
本文第一作者刘子铭为新加坡国立大学三年级博士生,本科毕业于北京大学,研究方向为机器学习系统中的并行推理与训练效率优化。通信作者为上海创智学院冯思远老师和新加坡国立大学尤洋老师。共同作者来自于上海奇绩智峰智能科技有限公司,北京基流科技有限公司等。
近年来,大型语言模型的参数规模屡创新高,随之而来的推理开销也呈指数级增长。如何降低超大模型的推理成本,成为业界关注的焦点之一。Mixture-of-Experts (MoE,混合专家) 架构通过引入大量 “专家” 子模型,让每个输入仅激活少数专家,从而在参数规模激增的同时避免推理计算量同比增长。这一稀疏激活策略使模型能扩展到数万亿参数规模,但也给推理系统带来了新的挑战:
扩展性差:
现有主流 MoE 推理框架大多要求使用大规模同步通信组来部署模型,一次性占用大量 GPU 资源,使弹性资源伸缩变得十分困难。这种粗粒度伸缩方式导致资源供给无法严格按照当前用户流量进行调整,只能按整块单元增加或减少,造成资源浪费。
容错性低:
传统 MoE 推理采用全局紧耦合架构,各 GPU 间通过 All-to-All 等大规模集体通信协同工作。在这种高度依赖统一通信组的设计下,任意一个节点故障都可能迫使整个服务集群重启,导致服务中断。也就是说,系统缺乏容错能力,一处故障即全局崩溃。
负载不均:
MoE 中的专家调用是动态稀疏的,哪个专家被激活取决于输入内容,在不同的工作负载下被激活的分布有很大区别。固定的专家映射和资源分配策略难以适应这种波动。某些专家所在 GPU 因频繁命中而过载,而其他专家节点长期闲置,造成资源利用低下。
通过观察,作者发现这些问题其实有共同的根本原因:整个系统被当作一个庞大的 “有状态整体” 去管理。事实上,专家层本质上是无状态的,它对输入执行纯函数计算,不依赖历史上下文。作者利用这一特性,将专家层的计算抽象为独立的无状态服务,与维护 KV 缓存的 Attention 前端解耦部署。尽管近期也有研究尝试解耦 Attention 层与专家层、按不同组件拆分部署,但仍未根本解决伸缩僵化、大规模容错等问题。为此,本文作者提出了一种全新的 MoE 模型推理系统 ——Expert-as-a-Service (EaaS),旨在通过架构层面的创新来提升大规模 MoE 推理的效率、扩展性和鲁棒性。

方法
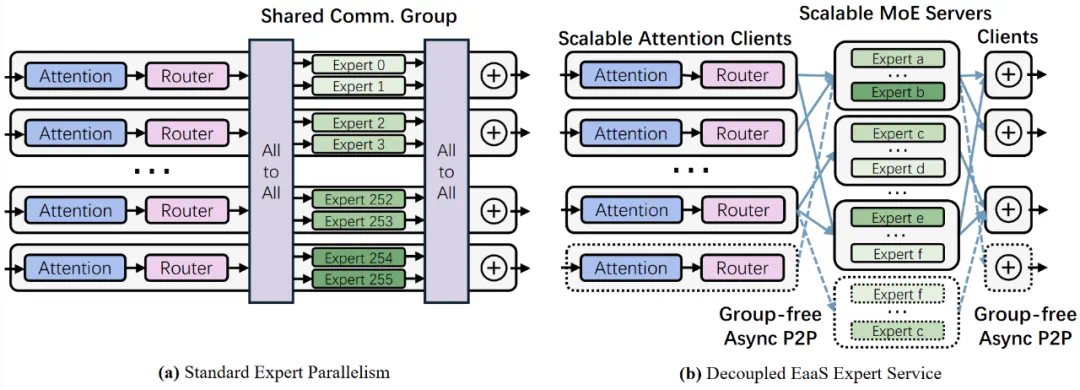
EaaS 的 “专家即服务” 的架构转变,使 MoE 推理能够像微服务一样灵活调度。在这一前提下,作者对系统进行了如下设计:
专家服务化、无状态设计:EaaS 将每个专家拆分成独立服务模块,专家不维护会话状态,仅根据请求计算输出。Attention 层(客户端)通过 gating 动态选取需要调用的专家服务。由于专家之间相互独立,整个模型不再是一个庞大的紧耦合应用,而是由许多可独立扩展的服务组成,为精细扩展奠定基础。在这种架构下,模型初始部署规模可以很小(例如 16 块 GPU 起步),可以一次增加 / 减少一块 GPU 来精确匹配负载需求。
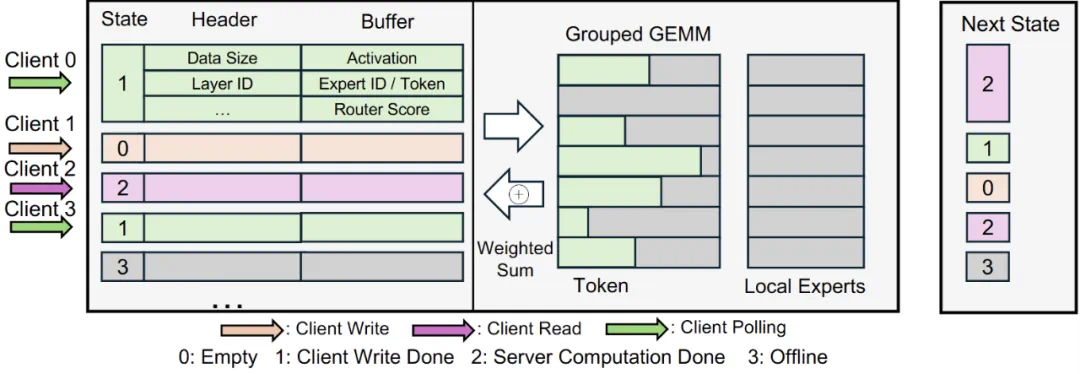
EaaS 专家服务器的动态批处理机制。
解耦 Attention 层与专家层:在传统架构中,Attention 计算和专家计算放置在同一组计算节点内,而 EaaS 将 Attention 客户端与专家服务端职责解耦开来,二者通过高效通信机制衔接。这样一方面减少了全局同步点,Attention 端可以异步等待专家结果,同时着手处理下一批次计算,从而提升流水线利用率;另一方面 Attention 和专家可以独立扩展,互不影响,突破了传统架构中必须同步扩容的限制。
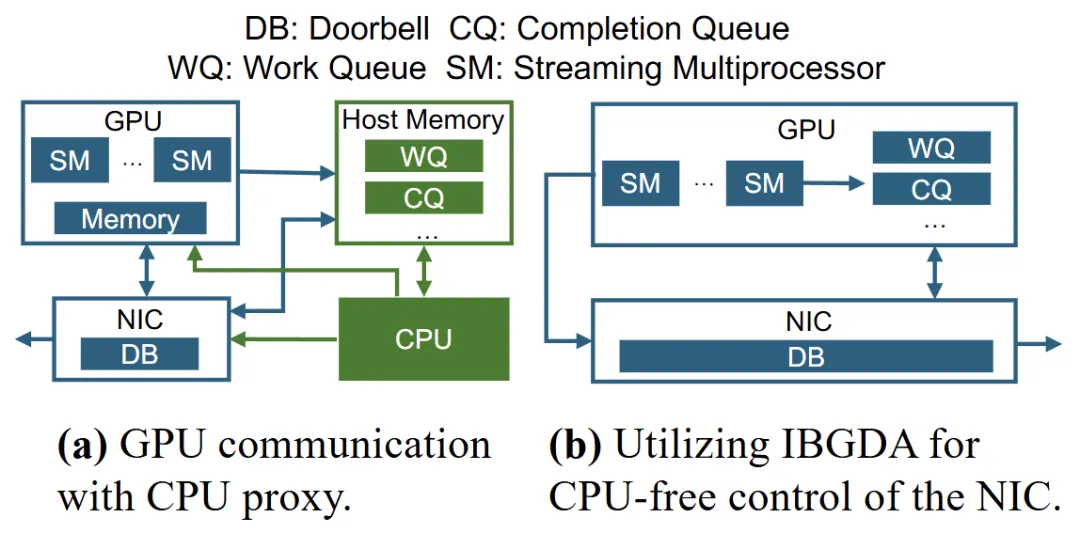
EaaS 利用 InfiniBand GPUDirect Async (IBGDA) 来实现低通信延迟,并通过完全 CUDA graph 捕获来最小化内核启动开销,从而实现无 CPU 控制的通信。
高性能异步通信 (IBGDA):为支撑上述解耦架构,EaaS 研发了定制的无通信组、非对称、异步点对点通信库。该库基于 InfiniBand GPUDirect Async (IBGDA) 技术,实现了 GPU 直连网络的通信模式,完全绕过 CPU 参与。具体来说,GPU 可以直接通过 InfiniBand 网卡收发数据,不需经由 CPU 协调。此外,该通信库支持单边 RDMA 操作和灵活的缓冲管理,不要求通信双方对称协同,突破了 NCCL 和 NVSHMEM 等通信库需整组同步的限制。借助 IBGDA 通信,EaaS 实现了真正的 CPU-free 数据传输:网络通信由 GPU 主动驱动,能够与 CUDA Graph 等机制结合,将整个端到端计算过程封装为单一调度单元,最大程度减少通信对计算流水线的干扰。
动态负载均衡:由于专家服务彼此独立,EaaS 可以方便地引入实时负载均衡策略。例如,当监测到某个专家被请求的频率过高(“热” 专家)时,系统可动态增添该专家服务的实例来分摊流量;反之对于长期 “冷门” 的专家,可减少其实例以节省资源。
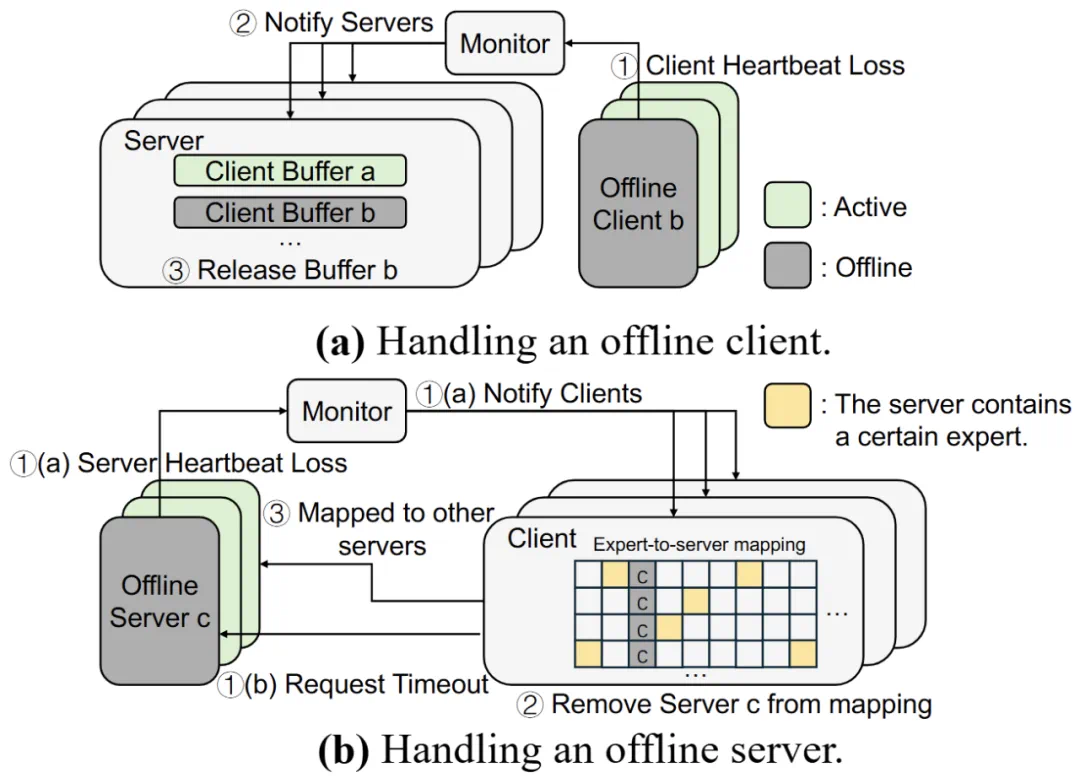
容错与故障恢复机制:EaaS 通过客户端 - 服务端的松耦合通信取代了集体通信,天然具备更强的容错性。系统设置了一个中央监控组件,实时追踪各实例健康状态。当某个专家服务发生故障停止响应时,通知相关的 Attention 客户端自动切换到该专家的其他可用实例继续服务,无需重建全局通信组。同样地,如果某个 Attention 客户端节点故障,其他客户端不会直接中断,新客户端加入也不会扰乱正在运行的专家服务。
实验
论文通过一系列大规模实验,利用端到端的 benchmark 对比了 EaaS 与当前主流 MoE 推理方案(如 SGLang + DeepEP、vLLM + DeepEP 以及 SGLang + TP 等组合)的性能,在扩展性和容错等方面展现出 EaaS 的优势。
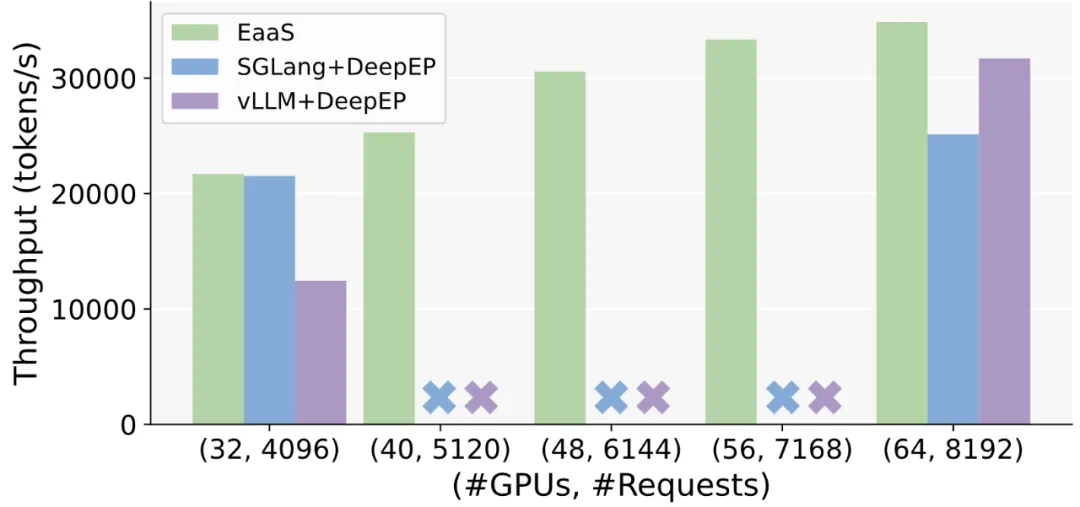
扩展能力:在随请求密度进行扩展(也即弱扩展)的实验中,随着 GPU 节点数从 32 增加到 64,EaaS 的总吞吐量几乎按比例提升。同时,EaaS 打破了传统架构对 GPU 数量整除比的要求。使用传统专家并行的系统只能在 GPU 数量是既定专家总数因子的情况下扩容,而 EaaS 由于专家服务松耦合,支持任意数量 GPU 的部署组合,可以细粒度地按需增减算力。这意味着云服务商可以灵活地为 MoE 模型调配资源,例如在负载下降时将推理集群从 64 GPU 缩减到 40 GPU 仍保持同等吞吐。实验显示,与静态架构相比,EaaS 能够实现同等性能下最高约 37.5% 的 GPU 资源节省。
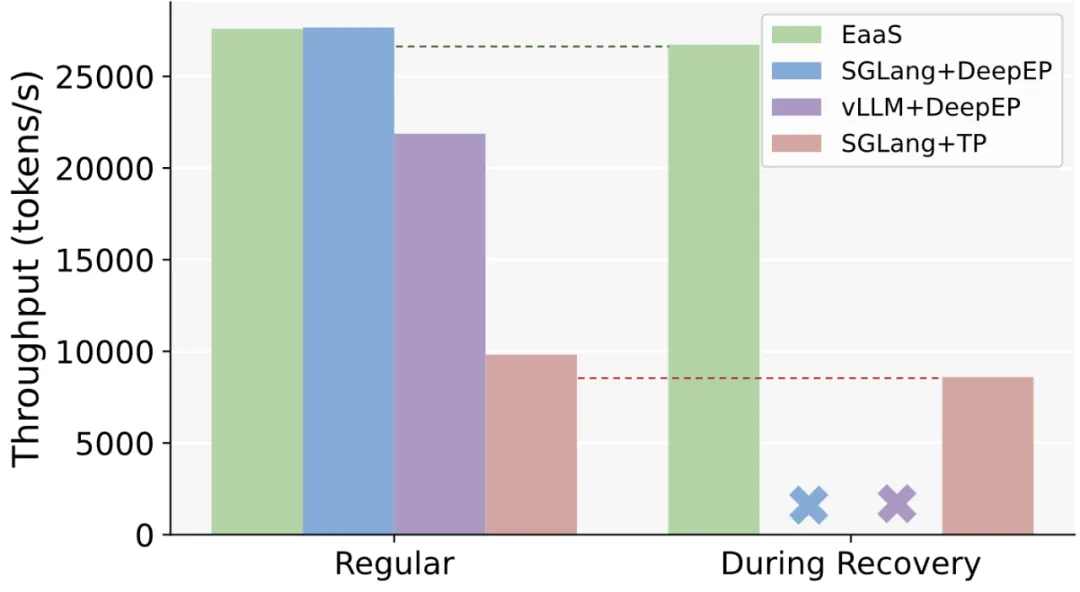
容错与鲁棒性:在模拟故障场景中,EaaS 展现出卓越的服务连续性。当实验中随机失效 GPU 节点时,EaaS 几乎不中断地完成了请求处理,吞吐量仅略微下降不到 2%。相比之下,采用 DeepEP 等传统方案的系统由于所有解码 GPU 绑定在单一通信组内,任一节点故障都会使整个组停止服务,无法在故障期间继续推理。EaaS 中有故障的专家请求被即时路由到备用副本处理,客户端自身故障也被其他实例接管,整个服务保持了高可用性。
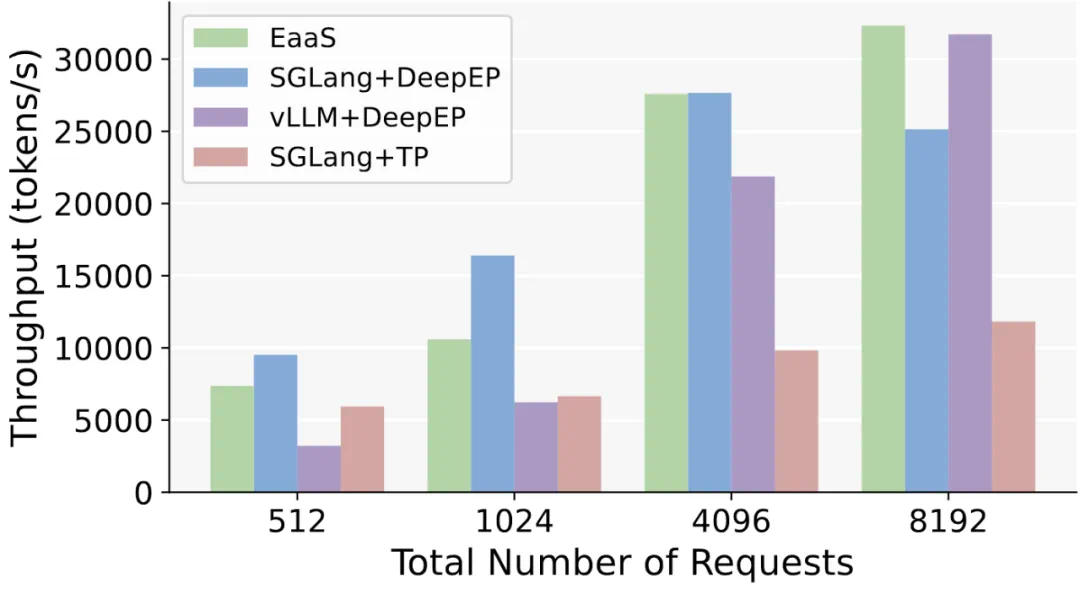
高吞吐与低延迟兼顾:在端到端推理吞吐量上,EaaS 与现有最优系统表现相当,能够达到媲美 SOTA 的生成速度。同时,EaaS 在响应延迟上保持稳定,得益于高效通信与动态资源调配,能将每个 token 的平均生成延迟维持在较低水平。整体评估显示,EaaS 在吞吐 - 延迟权衡上达到优秀平衡,在保证用户响应及时性的同时提供了强劲的处理能力。
1 对 3 往返通信平均延迟
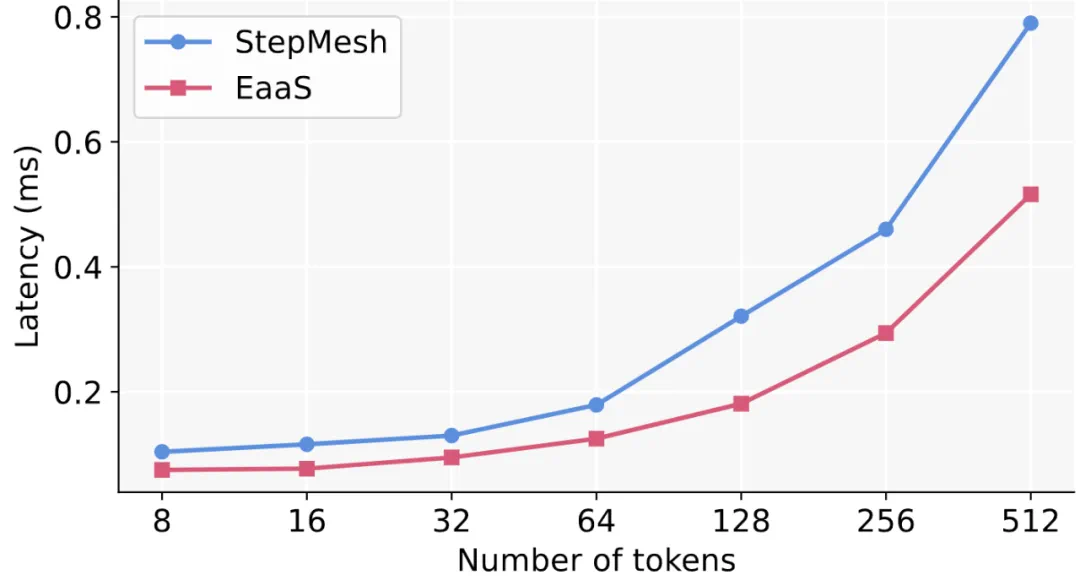
2 对 2 往返通信平均延迟
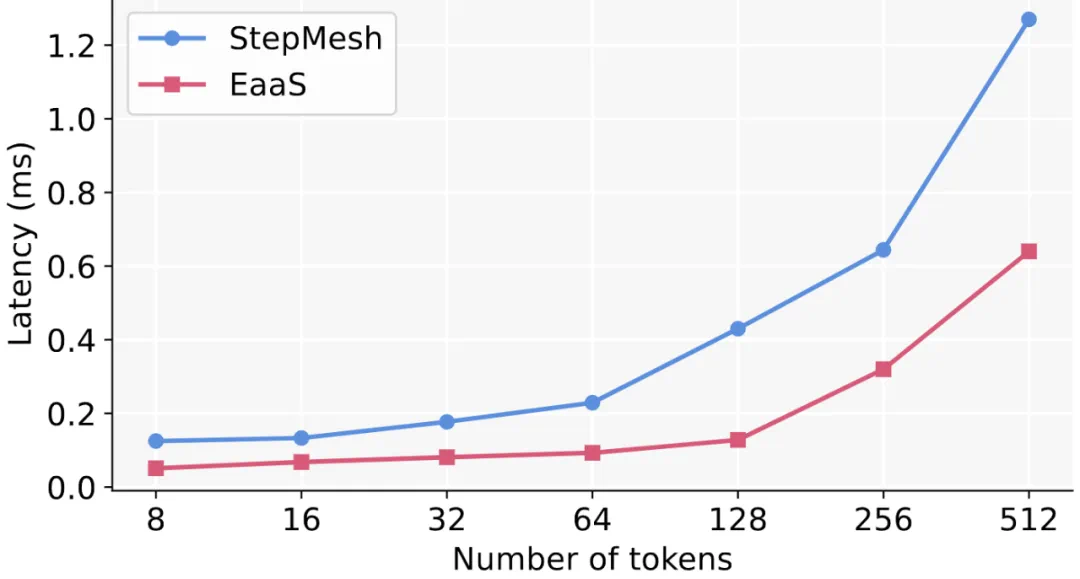
除此以外,作者也将 EaaS 的通信库与当前开源的 Step3 中 StepMesh 使用的通信库进行了 torch 侧调用从端到端的延迟比较,并发现在对称与非对称的场景下,EaaS 的通信库通过 IBGDA 本身的高效通信模式与仅 CPU-free 的结构支持的 CUDA graph 带来的 kernel launch 开销的 overlap,最多将延迟降低了 49.6%。
总结
面向未来,EaaS 展现出在云端大模型推理和模型即服务(MaaS)等场景中的巨大潜力。其细粒度的资源调配能力意味着云服务提供商可以根据实时负载弹性地调整 MoE 模型的算力分配,从而以更低的成本提供稳定可靠的模型推理服务。这种按需伸缩、平滑容错的设计非常契合云计算环境下的多租户和持续交付需求。另一方面,EaaS 的服务化架构具有良好的可运营和可演化特性:模块化的专家服务便于独立升级和维护,通信调度组件也可以逐步优化迭代,从而使整套系统能够随着模型规模和应用需求的变化不断演进。


