu 模型融合 Diffusion 与 Transformer,开创性创建了 U-ViT,在 4 月发布时支持一键生成长达 16 秒、分辨率高达 1080P 的高清视频内容。官方表示 Vidu 不仅能够模拟真实物理世界,还拥有丰富想象力,具备多镜头生成、时空一致性高等特点。
相关阅读:
《中国首个 Sora 级模型 Vidu 发布:可生成最长 16 秒、最高 1080P 视频》