苹果机器学习团队上周在 GitHub 发布并开源了一款视觉语言模型 ——FastVLM,提供 0.5B、1.5B、7B 三个版本。
据介绍,该模型基于苹果自研 MLX 框架开发并借助 LLaVA 代码库进行训练,专为 Apple Silicon 设备的端侧 AI 运算进行优化。
技术文档显示,FastVLM 在保持精度的前提下,实现了高分辨率图像处理的近实时响应,同时所需的计算量比同类模型要少得多。
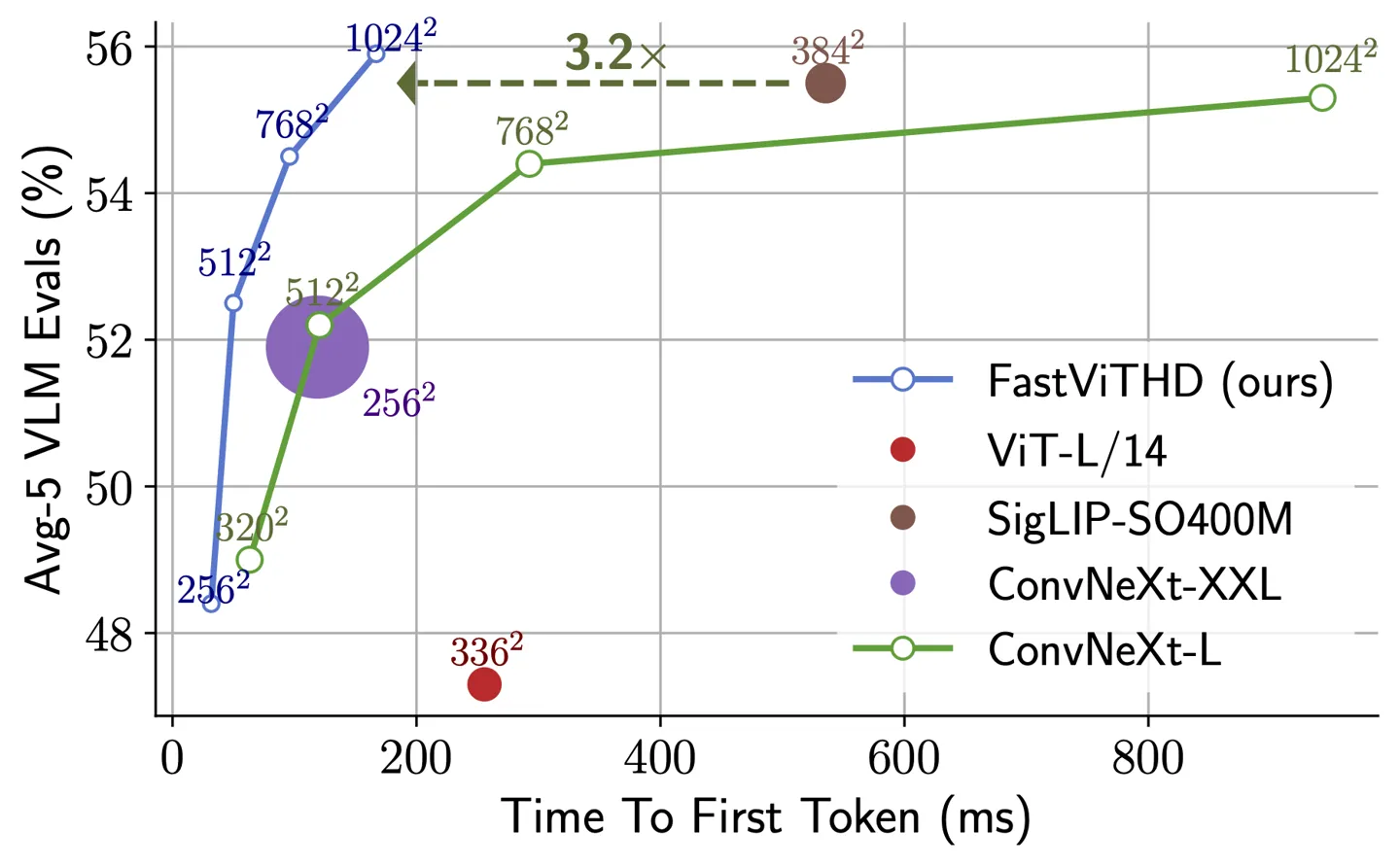
其核心是一个名为 FastViTHD 的混合视觉编码器。苹果团队表示,该编码器“专为在高分辨率图像上实现高效的 VLM 性能而设计”,其处理速度较同类模型提升 3.2 倍,体积却仅有 3.6 分之一。
亮点
FastViTHD 新型混合视觉编码器:专为高分辨率图像优化设计,可减少令牌输出量并显著缩短编码时间
最小模型版本性能对比:较 LLaVA-OneVision-0.5B 模型实现首词元(Token)响应速度提升 85 倍,视觉编码器体积缩小 3.4 倍
搭配 Qwen2-7B 大语言模型版本:使用单一图像编码器即超越 Cambrian-1-8B 等近期研究成果,首词元响应速度提升 7.9 倍
配套 iOS 演示应用:实机展示移动端模型性能表现
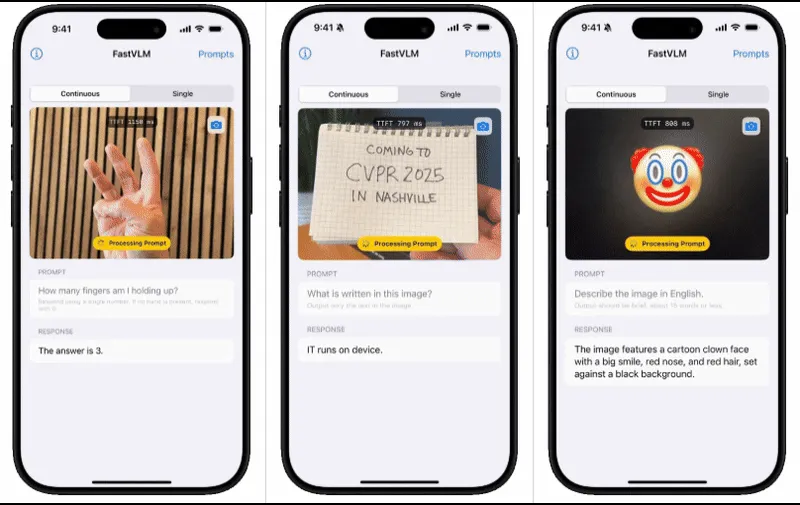
苹果技术团队指出:“基于对图像分辨率、视觉延迟、词元数量与 LLM 大小的综合效率分析,我们开发出 FastVLM—— 该模型在延迟、模型大小和准确性之间实现了最优权衡。”
该技术的应用场景指向苹果正在研发的智能眼镜类穿戴设备。多方信息显示,苹果计划于 2027 年推出对标 Meta Ray-Bans 的 AI 眼镜,同期或将发布搭载摄像头的 AirPods 设备。
FastVLM 的本地化处理能力可有效支持此类设备脱离云端实现实时视觉交互。AI在线查询获悉,MLX 框架允许开发者在 Apple 设备本地训练和运行模型,同时兼容主流 AI 开发语言。FastVLM 的推出证实苹果正构建完整的端侧 AI 技术生态。
参考资料:
https://github.com/apple/ml-fastvlm?tab=readme-ov-file
[2412.13303] FastVLM: Efficient Vision Encoding for Vision Language Models


