AI看世界的方式,与人类大脑保持一致。
但究竟是什么因素驱动了这种脑-模型相似性,至今仍缺乏清晰认识。
为此,FAIR与巴黎高等师范学院通过训练自监督视觉Transformer模型(DINOv3),并使用功能性磁共振成像(fMRI )和脑磁图(MEG)从不同指标评估脑-模型相似性。

结果发现,模型大小、训练数据量和图像类型都会影响模型与大脑的相似度,而且这些因素之间还有相互作用。
特别是,规模最大、训练量最多,并使用人类相关图像训练的DINOv3模型,在脑相似性评分最高。
研究还发现,类脑表征在AI模型中的出现遵循特定的时间顺序:模型先对齐人类早期感觉皮层表征,而要像大脑的高层区域(例如前额叶)一样处理信息,则需更多训练数据。
这一发展轨迹与人类大脑皮层的结构与功能特性高度一致。模型在训练后期学到的表征,恰好对应大脑中发育最晚、最厚、髓鞘最少、处理速度最慢的区域。
DINOv3是一种自监督视觉Transformer模型,已在17亿张自然图像上进行训练。
为了进行全面评估,研究人员从零训练了DINOv3模型的8个变体,以覆盖不同的模型规模、训练数据量和数据类型。
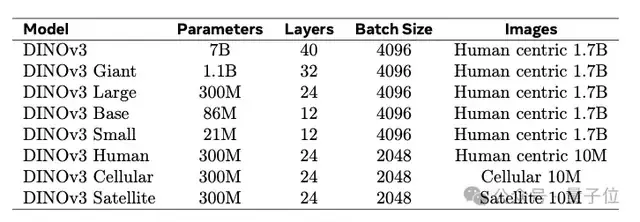
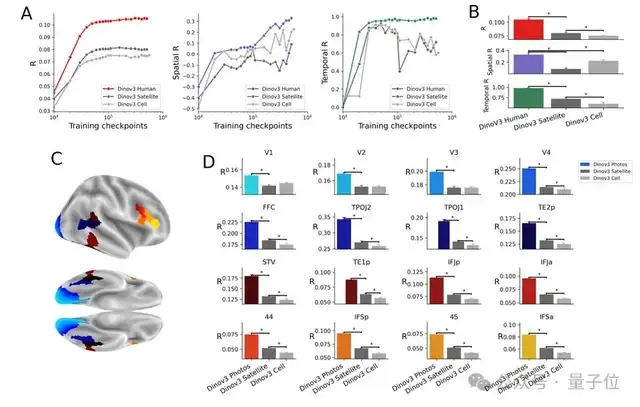
为了对比不同类型图像对模型训练的效果,研究者重新训练了三种DINOv3模型,分别使用人类中心图像、细胞图像和卫星图像,且每类图像数量均为1000万张。
在评估DINOv3模型与人类大脑视觉表征的相似度时,研究从功能性磁共振成像(fMRI )和脑磁图(MEG)中筛选出15个具有代表性的感兴趣区域(ROIs) ,覆盖从低级视觉皮层到高级前额叶皮层的完整视觉加工层级。
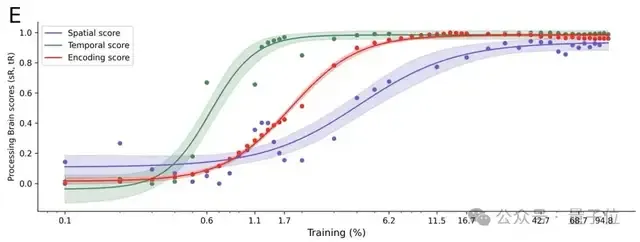
结果显示,随着训练的进行,DINOv3学到的表征会逐步与人脑的表征相一致。
其次,DINOv3学会的这种表征层级,与大脑中的空间层级和时间层级相对应。
为了继续探究DINOv3中类脑表征的出现,研究人员在DINOv3每个选定训练步骤上评估编码评分、空间评分和时间评分,并用“半达时间”总结其发展速度,即达到最终评分一半所对应的训练步骤。
令人惊讶的是,这些编码、空间和时间相关的评分都会在训练过程中出现,但出现的速度各不相同。
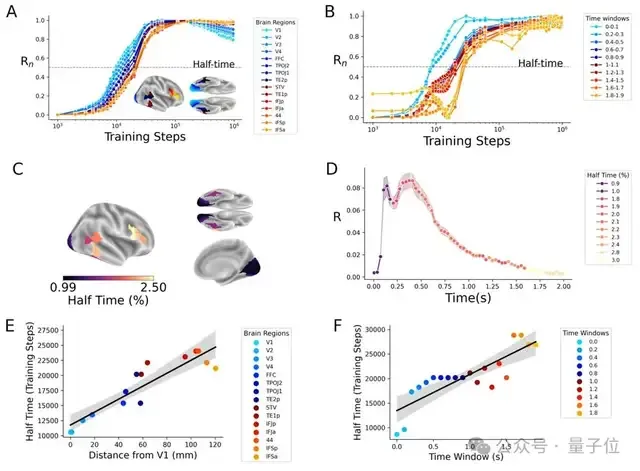
低级视觉区表征通常在DINOv3训练的早期就获得,而要学到与前额叶皮层类似的表征,则需要更多的训练。
其次是模型大小,更大的模型在训练中更快表现出类脑特征,脑评分更高,尤其是在高级脑区表现明显。
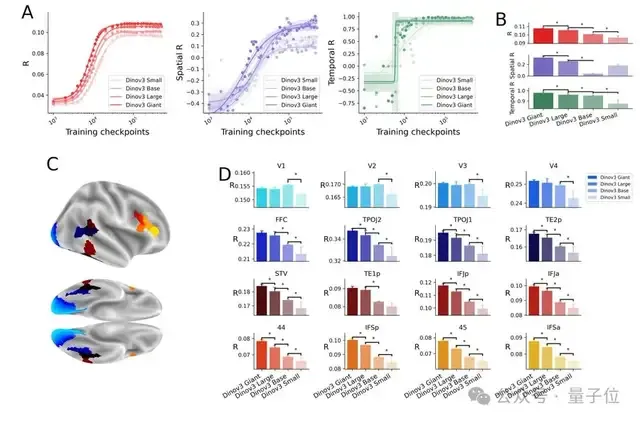
最后是图像类型,即使只使用卫星图像或细胞图像训练的模型,也能显著捕捉到脑信号,但使用人类中心图像训练的模型在所有脑区的编码效果更高。
这一结果可能是因为人类中心图像更接近大脑日常接触的视觉输入,而卫星图像和细胞图像则是大脑未经过训练处理的图像类型。
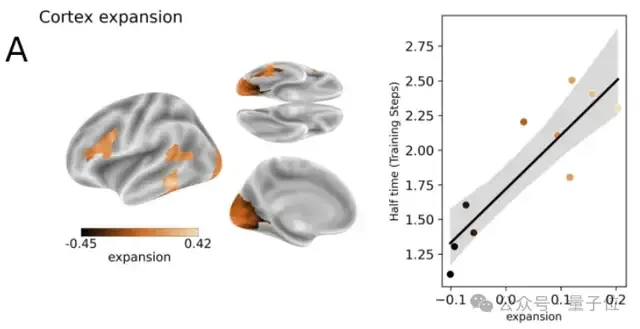
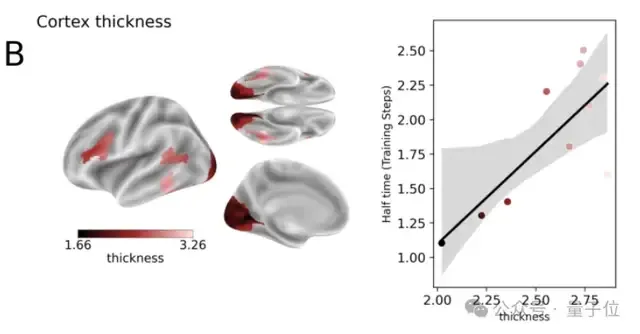
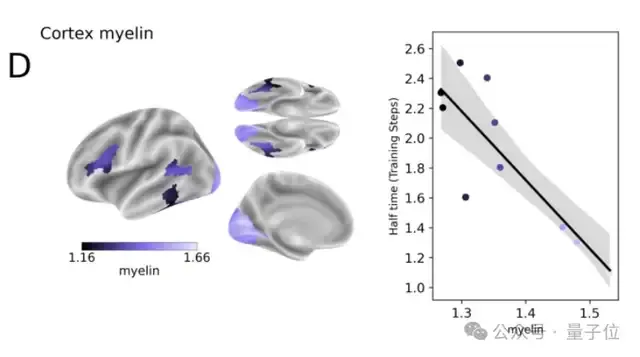
为探讨类脑表征与皮层的关系 ,研究人员分析了编码半达时间与皮层四种特性的相关性。
1、皮层扩展:他们比较婴儿与成人皮层结构的图谱,发现半达时间与皮层扩展高度正相关。这表明发育增长较大的皮层区域,其在AI模型中对应的表征出现较晚。
2、皮层厚度:皮层较厚的区域半达时间更长。
3、皮层动力学:内在动力学最慢的区域也往往具有最长的半达时间,即DINOv3的深层表征通常对应大脑反应较慢的区域。
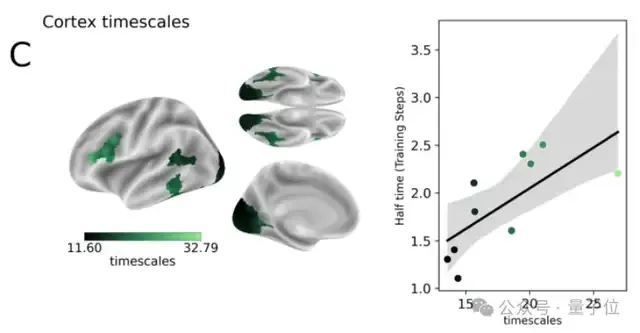
4、皮层髓鞘:髓鞘可加快神经信号传导,其浓度与半达时间呈显著负相关,说明髓鞘浓度越高,表征出现越早。
论文链接:https://arxiv.org/abs/2508.18226 参考链接:https://x.com/JeanRemiKing/status/1962453435199983982


