
往期回顾:
一、AI秒级生成3D场景!厦大x腾讯开源FlashWorld
近日,AI为3D内容生成领域又迎来了一项突破性进展。厦门大学与腾讯联合研发的FlashWorld模型横空出世,仅凭单张图片或一段文字,就能在5-10秒内生成高质量3D场景,速度较以往提升10到100倍,同时渲染质量更加惊艳。
这项研究的问世,或许意味着我们离那个“人人都能快速创造3D世界”的时代又近了一步。
开源地址:https://imlixinyang.github.io/FlashWorld-Project-Page/

二、南洋理工&腾讯ARC:分钟级实时生成突破
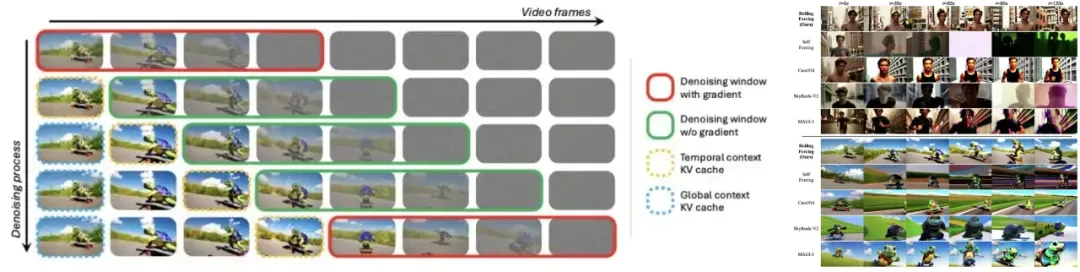
近日,南洋理工大学&腾讯ARC实验室:合作研发RollingForcing技术,通过联合去噪、注意力池、高效训练策略,单GPU实现分钟级实时长视频生成,解决误差累积问题,生成视频质量高。Rolling Forcing成功突破了实时长视频生成的不可能三角,在保持16 fps实时生成速度的同时,显著降低了长序列生成中的误差累积,实现了分钟级别的高质量视频流生成,为交互式世界模型、神经游戏引擎等应用提供了基础。
官方介绍:https://github.com/TencentARC/RollingForcing
三、Lovart平台上线“编辑元素”新功能
近日,针对海外市场的AI设计平台Lovart宣布上线新功能“编辑元素”,能够将图片中的不同元素自动分离独立图层,并灵活调整细节。
这一更新也解决了AI生图“难以局部修改”的常见痛点,Lovart的“编辑元素”功能,能够像PS分图层一样,自动识别生成图片中的各个元素,并将其拆分为独立图层。每个图层均可单独编辑并保存,且修改某一元素时不会干扰其他部分,大大提升了控制的精细度。

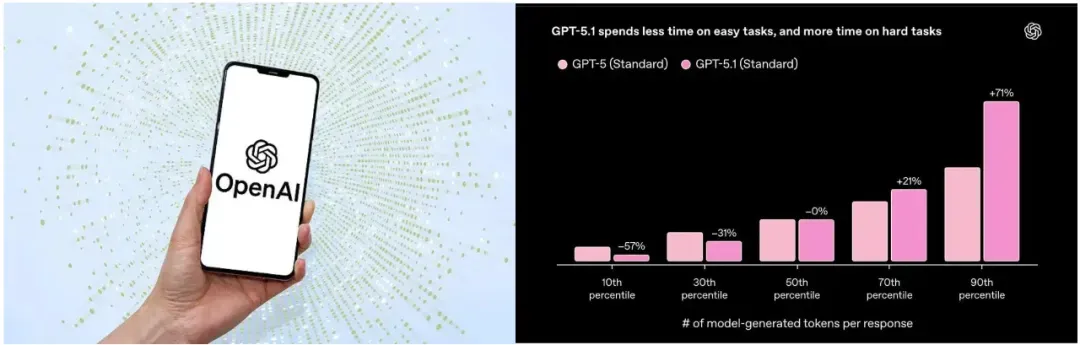
四、OpenAI发布GPT-5.1,智商情商双提升
11月12日,OpenAl正式官宣推出新一代旗舰模型GPT-5.1系列,官方表示此次升级旨在“让ChatGPT更智能,对话体验更有趣”。
此次发布距上一代GPT-5仅数月时间,此前GPT-5因缺乏“人味”、“刻板而缺乏创造力”引发用户争议,而GPT-5.1则实现了智能水平与沟通风格的双重升级。
OpenAI公司CEO萨姆•奥尔特曼表示,GPT-5.1升级给力,尤其是指令遵循和自适应思考的改进,整体的智力和沟通风格提升也很显著。
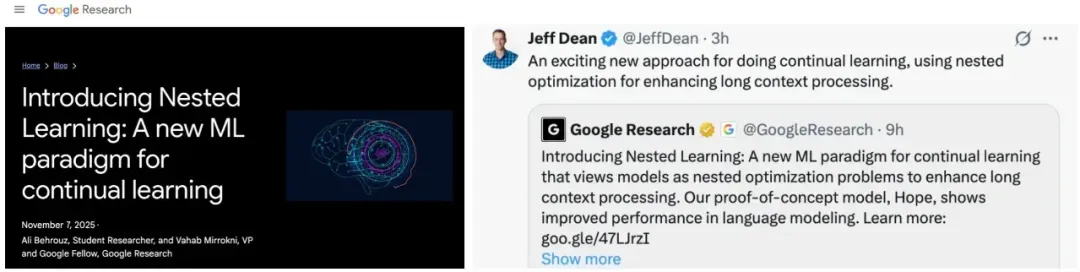
五、谷歌“嵌套学习”突破LLM遗忘瓶颈
近日,谷歌推出了一种全新的用于持续学习的机器学习范式——嵌套学习,模型不再采用静态的训练周期,而是以不同的更新速度在嵌套层中进行学习,即将模型视为一系列嵌套问题的堆叠,使其能够不断学习新技能,同时又不会遗忘旧技能。
这或将标志着人工智能朝着「真正像大脑一样进化的方向」迈出了一大步。嵌套学习代表了谷歌对深度学习理解迈进了新阶段,通过将架构与优化视为统一的、层次化的优化系统,打开了一个全新的设计维度。
六、英伟达发布OmniVinci全模态大模型
近日,英伟达(NVIDIA)开源了OmniVinci,一款能理解多模态世界的全模态大语言模型(Omni-Modal LLM)。
该模型实现了视觉、音频、语言在同一潜空间 (latent space)中的统一理解,让AI不仅能识别图像、听懂语音,还能推理、对话、生成内容。
这个9B的视觉-语音理解全模态模型刚上线就爆火,Huggingface模型权重目前已经有超过10000次下载量!
开源地址:https://github.com/NVlabs/OmniVinci

七、Meta开源1600语言语音识别系统
近日,Meta基础人工智能研究(FAIR)团队推出了“全语种自动语音识别系统”(Omnilingual ASR),该系统可支持1600多种语言的语音转写,大幅拓展了当前语音识别技术的语言覆盖范围。
据Meta介绍,在其支持的1600种语言中,有500种系首次被任何AI系统所覆盖。FAIR团队将该系统视为迈向“通用语音转写系统”的重要一步,有望助力打破全球语言壁垒,促进跨语言沟通与信息可及性。

八、Utopai Studios发布影视专用AI模型与工作流
近日,AI原生影视工作室Utopai Studios宣布推出专为电影与电视制作而设计的AI模型和工作流。
与目前主流的通用视频模型不同,Utopai的AI模型并非为了生成短视频或视觉效果,而是专为影视创作而生,具备“理解剧本、解析故事,并协助导演规划镜头和生成场景”的能力。
将这些环节整合为一体后,系统可以强化故事结构、表演呈现与镜头连贯性——这些都是专业影视制作的关键能力。



