大语言模型(LLM)虽已展现出卓越的代码生成潜力,却依然面临着一道艰巨的挑战:如何在有限的计算资源约束下,同步提升对多种编程语言的理解与生成能力,同时不损害其在主流语言上的性能?
为此,中国移动九天团队创新性地提出了 Hybrid MoE 架构 —— MultiPL-MoE,该方案的核心在于耦合两个层次的专家选择机制进行优化:在 Token 层级,采用配备共享专家及新颖门控权重归一化方法的稀疏 MoE,以实现与段落层级专家的高效协同;在 Segment 层级,则创新性地引入滑动窗口划分与专家选择路由策略,使模型能够精准捕捉不同编程语言的语法结构与深层上下文模式。目前,该项研究已被 EMNLP 2025 接收。

论文标题:MultiPL-MoE: Multi-Programming-Lingual Extension of Large Language Models through Hybrid Mixture-of-Experts
论文链接:https://arxiv.org/abs/2508.19268
代码链接:https://github.com/Eduwad/MultiPL-MoE
背景
现有的通用大模型在代码生成方面已经展示出卓越的能力,然而大量研究表明这些大模型在高资源编程语言(如:Python)与低资源编程语言上(如:Rust)上存在显著的性能差异,后者无论是在线资源还是训练数据集均相对匮乏。对多语言代码生成能力日益增长的需求,促使人们致力于将广泛的编程语言知识注入 LLM。然而,现有的研究主要存在以下两种问题:
1. 使用多种编程语言的数据对基座模型进行继续训练,但存在计算开销极为庞大的问题;
2. 通过特定高质量低资源数据对基座模型进行微调以提升特定编程语言性能,但会引发基座模型原有代码能力的严重灾难性遗忘问题。
因此,我们创新性地提出了一种 Hybrid MoE 结构,即 token-level MoE 和 segment-level MoE 相结合的 MoE 架构。Token-level MoE 采用典型的 sparse upcycling MoE 结构,Segment-level MoE 则利用滑动窗口获得多个分段并搭配采用专家选择 top-k 个分段的专家选择路由的策略。实验结果证明了 MultiPL-MoE 的有效性。
方法
1. MoE 定义
MoE 通过将原 Transformer 结构中的单一 FFN 层扩展成 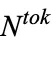 个 FFN 层来实现模型的扩容,使用结构上与原始 FFN 层等效的
个 FFN 层来实现模型的扩容,使用结构上与原始 FFN 层等效的 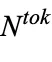 专家网络。路由器将每个输入 token 引导到
专家网络。路由器将每个输入 token 引导到 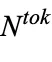 专家网络中的 K 个专家,
专家网络中的 K 个专家,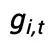 是给定第 t 个 token 的第 i 个专家的门控分数。对于第 l 层,第 t 个 token 的输出隐藏状态为
是给定第 t 个 token 的第 i 个专家的门控分数。对于第 l 层,第 t 个 token 的输出隐藏状态为 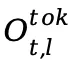 的计算过程如下:
的计算过程如下:
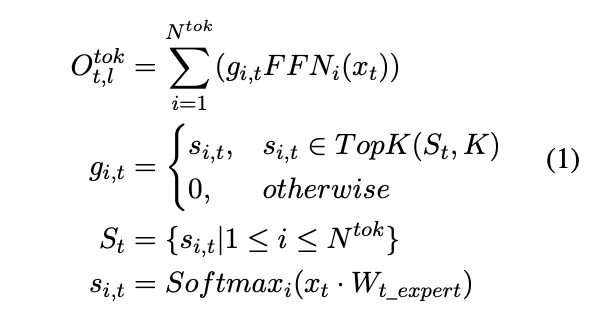
2. MultiPL-MoE
MultiPL-MoE 的提出以优化 token-level 和 segment-level 的专家选择。Token-level MoE 是一种传统的 token 选择路由,结合了共享专家和一种新的路由权重归一化方法,以解决后期与 segment-level MoE 融合时的规模不匹配问题。对于 segment-level MoE,我们采用专家选择路由机制,将输入作为上下文连贯的分段,使专家能够捕捉语法结构和一些篇章级的特征。
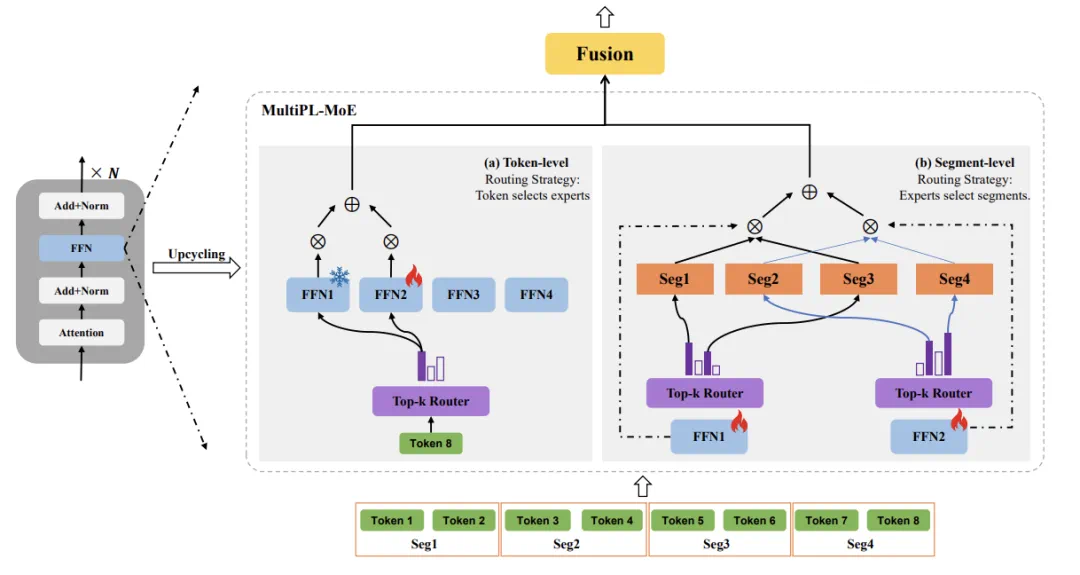
图 1 MutilPL-MoE 的整体架构
2.1 Token-level MoE
为了融合 token-level MoE 与 segment-level MoE 的输出,在该层级对选中的 top-K 个专家的门控分数施加限制。具体来说,使用路由器网络计算当前 token t 的共享专家的亲和度得分,记为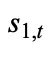 ,并从剩余得分中选择最高的 K-1 个亲和度得分,将 K 个亲和力得分之和用作缩放因子 Norm 对其进行归一化,确保
,并从剩余得分中选择最高的 K-1 个亲和度得分,将 K 个亲和力得分之和用作缩放因子 Norm 对其进行归一化,确保
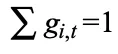 。
。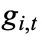 的值按照以下方式进行更新:
的值按照以下方式进行更新:
2.2 Segment-level MoE
Segment-level MoE 采用专家选择路由策略,为每个专家独立选择前 K 个分段。给定输入样本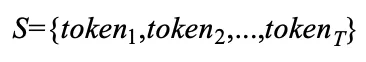 。首先根据上下文窗口 a 将 S 划分为 P 段,表示为
。首先根据上下文窗口 a 将 S 划分为 P 段,表示为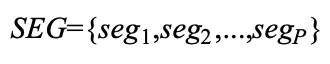 。专家容量 r 表示每个专家可以选择的分段数目,定义如下:
。专家容量 r 表示每个专家可以选择的分段数目,定义如下:
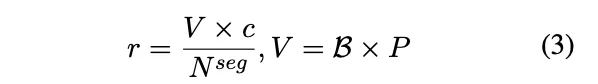
采用三个矩阵 I、D 和 U 来生成专家到分段的分配。索引矩阵 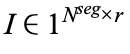 将分段映射到专家,I [i,j] 表示第 i 个专家选择的第 j 个分段,权重矩阵
将分段映射到专家,I [i,j] 表示第 i 个专家选择的第 j 个分段,权重矩阵 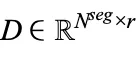 为所选分段分配专家权重,
为所选分段分配专家权重,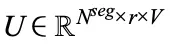 是 I 的 ont-hot 版本,用于聚合每个专家的分段。为了计算亲和力得分,通过对第 v 个分段的 token 表示进行平均,推导出第 v 个分段的表示
是 I 的 ont-hot 版本,用于聚合每个专家的分段。为了计算亲和力得分,通过对第 v 个分段的 token 表示进行平均,推导出第 v 个分段的表示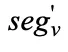 。
。 表示 batch 内所有 V 个分段的表示,路由器和三个矩阵的计算过程定义如下:
表示 batch 内所有 V 个分段的表示,路由器和三个矩阵的计算过程定义如下:
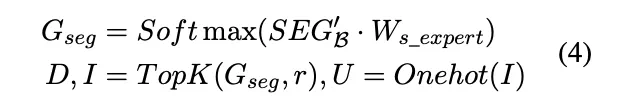
通过使用矩阵 U 和一批输入样本 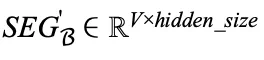 的分段表示来获得第 i 个专家的输入,表示为
的分段表示来获得第 i 个专家的输入,表示为 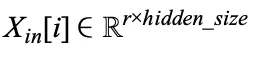 ,使用专家的 FFN 变换生成第 i 个专家的输出
,使用专家的 FFN 变换生成第 i 个专家的输出 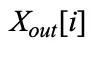 。给定
。给定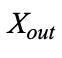 和矩阵 U、D,第 l 层 segment-level 的输出
和矩阵 U、D,第 l 层 segment-level 的输出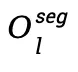 计算如下:
计算如下:
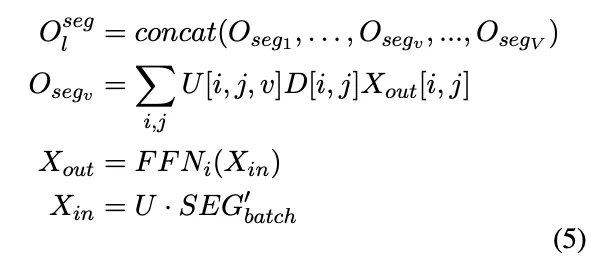
最后,融合 token-level MoE 和 segment-level MoE 的第 l 层输出为:
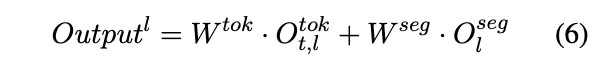
2.3 损失函数
通过将 next token prediction loss 与 load balance loss 相结合来训练混合 MoE。
(1) next token prediction loss
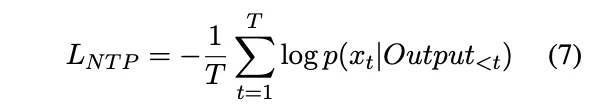
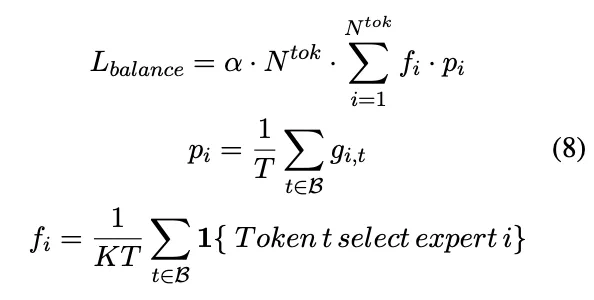
(2) load balance loss
最终的优化目标为:
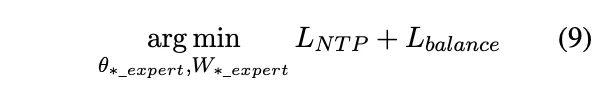
实验结果
实验结果表明,MultiPL-MoE 在跨语言泛化方面取得了显著进步。MultiPL-MoE 在 HumanEval 和 MBPP 的两个基准测试中均实现了一致的性能,即显著增强了模型在低资源编程语言上的性能,同时有效缓解了高资源编程语言中的灾难性遗忘。同时,我们也注意到,除基础模型 Qwen1.5 外,基线模型、MultiPL-MoE 的 MBPP Python 语言上都表现出持续较低的性能,远远低于其他语言。
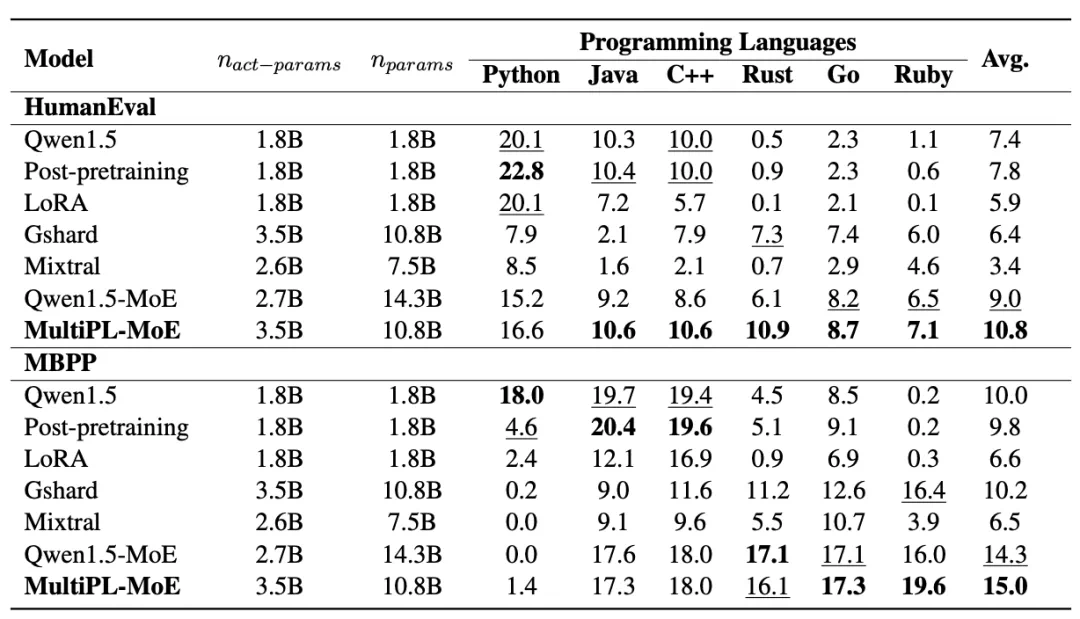
图 2 不同 Baseline 及 MultiPL-MoE 在 6 种编程语言上的实验结果。其中,Python,Java,C++ 代表高资源语言,Rust,Go,Ruby 代表低资源语言。
结语
本文提出了一种混合式多语言学习模型 (MoE)——MultiPL-MoE,它同时包含 token-level MoE 和 segment-level MoE。MultiPL-MoE 引入共享专家来捕捉 token 之间的知识共性,并在句段 (segment) 之间获取句段间的语义和逻辑信息。在两个不同的基准测试集上进行的大量实证研究证明了 MultiPL-MoE 是一种在预训练后阶段扩展低源码编程语言的有效方法。