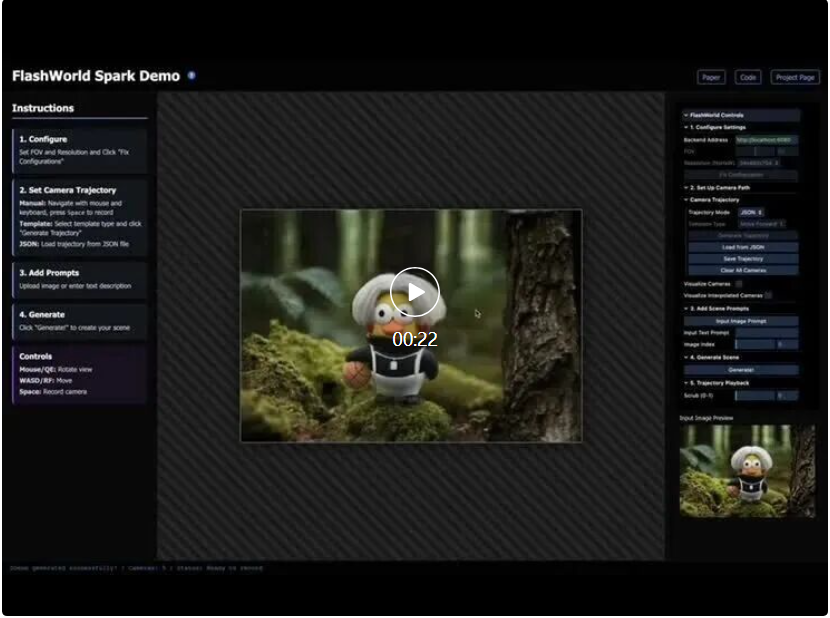
厦门大学和腾讯合作的最新论文《FlashWorld: High-quality 3D Scene Generation within Seconds》获得了海内外的广泛关注,在当日 Huggingface Daily Paper 榜单位列第一,并在 X 上获得 AK、Midjourney 创始人、SuperSplat 创始人等 AI 大佬点赞转发。

FlashWorld 不仅将三维场景的生成在单卡上做到了 5~10 秒(相比之前方法提速百倍),更统一支持了单张图片或文本输入,生成的场景可以在网页用户端实时渲染,同时质量还胜过其他同类闭源模型。

主页 :https://github.com/imlixinyang/FlashWorld-Project-Page
Github:https://github.com/imlixinyang/FlashWorld
Huggingface Demo:https://huggingface.co/spaces/imlixinyang/FlashWorld-Demo-Spark
论文:https://arxiv.org/pdf/2510.13678
目前,作者们还提供了 Huggingface 上的免费 Demo 可以试玩。我们迫不及待地进行了尝试,并且在同一个输入下与 WorldLabs 的 Marble 和前两天发布的 RTFM 模型比较了一下:
 |  |  |
从左至右:FlashWorld,Marble,RTFM
可以看到 FlashWorld 在预设轨迹下可以产生非常稳定、完整且高质量的渲染结果,生成速度比 Marble 的快速模式快 5 倍,而且完全通过前端渲染,不需要像 RTFM 一样需要等待连接后端 GPU 才能使用。
这是怎么做到的呢?
FlashWorld 动机
虽然现在视频模型成为了世界模型的主流,但其负载大的特点难以让每个人都能在自己的设备上进行体验。因此,FlashWorld 选择了基于 3DGS 为场景输出形式的技术路线,这也是为什么 FlashWorld 生成的结果可以在本地网页端实时渲染。
在传统生成 3DGS 场景的方法中,大约分为了两类:
一种是以多视角为中心的方案,代表方法为 CAT3D,Wonderland 等。它们使用了先通过扩散模型生成多视角图像或视频,再通过三维重建得到 3DGS 的两步框架。然而,因为使用的扩散模型往往会生成视角不一致的结果,这类方案容易产生杂乱的纹理细节。
另一种则为以三维为中心的方案,代表方法为 Director3D,DiffusionGS 等。它们把 3DGS 作为中介,直接用于多视角的去噪流程中。但因为场景数据相机标注往往不够准确以及模型知识不够强的问题,这类方案容易产生模糊的渲染效果。
FlashWorld 的核心,简而言之,就是用把 以多视角为中心的教师模型 通过蒸馏损失提升 以三维为中心的学生模型 的视觉质量,这样既保证了理论上的多视角一致性,又不断促使模型接近真实场景的图像质量,顺带地,还极大减少了去噪步数。
 |  |  |
视频为单图到三维场景生成效果,从左到右依次为同一个网络架构在 MV 模式、3D 模式,以及 FlashWorld 提出的跨模式蒸馏结果。
FlashWorld 方法
FlashWorld 包含了两个训练流程:
1. 双模式预训练:基于视频扩散先验,训练一个同时支持 以多视角为中心(MV)/ 以三维为中心(3D) 双模式输出的多视图扩散模型。
2. 跨模式后训练:以 MV 模式为教师、3D 模式为学生,进行分布匹配蒸馏,兼顾高保真与 3D 一致。
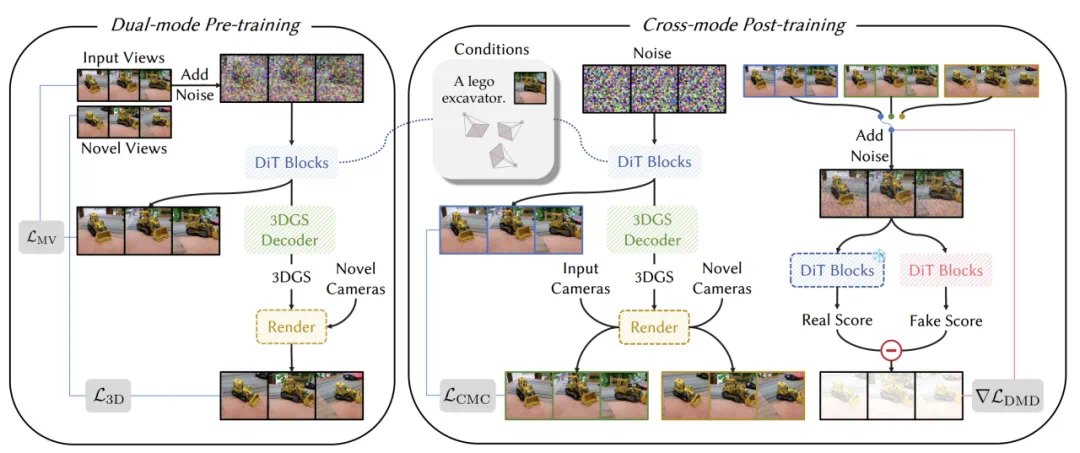
FlashWorld 还利用了分布匹配蒸馏不需要 Ground Truth 的特性,将随机的图像、文本和轨迹组合成分布外的输入进行训练,进一步提升学生模型对各种场景、风格、轨迹的泛化能力。
实验效果
FlashWorld 在各种任务上进行了充分全面的实验和对比。包括:
图生三维场景(最上一行为 FlashWorld 结果):

FlashWorld 竟然成功地生成出了整齐的栅栏(左上),这在以往的工作中几乎是不可能的。
文生三维场景(最上一行为 FlashWorld 结果):

FlashWorld 对于毛发这些细粒度的细节也有着非常好的生成能力,这在密集视角的重建中可能都是非常困难的问题,而 FlashWorld 竟然只需要输入文本。
Feifei Li 团队 WorldScore Benchmark(最左列为 FlashWorld 结果):

可以看到,FlashWorld 对于场景风格、语义和三维性也保持得非常好。
文生三维场景定性指标:

FlashWorld 在该 Benchmark 下以最快的速度领先与其他方法。
WorldScore 定性指标

FlashWorld 在该 Benchmark 下以最快的速度下获得了最高的平均分。
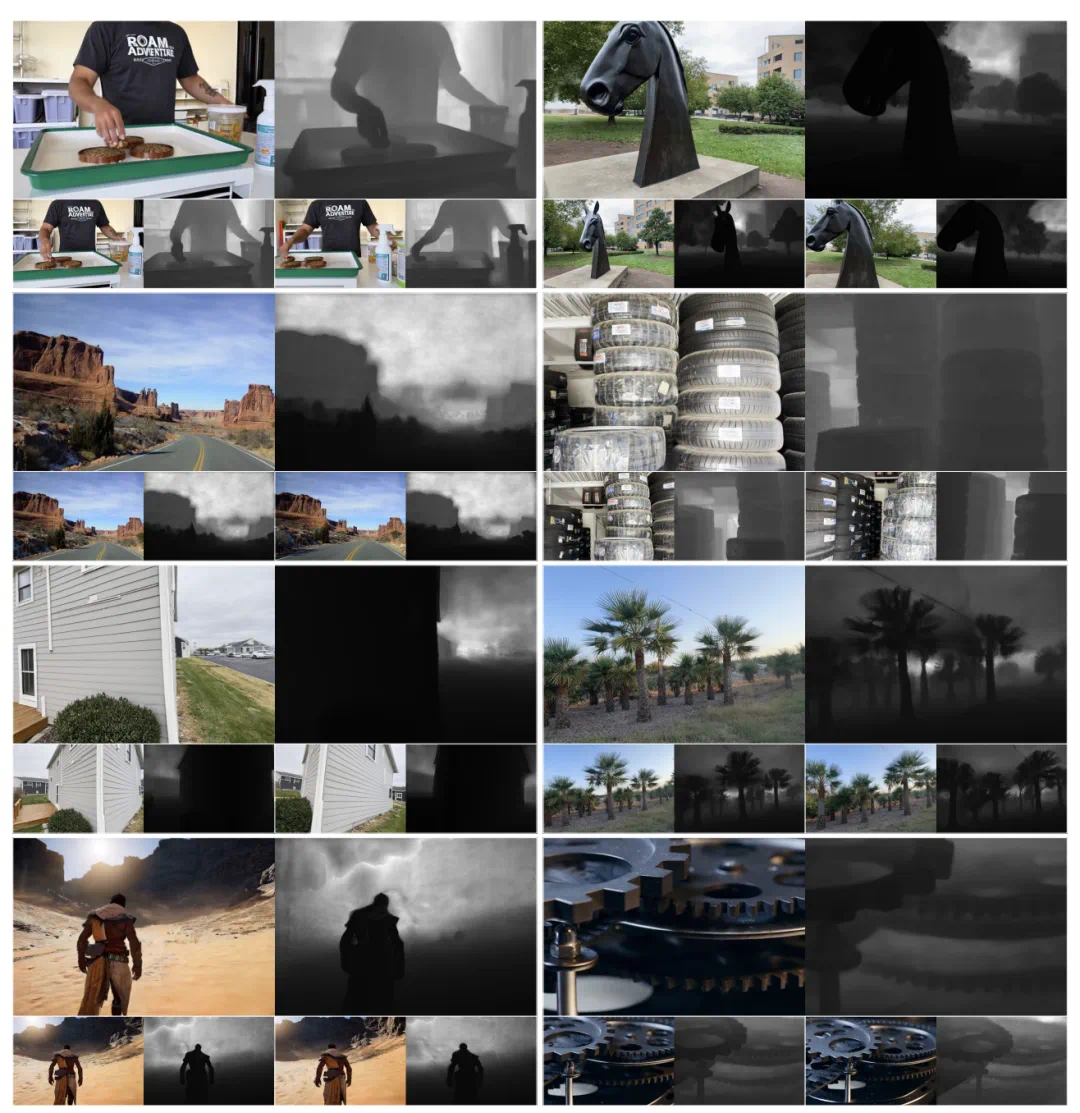
FlashWorld 还可以在只需要 RGB 监督的情况下自然学到深度信息:
对卡通风格的场景也手到擒来(文内所有图均为 3DGS 渲染结果):

快速体验
FlashWorld 还开源了基于 SparkJS 的交互式 Demo,并可以在 Huggingface Spaces 上进行免费体验。
体验地址:https://huggingface.co/spaces/imlixinyang/FlashWorld-Demo-Spark