
01、简介
小红书hi lab(Humane Intelligence Lab,人文智能实验室)团队首次开源文本大模型 dots.llm1。 dots.llm1是一个中等规模的Mixture of Experts (MoE)文本大模型,在较小激活量下取得了不错的效果。该模型充分融合了团队在数据处理和模型训练效率方面的技术积累,并借鉴了社区关于 MoE 的最新开源成果。hi lab团队开源了所有模型和必要的训练信息,包括Instruct模型、长文base模型、退火阶段前后的多个base模型及超参数等内容,希望能对大模型社区有所贡献。
模型地址:
https://huggingface.co/rednote-hilab
https://github.com/rednote-hilab/dots.llm1
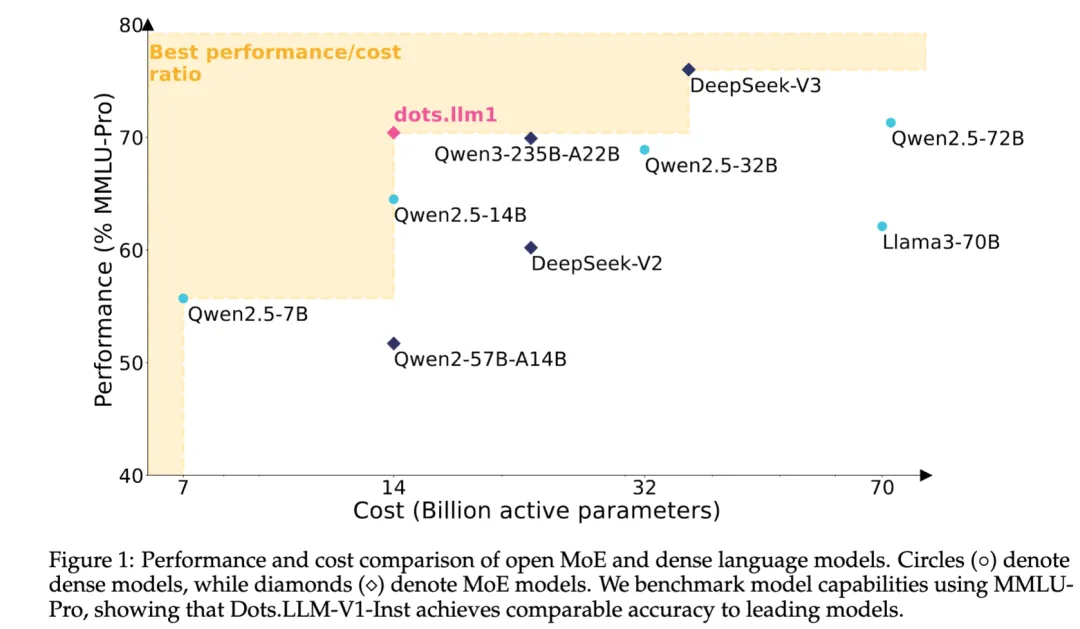
先来了解下dots.llm1的基本情况:
- 模型参数:总参数量142B、激活参数14B
- MoE配置:6in128 Expert、2个共享Expert
- 预训练数据:11.2T token高质量数据,显著优于开源数据
- 训练效率:基于Interleaved 1F1B 流水并行的AlltoAll overlap和高效Grouped GEMM的MoE训练框架
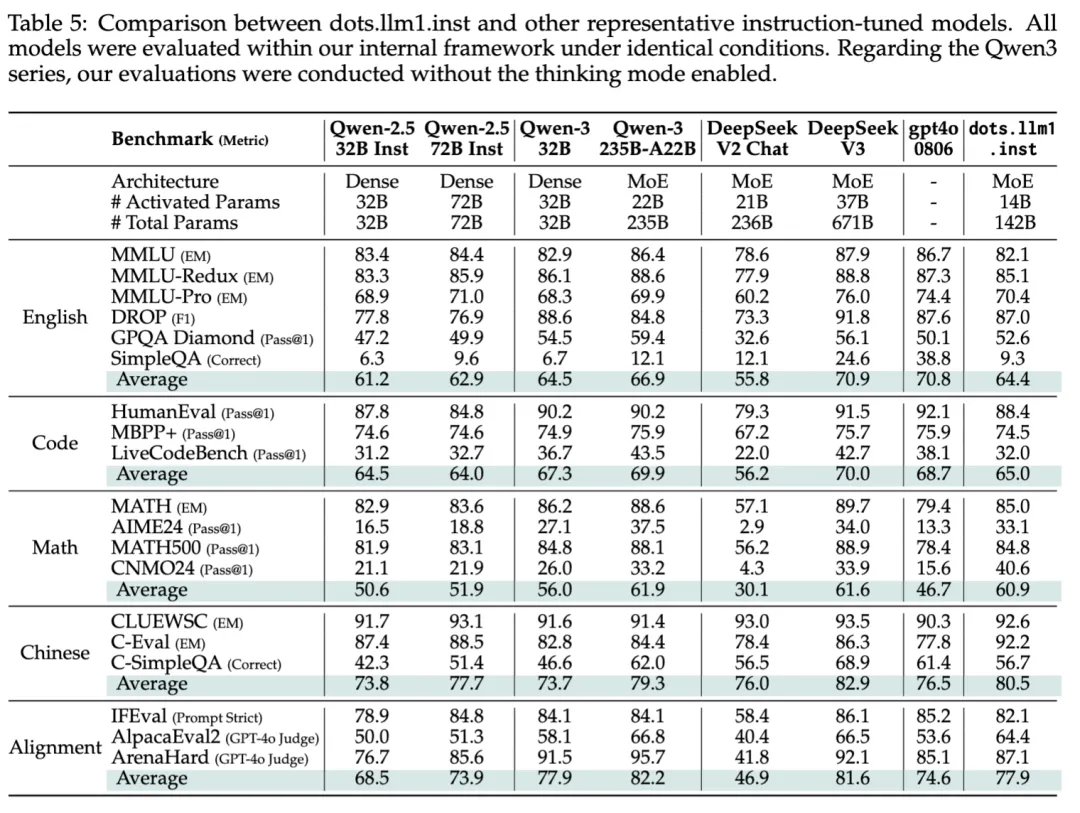
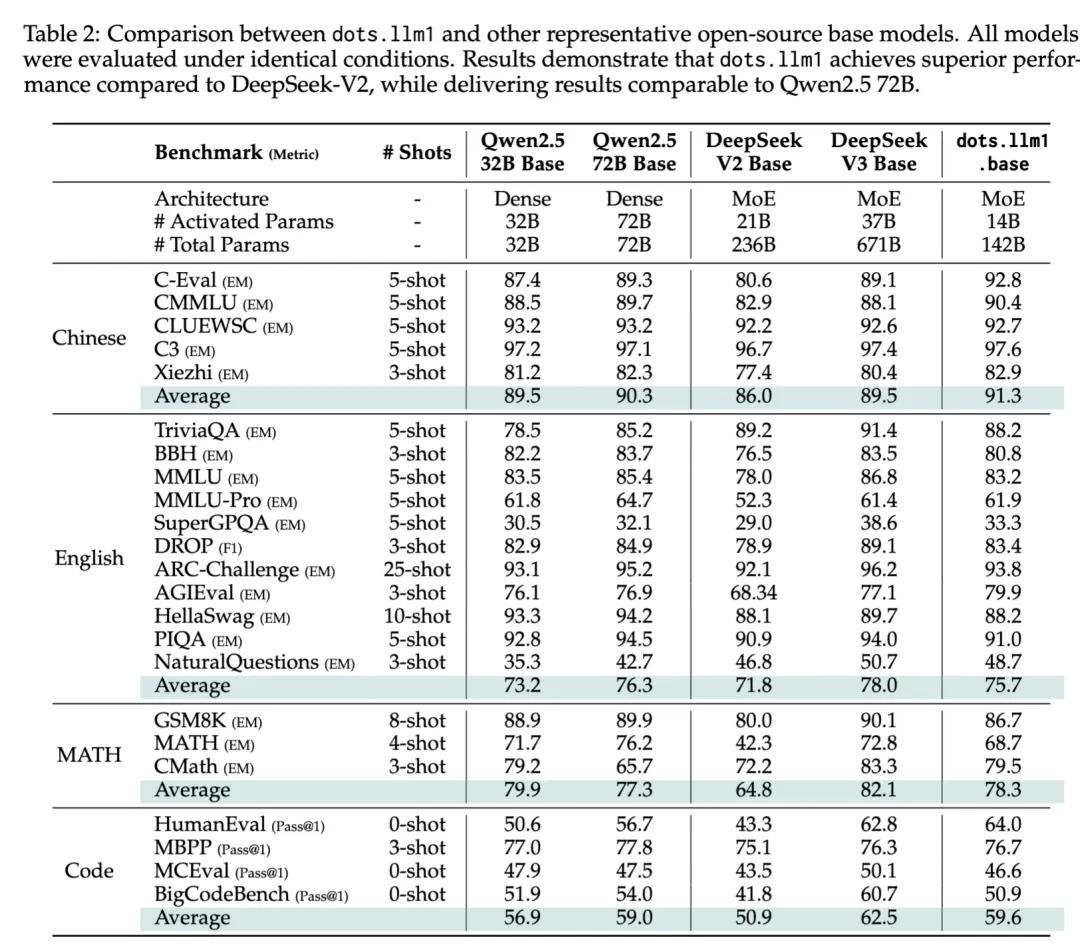
再来看下dots.llm1的模型效果,dots.llm1在预训练阶段一共使用了11.2T 高质量token,然后经过两阶段sft训练,得到dots.llm1 base模型和instruct模型,在综合指标上打平Qwen2.5 72B模型,具体指标对照情况如下:
关于dots.llm1开源,hi lab团队做到了迄今为止行业最大力度:
- 开源dots.llm1.inst模型,做到开箱即用
- 开源一系列pretrain base模型,包括预训练过程中每经过1T tokens后所保存的checkpoint——是目前开源中间checkpoint模型中,首个参数超过千亿的大模型
- 退火两阶段训练对应的模型checkpoint
- 长文base模型
- 详细介绍了lr schedule和batch size等信息,便于大家做Continue Pretraining和Supervised Fine-tuning
基于Interleaved 1F1B流水并行的AlltoAll overlap优化已经提交至NVIDIA Megatron-LM社区,会在未来一段时间正式发版。
02、dots.llm1训练过程
2.1 预训练数据
数据是文本大模型训练的核心燃料,dots.llm1所用预数据主要来自Common Crawl和自有Spider抓取得到的web数据。hi lab团队秉承宁缺毋滥的原则,精心设计了数据处理流程,在保证数据安全、准确以及丰富多样的基础上,确保预训练数据的人工评测和对照实验结果显著优于开源数据,也帮助dots.llm1在仅训练11.2T token的前提下,综合指标打平Qwen2.5 72B模型,大大减少了算力消耗。
dots.llm1的数据处理流程分为以下三部分:
- web 文档准备
对于web HTML数据,先用URL过滤方式删除黄赌毒等内容,再利用团队优化后的trafilatura软件包,提取HTML正文内容,最后进行语种过滤和MD5去重,得到web document。
- 规则处理
参考RefinedWeb和Gopher的方案进行数据清洗和过滤操作,再采用minhash方法进行document间的去重;为处理document首尾噪声文本,dots.llm1特别引入了document内的行级别去重策略,具体来说:首先提取每个document的前五行和后5行句子,然后按行计算在整个语料中的出现频次,仅保留前200次出现的行句子,删除多余的行句子,经过人工检查,这些重复次数较多的行句子大都是广告、导航栏等噪声文本。
- 模型处理
基于模型的数据处理由网页类型模型、语料质量模型、行噪声删除模型、语义去重和类别均衡模型等组成。其中语料质量模型和语义去重模型采用行业通用实现方案;网页类型模型会对web数据的站点属性进行分类,保留以文本核心的数据,删除音频、视频等非文本网页以及地图、公交查询等工具类网页文本;行噪声删除模型是在行级别去重策略基础上,通过生成式模型判别的方法,继续对行级别的长尾噪声进行document内删除处理;dots.llm1采用一个包含200个类别的web数据分类模型进行数据均衡和配比,提高知识类内容的比例,降低虚构内容(比如玄幻小说)、结构化内容(比如电商)的数据比例。
为了保障数据安全,hi lab团队过滤掉包含不安全内容、个人隐私信息(PII)及被安全分类器判定为有害的站点和数据。经过上述处理流程,hi lab团队得到一份高质量的预训练数据,并经过人工校验和实验验证,证明该数据质量显著优于开源Txt360数据。
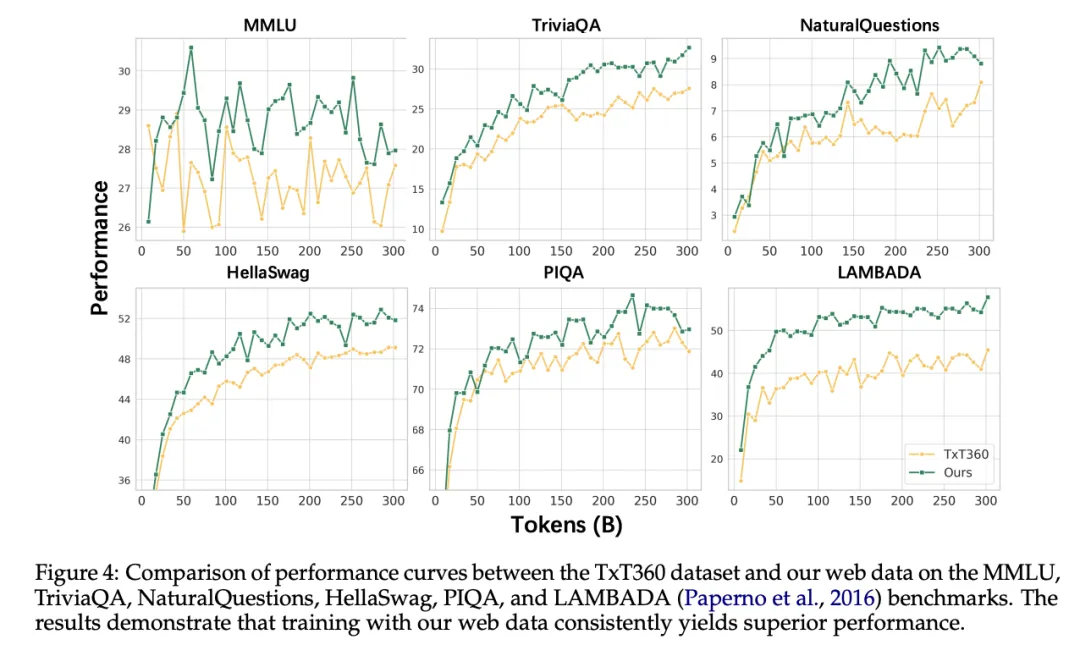
2.2 训练效率
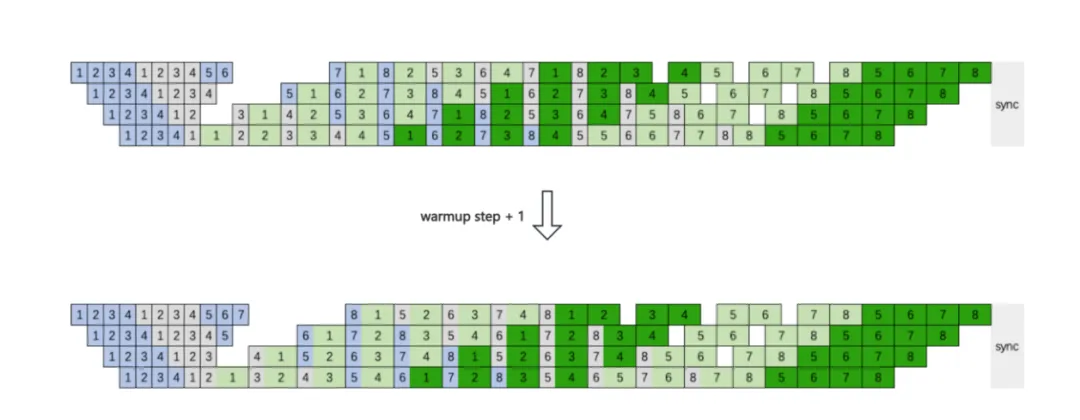
在MoE模型训练中,EP rank之间的A2A通信在端到端时间中占据了相当大比重,对训练效率影响很大,特别是对于 Fine-grained MoE Model,EP Size 会比较大,跨机通信基本无法避免。hi lab团队通过让EP A2A通信尽可能和计算overlap,用计算来掩盖通信的时间,进而提升训练效率。具体来说,团队采用interleaved 1F1B with A2A overlap 方案,通过将稳态的1F1B stage 中第一个micro batch 的fprop提前到warmup stage,即 warmup step + 1,就可以在 interleaved 1F1B实现1F1B稳态阶段不同 micro batch 前反向之间的 EP A2A 与计算的overlap。如下图所示。
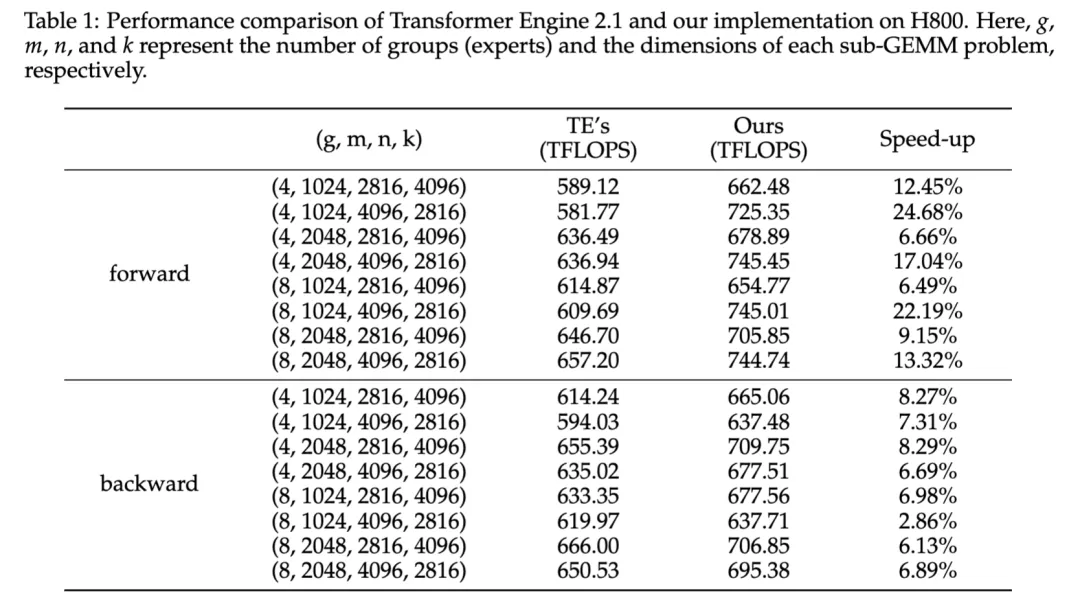
同时,hi lab团队还优化了Grouped GEMM的实现,具体来说,将 M_i(专家i的token段)对齐到一个固定的块大小。这个固定的块大小必须是异步warpgroup 级别矩阵乘加(WGMMA,即 wgmma.mma async)指令中 tile 形状修饰符 mMnNkK 的 M 的整数倍。因此,单个 threadblock 中的所有 warpgroups 都采用统一的tiling,且由该 threadblock 处理的整个 token 段(Mi)必定属于同一位专家,这使得调度过程与普通 GEMM 操作非常相似。与 NVIDIA Transformer Engine中的 Grouped GEMM API 相比,hi lab团队的实现方案展现出了显著优势。下表展示了在 H800 上前向和反向计算的性能对比,其中 token 被平均路由到各个专家。hi lab提出的方案在前向计算中平均提升了 14.00%,在反向计算中平均提升了 6.68%。
训练效率部分内容与NVIDIA中国研发团队合作完成
2.3 MoE模型设计与训练
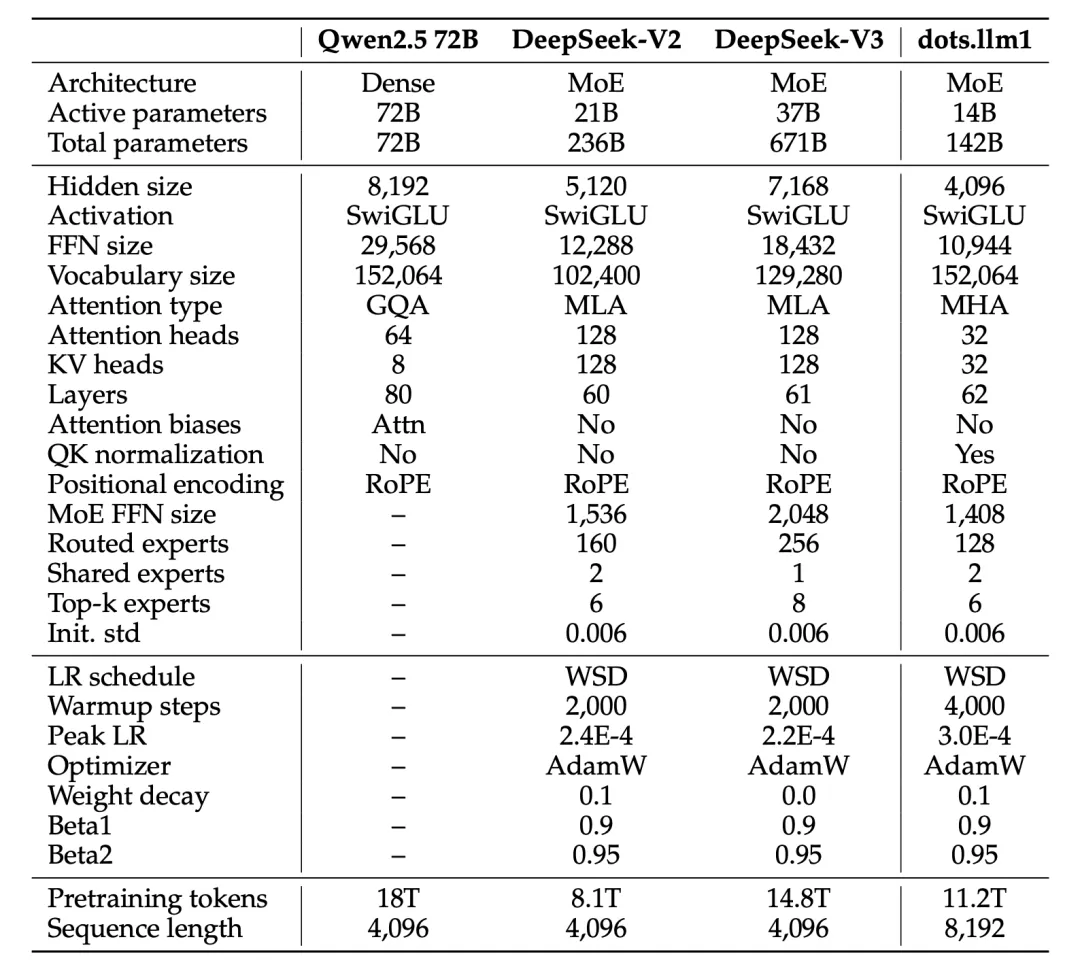
dots.llm1是基于Decoder-only Transformer的MoE模型,在架构方面主要参考DeepSeek系列来设计实现,具体参数如下:
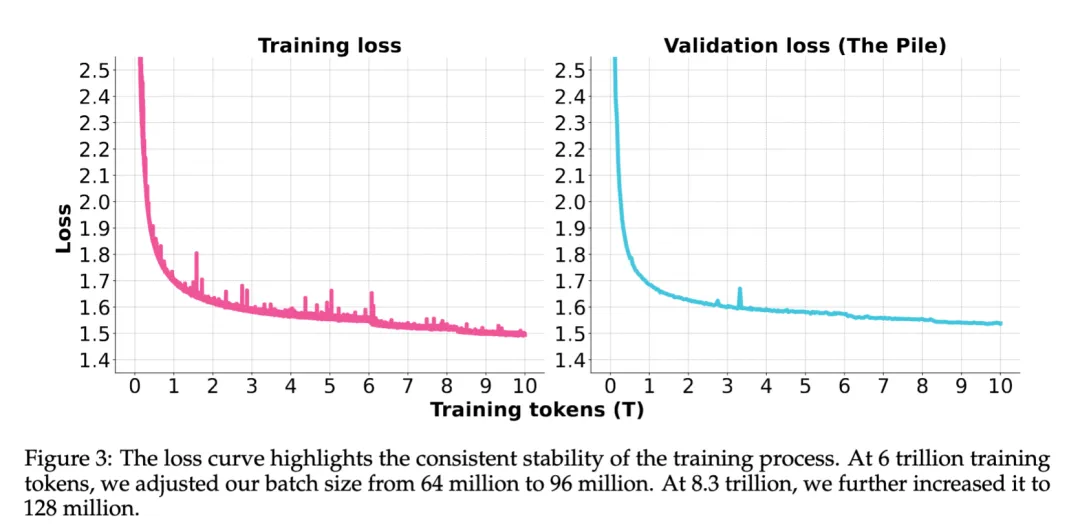
dots.llm1采用WSD学习率调度方式,在学习率稳定阶段保持3e-4训练10T token语料,在此期间先后两次增加batch size,从64M增大至128M,整个训练过程非常稳定,没有出现需要回滚的loss spike。在学习率退火阶段,分两个stage训练1.2T token语料,其中stage1期间模型学习率由3e-4退火降至3e-5,数据方面强化推理和知识类型语料,共训练1T token,stage2期间模型学习率由3e-5退火降至1e-5,数据方面提升math和code语料占比,共训练200B token。
2.4 Post-train
在高质量预训练完成后,dots.llm1通过两阶段监督微调进一步释放模型潜力。hi lab 团队精心筛选了约 40 万条涵盖多轮对话、知识问答、复杂指令遵循、数学与代码推理的高质量指令数据。针对多轮对话场景,hi lab 团队将社区开源的中英对话数据与内部标注的高质量中文指令融合,并采用教师模型优化低质量回答;为了提升知识问答能力,hi lab 团队引入了包含事实性知识与阅读理解的数据集;为了使模型更好地遵循复杂指令,hi lab 团队设计了伴随条件约束的指令数据,并过滤不遵循约束的回复;而在数学与代码领域,微调数据则经过规则验证器与测试样例验证,获取更高质量的监督信号。
微调过程分为两个阶段:首先对全量数据进行2轮基础训练,通过过采样、动态学习率调整、多轮对话拼接等技术,初步释放模型潜力;随后聚焦数学与代码等特别领域,引入拒绝采样微调(RFT),结合验证器筛选高置信度重要样本,进一步提升模型的推理性能。
最终评测显示,dots.llm1.inst在仅激活 14B 参数的情况下,在中英文通用场景、数学、代码、对齐任务上的表现亮眼,与Qwen2.5-32B-Instruct、Qwen2.5-72B-Instruct相比具备较强的竞争力;同时与Qwen3-32b相比,在中英文、数学、对齐任务上展现相似或先进性能。
03、总结
dots.llm1是小红书首次尝试开源的文本大模型,是一个可供大模型社区使用的中等参数规模下性能较优的MoE模型。期待大家能在dots.llm1基础上开展各项研究和任务训练,包括持续训练(Continue Pretraining)、退火训练、长文训练、有监督微调(Supervised Fine-tuning)等;对hi lab团队来说,dots.llm1只是一个开始,还有很大进步空间,同时希望更多优秀的大模型研究人员能加入小红书hi lab团队,与我们共同打造更多更强的全模态大模型!
04、团队简介
小红书 hi lab 团队(人文智能实验室,Humane Intelligence Lab)致力于突破人工智能的边界,通过发展人际智能、空间智能、音乐智能等多元智能形态,不断拓展人机交互的可能性,愿景是“让AI成为人类贴心和有益的伙伴”。


