近日,字节跳动的研究与上海交通大学的团队共同推出了名为 ProtoReasoning 的新框架,旨在通过逻辑原型来增强大语言模型(LLMs)的推理能力。该框架利用结构化的原型表示,如 Prolog 和 PDDL,推动了跨领域推理的进展。
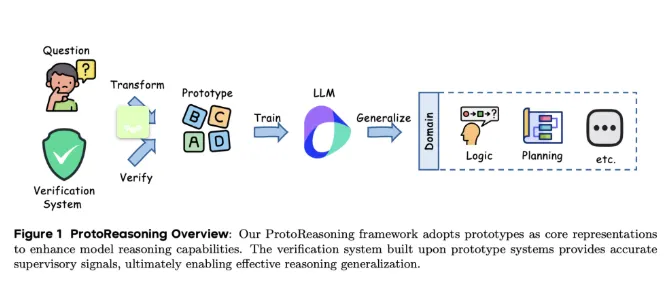
近年来,大语言模型在跨领域推理方面取得了显著突破,尤其是在长链推理技术的应用下。研究发现,这些模型在处理数学、编程等任务时,表现出了在逻辑难题和创意写作等无关领域的优异能力。然而,这种灵活性背后的原因尚未完全明确。一种可能的解释是,这些模型学习到了核心推理模式,即跨领域的抽象推理原型,这些原型能够帮助模型更好地应对不同形式的问题。
ProtoReasoning 框架通过使用结构化的原型表示来提升模型的推理能力,具体包括两个主要模块:原型构建器和验证系统。原型构建器将自然语言问题转换为形式化的表示,而验证系统则负责检查解答的正确性。在 Prolog 的应用中,研究人员设计了一个四步管道,生成多样的逻辑问题,并通过 SWI-Prolog 进行验证。对于规划任务,研究团队使用 PDDL 构建计划生成、完成和重排任务,并通过 VAL 验证器进行正确性检查。
在对 ProtoReasoning 框架的评估中,使用了一个具有1500亿参数的专家模型(其中150亿为活跃参数),并在经过精心挑选的高质量 Prolog 和 PDDL 样本上进行训练。结果显示,在逻辑推理、规划以及多项基准测试中,模型均表现出了显著的提升。特别是与自然语言版本进行的对比实验显示,基于 Prolog 的训练在逻辑推理方面表现接近于自然语言版本,进一步验证了结构化原型训练的有效性。
ProtoReasoning 框架展示了抽象推理原型在促进大语言模型跨领域知识转移中的重要作用。尽管实验结果令人鼓舞,但关于推理原型的具体性质仍需进一步理论探讨。未来的研究将致力于通过数学形式化这些概念,并利用开源模型和数据集进行验证。
论文:https://arxiv.org/abs/2506.15211
划重点:
🌟 ProtoReasoning 框架利用 Prolog 和 PDDL 提升大语言模型的逻辑推理能力。
🧠 通过结构化原型表示,模型在逻辑推理、规划和一般问题解决任务上显著提升。
🔍 未来研究将探讨推理原型的理论基础,并验证实验结果的有效性。


