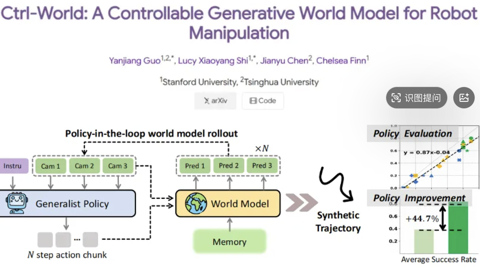
长期以来,具身智能系统主要依赖「感知 - 行动」的反应式回路,缺乏对未来的预测能力。而世界模型的引入,让智能体拥有了「想象」未来的能力。

具身智能机器人通过世界模型想象抓杯子任务
那么关键问题来了:世界模型应该如何「放进」具身系统中?是作为一个独立的模拟器?还是作为策略网络的一部分?
近日,依托北京中关村学院,来自中科大、哈工大、南开大学、清华大学、宁波东方理工大学等机构的研究团队发布了一篇全面综述,首次从架构集成(Architectural Integration) 的视角,将现有研究划分为三大范式。

论文标题: Integrating World Models into Vision Language Action and Navigation: A Comprehensive Survey
原文链接: https://doi.org/10.36227/techrxiv.176531987.77979037/v1
本文将带你一览这篇硬核综述的核心精华。
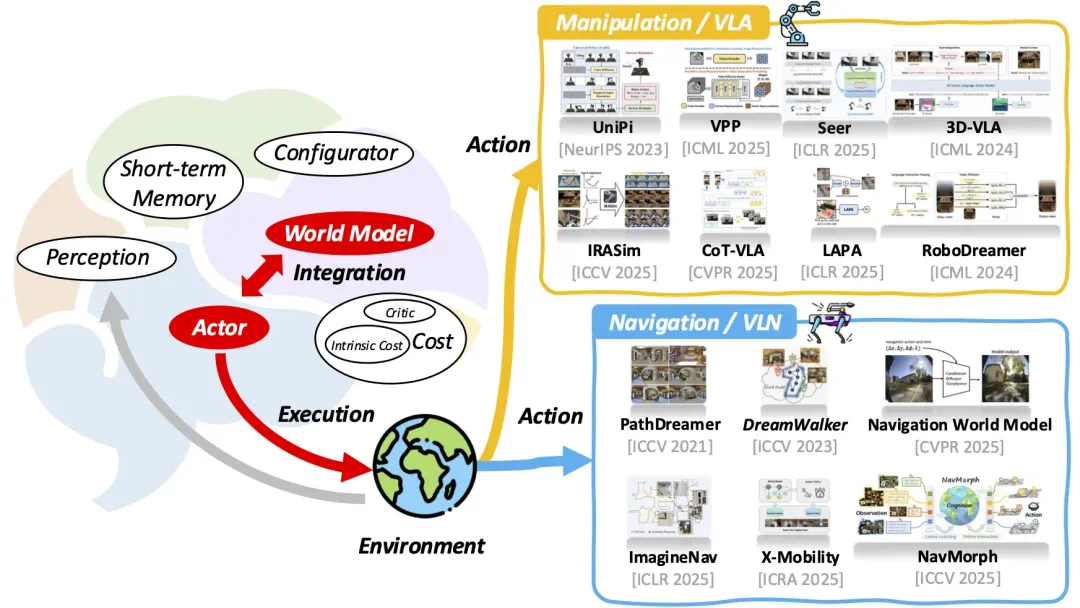
基于世界模型的具身智能体框架
为什么具身智能需要「世界模型」?
在 LLM 爆发之前,具身指令跟随系统通常将语言、感知和动作视为分离的组件。虽然端到端(End-to-End)模型不仅简化了流程,但纯反应式(Reactive)的方法面临两大瓶颈:
缺乏前瞻性: 无法预测未来状态,难以处理长程规划任务;
泛化性差: 难以适应未见过的环境或任务配置。
世界模型的核心思想源于认知科学:人类不仅是对刺激做出反应,更是在脑海中构建了一个能够预测未来的「内部模型」。引入世界模型,能为具身智能体带来样本效率提升、长程推理能力、安全性增强以及主动规划能力。

人类认知科学 → 具身智能的世界模型
核心分类:三种架构融合范式
作者认为,世界模型(World Model, WM)与策略(Policy or Policy Model, PM)之间的架构关系,其实可以看作是一条「耦合强度光谱」。简单来说,不同方法在多大程度上让「世界模型」和「策略」互相依赖、互相影响,是可以从弱到强排成一条线的。作者将这种耦合强度分成两个相互独立的维度来理解:
梯度流动(G:Gradient Flow):策略的优化目标产生的梯度,能不能直接反向传播到世界模型里,从而更新 WM 的参数?
信息依赖(I:Information Dependency):在推理的一个前向过程中,策略输出动作时,是否显式依赖于世界模型预测的状态?也就是,策略做决策的时候,是不是「要先看看世界模型怎么预测下一步世界会怎样」。
基于这两个维度,作者将相关工作分为了三个类别:耦合强度从弱到强为模块化架构(Modular),顺序架构(Sequential)以及统一架构(Unified),如下表。

深度拆解:三种范式的权衡与博弈
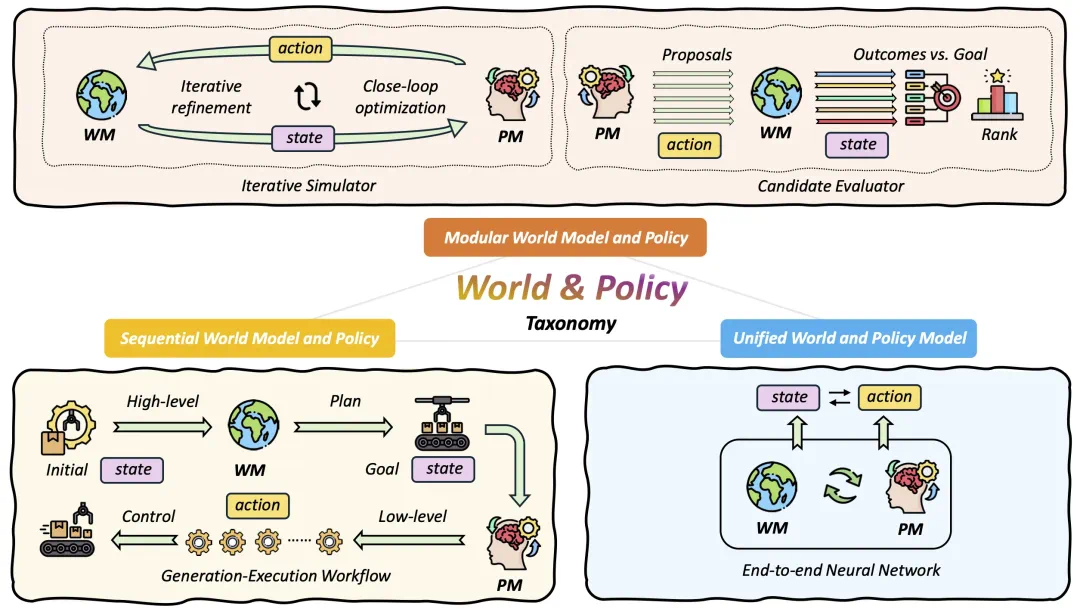
分类架构图
范式一:模块化架构 (Modular Architecture)
关键词:独立、互操作、弱耦合
模块化架构将世界模型和策略作为两个独立的单元,二者之间没有梯度流动,策略输出动作时也不依赖于未来状态。世界模型在这个架构中作为世界模拟器,关注动作与状态间的因果变化。
在这样的设计中,世界模型更像是一个「思考环境的内在模拟器」。给定当前观察(或抽象状态)以及候选动作,世界模型会根据学习到的因果规律预测下一个状态 —— 可以是像素级的图像,也可以是结构化的潜空间表示。这让智能体能够在内部「根据动作预演未来」:如果现在采取某个动作,会发生什么?这种能力让策略模型能够更好地判断哪些动作可行、哪些风险更大以及哪些方案能带来长远收益。
范式二:顺序架构 (Sequential Architecture)
关键词:分层、意图生成、中等耦合
顺序化架构先利用世界模型预测出未来状态,策略基于该未来状态预测未来动作。在该架构中,梯度传递分为两个阶段,第一阶段由世界模型预测未来状态的训练目标决定,用于优化世界模型参数;第二阶段由策略输出动作的训练目标决定,用于统一优化世界模型和策略参数。在该范式中,世界模型作为决策生成器,它的核心任务,是为智能体生成一个未来的目标状态,并把复杂的长时序任务拆分成两个更容易解决的子问题:
1. 生成一个有价值的目标(Goal Generation)
2. 根据目标执行行动(Goal-conditioned Execution)
在这种框架中,世界模型负责「想象」一个有意义的终点,例如未来的视觉观察、场景状态或抽象规划;而真正找到抵达该目标的行动序列,则由底层模块完成,比如逆动力学模型或点目标控制器。
换句话说,世界模型最重要的贡献,就是生成一个「够好」的目标,从而让后续的控制问题变得更简单。
范式三:统一架构 (Unified End-to-End Architecture)
关键词:端到端、联合优化、强耦合
统一架构则将世界模型和策略集成到一个端到端网络当中。在这一配置下:
1. 世界模型不再单独负责预测未来、建模环境;
2. 策略模型也不再单独负责决策与行动生成,两者被融合为一个统一的大网络,共同参与训练、共同被优化。
整个模型在同一个损失目标下进行端到端训练,使网络能够在同一条计算路径中:
1. 预测未来状态(anticipate future states)
2. 输出合适的动作(produce appropriate actions)
这意味着智能体不再需要显式地区分「模拟」与「决策」两个步骤,而是在统一的结构中自然涌现出这两项能力。
未来展望:通往通用具身智能之路
综述最后指出了几个极具潜力的研究方向 :
1. 世界模型的表征空间选择与耦合:视觉空间具备语义丰富度,但成本高且稳定性弱;状态空间更紧凑高效,但表达能力似乎有限。未来趋势是融合二者,通过统一潜变量实现表达能力与推理效率的平衡,为跨任务泛化奠基。
2. 世界模型的想象应该是结构化意图的生成与表达:未来的世界模型应生可解释的未来结构(目标、轨迹、成因、时空信息等表征),而非仅预测下一步状态,并且是其是否具备可约束的、物理一致的想象结构,可指导跨任务迁移并促进策略有效泛化。未来应该加入与语言和符号推理结合,若想象可在语言或符号空间中表达,则世界模型能够显式刻画任务分解、物体关系与因果依赖,而这些信息在像素预测中没有被直观的表达和理解。
3. 世界模型表征和想象对于指导具身智能的脆弱性:想象与执行解耦带来可理解性提升,但也可能产生超出具身本体能力的目标。未来研究重点是引入可达性判别、可行性过滤、物理一致性评估,以降低失效风险。另外,通过显式分离想象与控制,系统暴露中间表征,如目标假设、潜在轨迹、视觉推演等,使调试、干预和人类理解更加容易。但若模块间缺乏对齐机制,也可能削弱终端性能,因此解释性与最优性存在固有权衡。
4. 统一的世界 - 策略模型构建范式:大规模预训练模型天然具备世界建模与策略生成潜力,未来需探索如何以最小代价将其转化为统一决策系统,关键难点在于状态空间对齐、表示粒度选择、避免视觉或语言表征偏置,构建有效、高效的统一世界 - 策略模型范式。