
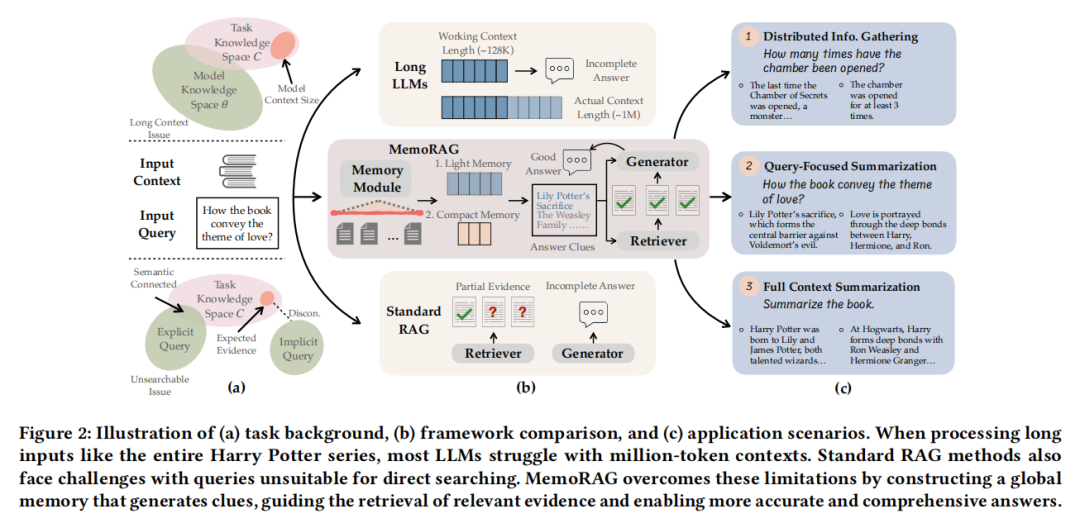
在大模型处理长文本的场景中,你是否曾遇到过这些难题?直接用长上下文LLM成本高昂,128K tokens的推理不仅耗时长,还会占用大量GPU内存;传统RAG面对模糊查询(比如“总结这本书的核心人物关系”)时束手无策,更无法处理非结构化的超长文档(如100页的法律合同、多年度财务报告)。
今天要介绍的MemoRAG,或许能解决这些痛点。这是由北京智源人工智能研究院、中国人民大学高瓴人工智能学院等团队联合研发的新型RAG框架,发表于2025年WWW会议,核心思路是模仿人类“先建立全局记忆,再定位细节”的认知过程,让RAG技术首次突破“仅能处理简单QA”的局限,能应对摘要、跨文档分析等复杂任务。
论文地址:https://arxiv.org/pdf/2409.05591
项目地址:https://github.com/qhjqhj00/MemoRAG
01、为什么需要MemoRAG?长上下文处理的三大痛点
在MemoRAG出现前,长文本处理主要有两种思路,但都存在明显短板:
长上下文LLM:能力有限,成本极高
近年来LLM的上下文窗口不断扩大(如Mistral-32K、Phi-128K),但直接处理超长文本(如1M tokens)仍不现实——不仅推理时间呈指数级增长,GPU内存占用也会飙升(处理128K tokens需数十GiB内存),而且当答案位于文本中间时,模型还可能“失忆”(即“Lost in the middle”问题)。
传统RAG:依赖明确查询与结构化数据
传统RAG的核心逻辑是“用查询检索相关片段”,但这需要两个前提:
- 查询必须明确:比如“哈利波特的生日是哪天”这类问题能直接检索,但“分析书中爱情主题的表达方式”这类模糊需求,传统RAG无法生成有效检索query;
- 数据必须结构化:像Wikipedia这样分段落、有标题的文本能轻松切割索引,但面对无格式的超长报告、小说原文,分割后的文本块会丢失语义关联,导致检索混乱。
人类认知的启发:先全局记忆,再细节定位
人类处理长文档时,从不会逐字逐句记住所有内容,而是先快速浏览形成“全局记忆”(比如知道一本书的核心人物、主线剧情),再根据任务需求(如“分析人物关系”)从记忆中提取线索,最后翻书定位具体细节。MemoRAG正是将这一过程模块化,构建了“记忆-线索-检索-生成”的闭环。
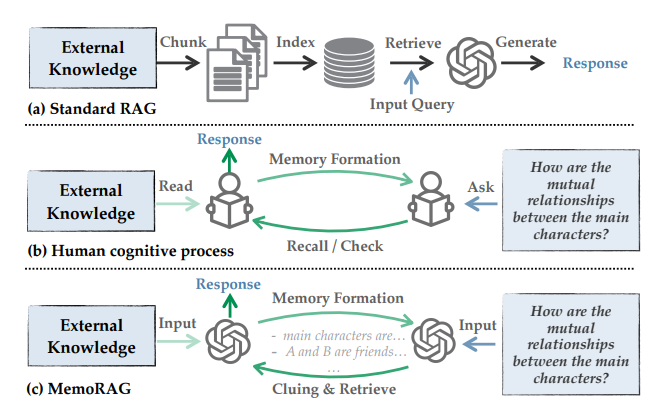
02、MemoRAG核心设计1:双系统架构
MemoRAG的突破点在于用“全局记忆”打通“模糊需求”与“精准检索”的鸿沟,采用了一种Dual-System架构。整体架构分为“轻量级长程系统”(负责记忆)和“重量级表达系统”(负责生成)两部分,流程可概括为“先记全局,再找细节,最后生成”。
核心流程:从记忆到答案的四步走
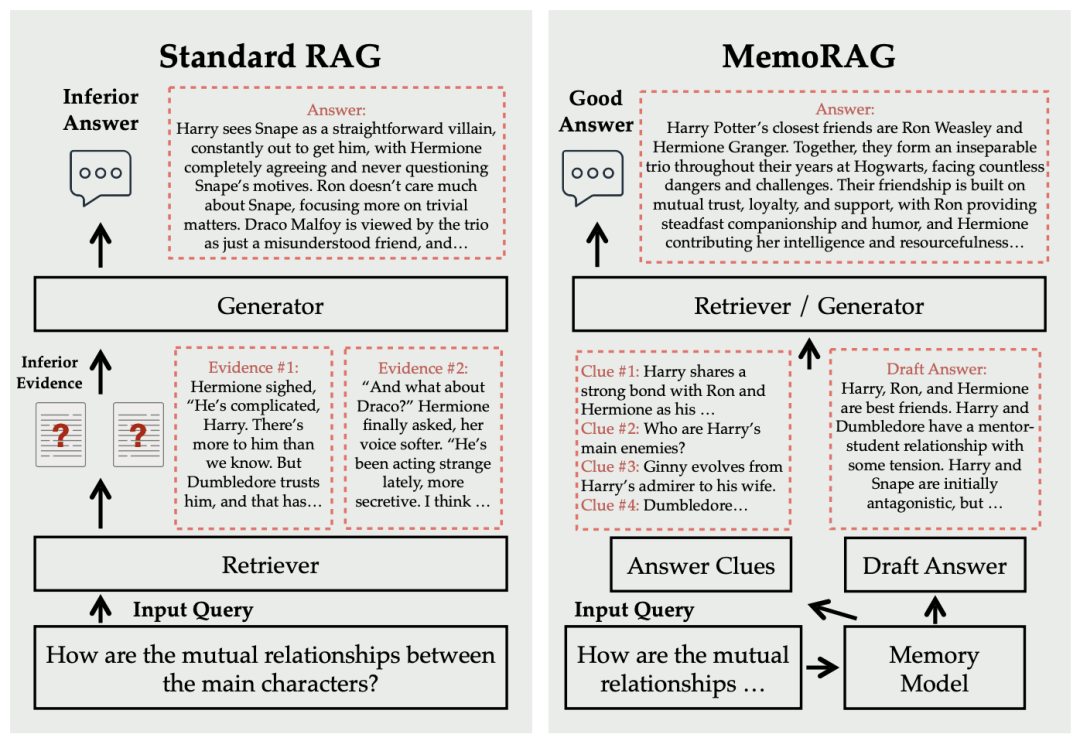
以“分析《哈利波特》中主要人物关系”为例,MemoRAG的工作流程如下:
- Step 1:建立全局记忆:用轻量级模型(如压缩后的Mistral-7B)处理完整文本,生成“全局记忆”——这不是逐字存储,而是将文本压缩为KV缓存(键值对)形式,保留核心语义(如“哈利、罗恩、赫敏是主角,三人是朋友”);
- Step 2:生成线索:收到用户查询后,记忆模块基于全局记忆生成“草稿线索”,比如“哈利与罗恩是室友,赫敏常帮两人解决危机,三人曾共同对抗伏地魔”——这些线索虽不完整,但明确了检索方向;
- Step 3:线索引导检索:用线索作为检索query,在原始文本中定位相关片段(如“赫敏在密室中帮助哈利破解谜题”“罗恩为保护哈利牺牲自己”);
- Step 4:生成最终答案:重量级模型(如Phi-3-mini-128K)结合查询、线索和检索到的细节,生成完整答案(如“哈利与罗恩、赫敏组成不可分割的三人组,友谊建立在信任与支持之上……”)。
这个过程完美复刻了人类认知:记忆模块对应“大脑对文档的整体印象”,线索对应“大脑提取的关键信息”,检索对应“翻书找细节”,生成对应“组织语言回答”。
03、MemoRAG核心设计2:全局记忆模块
全局记忆模块是MemoRAG突破传统RAG局限、实现超长上下文高效处理的核心,其设计围绕“长度可扩展性(高效处理超长文本)、记忆持久性(留存关键语义)、指导有效性(生成精准检索线索)”三大目标展开,从模型架构、训练流程到技术优化形成完整闭环。
核心定位:全局记忆模块的角色与价值
在MemoRAG的双系统架构中,全局记忆模块承担“长上下文语义浓缩器”与“检索线索生成器”双重角色,是连接“超长非结构化文本”与“精准检索-生成”的关键桥梁:
- 对比传统RAG:传统RAG无全局认知,直接依赖用户查询检索文本块,面对模糊需求(如“总结合同核心风险点”)或非结构化文本(如100页小说)时,易因“查询-文本语义鸿沟”导致检索失效;而全局记忆模块先通过轻量级系统处理完整文本,形成覆盖全文的语义记忆,再基于记忆生成线索,从根源上解决“无明确查询”“文本无结构”的痛点。
- 对比长上下文LLM:长上下文LLM需维护与文本长度成正比的KV缓存(如1M tokens文本需GB级缓存),推理成本极高;而全局记忆模块通过压缩技术将KV缓存体积大幅缩减,在保证语义完整性的同时,让128K窗口的LLM能处理8M tokens文本,兼顾效率与能力。
MemoRAG通过“KV压缩”和“三段式训练”实现了这三点:
KV压缩:用“记忆token”压缩超长文本
轻量级记忆是全局记忆的“基准版本”,核心思路是复用现有长上下文优化技术,快速实现“长文本处理”能力,但存在明显局限:
- 上下文长度受限:仍依赖LLM原生上下文窗口(如Mistral-7B-32K),即使通过SelfExtend扩展,也难以突破“原生窗口×2”的限制,无法处理8M tokens级超长篇文本;
- 语义完整性受损:为压缩内存,MInference等技术采用稀疏注意力,仅关注文本局部关联,导致全局语义断裂(如小说中“跨章节人物关系”无法被捕捉);
- 内存占用仍高:虽减少模型参数,但需维护完整长度的KV缓存(如处理128K tokens文本仍需数十GiB GPU内存),未从根本上解决“长文本-高内存”矛盾。
MemoRAG的解决方案是插入“记忆token”:
- 核心创新:记忆token(Memory Tokens)的引入 为打破 “KV 缓存长度必须等于文本长度” 的固定绑定,论文提出在文本中插入专门承载全局语义的记忆 token,将其作为压缩后的 “语义载体”。具体来说,先看记忆 token 的插入规则:假设底层 LLM 的原生上下文窗口长度为 128K tokens(这是很多主流 LLM 的常见配置),那么每处理完 128K tokens 的原始文本后,就会插入少量记忆 token—— 比如 2K tokens,形成 “原始文本窗口 + 记忆 token” 不断循环的结构。这些记忆 token 不直接对应原始文本里的具体句子或内容,而是通过专门设计的注意力机制,“吸收” 它所在文本窗口内的核心语义,比如一个窗口里的人物关系、事件因果逻辑、关键概念定义等,相当于给这个窗口的文本做了一份 “语义摘要”。后续模型处理时,不再需要维护原始文本 token 的 KV 缓存,只保留记忆 token 的 KV 缓存就能替代,从根本上实现 “压缩存储”。
- KV空间压缩:记忆token的注意力计算与缓存更新 为确保记忆token能有效捕捉并留存全局语义,论文设计了针对记忆token的专属注意力机制与KV缓存更新规则,整个过程的核心在于实现“记忆token与原始文本token的双向注意力交互”,避免记忆token因独立计算而丢失文本关联。首先,在参数层面,为记忆token初始化了独立的查询(Q)、键(K)、值(V)投影权重矩阵,即
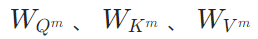 ,这些权重矩阵与原始文本token使用的权重矩阵完全分离,以此确保记忆token能专注于“语义浓缩”这一核心任务,不受原始文本token参数的干扰。其次,在注意力计算环节,处理每个“原始文本窗口+记忆token”单元时,模型会同时对两类token的注意力进行计算:一方面,基于记忆token的嵌入矩阵
,这些权重矩阵与原始文本token使用的权重矩阵完全分离,以此确保记忆token能专注于“语义浓缩”这一核心任务,不受原始文本token参数的干扰。其次,在注意力计算环节,处理每个“原始文本窗口+记忆token”单元时,模型会同时对两类token的注意力进行计算:一方面,基于记忆token的嵌入矩阵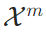 ,通过专属权重矩阵计算出对应的Q、K、V,公式为:
,通过专属权重矩阵计算出对应的Q、K、V,公式为: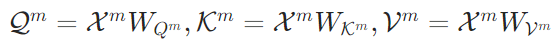 另一方面,将原始文本token的Q、K、V与记忆token的Q、K、V进行拼接,进而计算全局注意力,具体公式为:
另一方面,将原始文本token的Q、K、V与记忆token的Q、K、V进行拼接,进而计算全局注意力,具体公式为: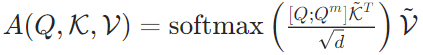 其中,
其中,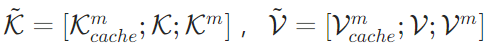 分别代表历史处理过程中积累的记忆token的KV缓存。最后,在缓存更新策略上,每处理完一个“原始文本窗口+记忆token”单元后,模型会丢弃原始文本token的KV缓存(
分别代表历史处理过程中积累的记忆token的KV缓存。最后,在缓存更新策略上,每处理完一个“原始文本窗口+记忆token”单元后,模型会丢弃原始文本token的KV缓存(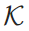 与
与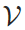 ),仅保留记忆token的KV缓存(
),仅保留记忆token的KV缓存(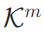 与
与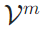 ),并将其与历史记忆缓存进行拼接更新,即
),并将其与历史记忆缓存进行拼接更新,即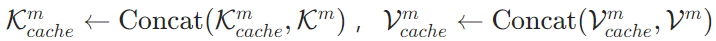 ——这一步是实现“KV空间压缩”与“内存降低”的关键,通过用少量记忆token的缓存替代大量原始文本token的缓存,直接实现内存占用的线性降低。
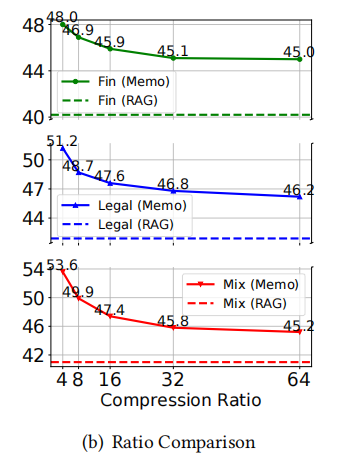
——这一步是实现“KV空间压缩”与“内存降低”的关键,通过用少量记忆token的缓存替代大量原始文本token的缓存,直接实现内存占用的线性降低。 - 压缩比控制:灵活平衡效率与语义完整性 论文用 “压缩比β=l/k” (其中lll为原始文本窗口长度,kkk为记忆token数量)来控制 KV 缓存的压缩程度,这里的 β 是原始文本窗口长度和记忆 token 数量的比值,支持 4、8、16、32、64 等多档配置,能根据不同任务的需求灵活调整。从压缩效果来看,当 β=64 时,128K tokens 的原始文本窗口,只需要 2K 记忆 token 就能覆盖,GPU 内存占用能降低约 64 倍;原本只能处理 128K tokens 的 LLM,这时能处理高达 8M tokens 的超长篇文本,彻底突破了原生上下文窗口的限制。在性能平衡上,实验显示,随着 β 增大(压缩更激进),模型性能会轻微下降,但当 β=32 时,性能就趋于稳定了 —— 即便 β=64(极端压缩),MemoRAG 在 LongBench 基准的 “NarrativeQA 问答任务” 中,F1 得分仍有 26.3,比传统 RAG 方法(如 BGE-M3 的 20.3)还高,这说明就算压缩得很厉害,记忆 token 也能保留原始文本的关键语义,不影响后续任务性能。
三段式训练:让记忆模块“会记忆、能生成”
为确保记忆模块能生成有效线索,团队设计“预训练→监督微调(SFT)→生成反馈强化学习(RLGF)”的三段式训练流程,仅优化记忆模块的新增参数(如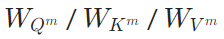 ),冻结底层LLM参数,大幅降低训练成本。
),冻结底层LLM参数,大幅降低训练成本。
- 预训练:让模型学习“浓缩语义”,使记忆token具备“吸收窗口语义”的能力,确保全局记忆能完整留存长文本关键信息——给模型输入长文本,训练其用记忆token预测下一个token,确保记忆能保留关键信息。损失函数采用交叉熵损失,最大化“基于记忆+当前文本”生成正确下一个token的概率:
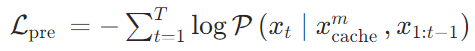
- 监督微调(SFT):预训练后的记忆模块仅具备“语义浓缩”能力,需通过SFT让其学会“基于任务生成检索线索”,适配不同长上下文任务(如问答、摘要)——给模型输入“查询+全局记忆”,让其生成与任务匹配的线索(如摘要任务生成“核心观点”,问答任务生成“关键实体”);输入“长文本+任务指令(如查询、摘要要求)”,让记忆模块生成线索;采用交叉熵损失,最小化生成线索与人工标注线索的差异,公式为:
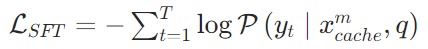
- 生成反馈强化学习(RLGF):SFT仅保证线索与标注的“文本匹配”,但无法确保线索能引导检索到高质量证据(即“线索的实际效用”)。RLGF通过“最终答案质量反哺线索生成”,让记忆模块优先生成“能提升检索-生成效果”的线索——如果某条线索能引导检索到高质量证据,就给这条线索“奖励”,让模型优先生成类似线索。用“最终答案质量”作为线索的奖励(
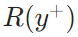 为偏好线索的奖励,
为偏好线索的奖励,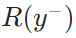 为非偏好线索的奖励),采用基于偏好的排序损失,驱动模型生成更优线索,公式为:
为非偏好线索的奖励),采用基于偏好的排序损失,驱动模型生成更优线索,公式为: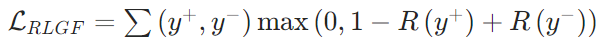 该损失确保“偏好线索的奖励高于非偏好线索”,若
该损失确保“偏好线索的奖励高于非偏好线索”,若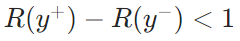 ,则触发损失优化;
,则触发损失优化;
04、实验验证:MemoRAG有多强?
团队在 LongBench、InfiniteBench(主流长上下文基准)和自建的 UltraDomain(覆盖法律、金融、物理等 20 个领域)三个数据集上做了测试,结果证明 MemoRAG 在 “性能”“泛化性”“效率” 三方面全面领先,同时通过消融实验进一步验证了核心设计的必要性与鲁棒性。
性能:碾压传统RAG与长LLM
先看结论,MemoRAG在性能上持续优于标准RAG、先进RAG系统及长上下文LLM;其适用范围突破简单问答任务,能有效处理非问答任务与复杂问答任务。得益于全局记忆增强检索,MemoRAG在标准RAG系统难以应对的场景中,优势尤为明显。
在简单QA任务(如HotpotQA多文档问答)中,MemoRAG的F1得分比传统RAG(如HyDE、GraphRAG)高10%-15%;在非QA任务(如政府报告摘要)中,优势更明显——传统RAG因无法处理模糊需求,摘要完整性得分仅28分,而MemoRAG达到32.9分(满分50),甚至超过直接用128K LLM处理全文本的效果(32.2分)。
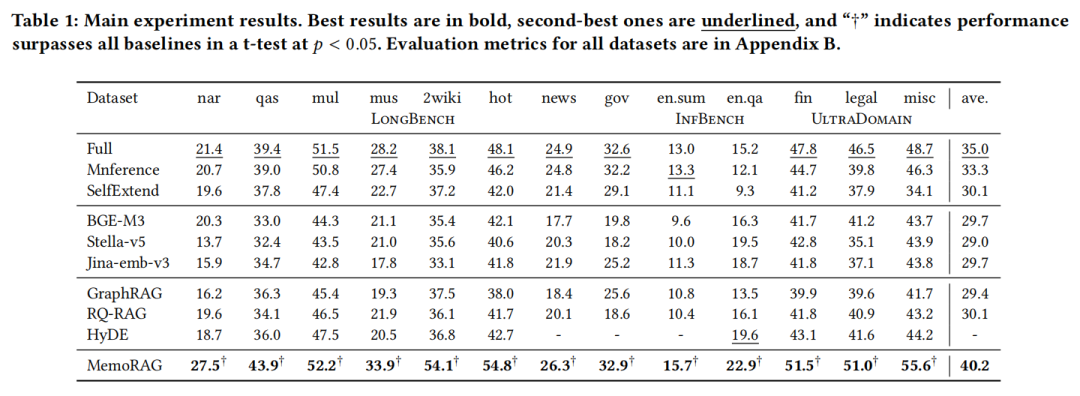
在UltraDomain的法律数据集上,面对56K tokens的合同文本,传统RAG回答“Outside Date的意义”时,仅能给出“是一个截止日期”的模糊答案(F1=0.36),而MemoRAG能精准定位“Outside Date为2020年10月5日,未达标则合同自动终止”(F1=0.83)。

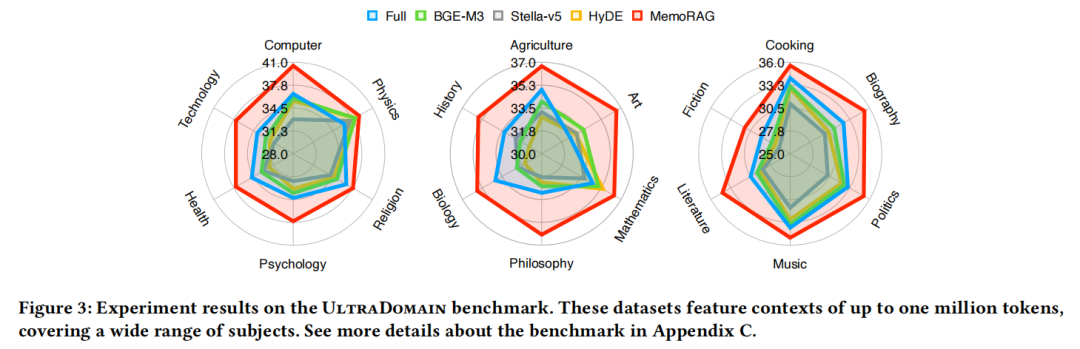
泛化性:跨领域无压力
UltraDomain数据集覆盖20个领域,包括数学公式推导、农业技术手册、音乐理论等专业内容。测试显示,MemoRAG在所有领域的表现均优于基线——即使在完全未训练过的“烹饪教程摘要”“哲学论文问答”任务中,得分仍比传统RAG高20%以上,证明其全局记忆模块能快速适配不同领域的语义逻辑。
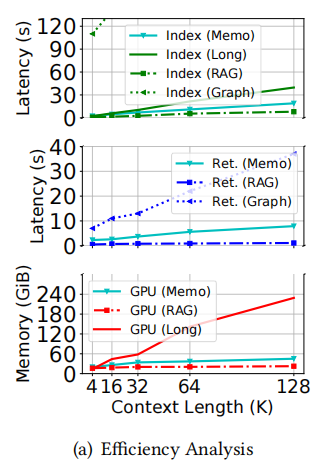
效率:内存与速度的平衡
处理128K tokens文本时:
- 长LLM(如Phi-3-mini-128K)需60GiB以上GPU内存,预填充时间超过40秒;
- MemoRAG因采用KV压缩,内存占用仅45GiB,预填充时间缩短至25秒,检索速度虽比传统RAG慢10%(需生成线索),但远快于GraphRAG(依赖GPT-4o API,检索时间超1分钟)。
综合实验结果来看,MemoRAG在时间与内存效率上实现了良好平衡:尽管其速度慢于标准RAG,但在时间与内存效率上均优于先进RAG方法与长上下文LLM。
消融实验:验证核心设计的必要性与鲁棒性
- 模型设计与优化策略:对比轻量级与紧凑型记忆及不同训练阶段性能,发现每项技术设计均对 MemoRAG 有效性有独特贡献,移除任意一项会导致性能下降,验证了各组件的必要性。
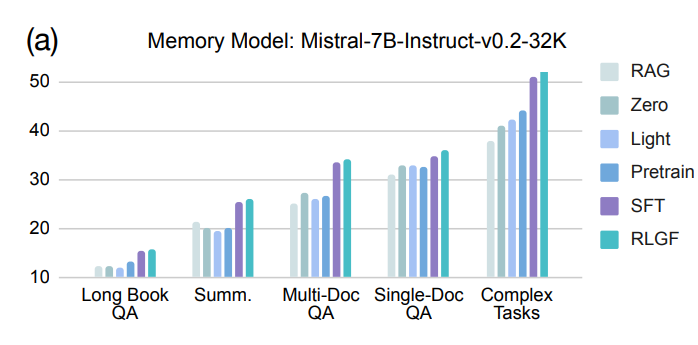
- 基础模型选择:将记忆模型底层 LLM 替换为 Qwen2-7B-instruct 后,仍能实现稳定性能提升,表明 MemoRAG 记忆模型设计鲁棒且适配多种 LLM。
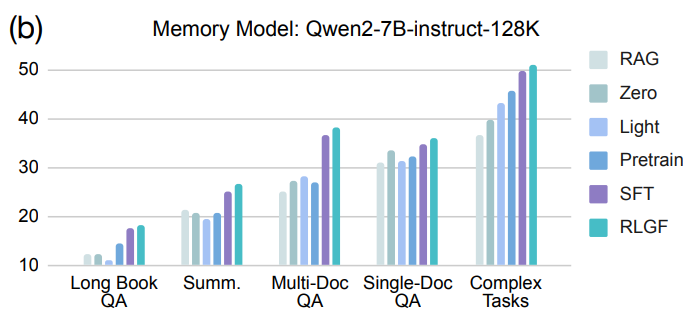
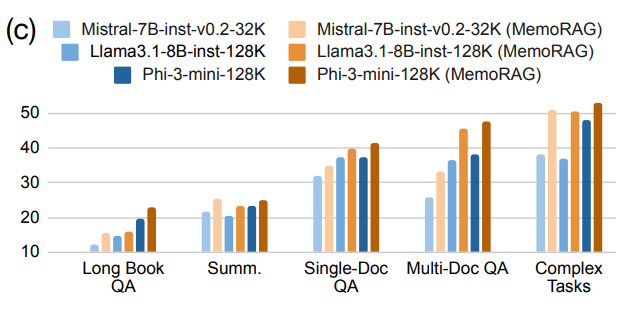
- 不同生成器影响:搭配三种不同生成器时,MemoRAG 性能均优于直接使用长 LLMs,且上下文超出生成器原生窗口时性能差距扩大,证明其适配不同生成器并能提升任务性能。
- 压缩比影响:压缩比 β 增大时性能呈下降趋势但 β=32 后趋于稳定,且所有 β 取值下 MemoRAG 性能均优于标准 RAG,说明其能平衡效率与性能并捕捉关键信息。
05、落地思考:MemoRAG如何解决实际问题?
MemoRAG的价值不仅在于技术突破,更在于为企业级知识库、长文档分析等场景提供了可行方案。结合论文与实践经验,落地时需重点关注“记忆与文本块的协同”“多文档处理”两个核心问题。
存储设计:隔离存储+关联索引
MemoRAG需要存储“全局记忆向量”和“原始文本块”两类数据,建议采用“双存储层”设计:
- 记忆向量层:用轻量KV存储保存每个文档的全局记忆向量,核心字段包括“文档ID”“记忆向量”“生成时间”——用于快速加载记忆,生成线索;
- 文本块层:用向量数据库存储切割后的文本块,核心字段包括“文档ID”“文本内容”“位置信息”——用于线索引导的精准检索;
- 关联机制:通过“文档ID”建立两者关联,确保线索仅检索对应文档的文本块,避免跨文档混乱。
多文档场景:先粗筛,再细查
面对跨文档任务(如“对比3份财务报告的营收趋势”),MemoRAG的处理逻辑为:
- 先对所有文档生成全局记忆,建立“文档元数据向量库”(存储每个文档的标题、摘要向量);
- 用用户查询粗筛出Top 5相关文档(如“2022-2024年营收报告”);
- 对每个文档生成线索,分别检索对应文本块;
- 最后汇总多文档的线索与细节,生成对比性答案。
06、总结:RAG技术的下一站是什么?
MemoRAG的出现,标志着RAG从“工具”向“智能系统”迈进了一步——它不再依赖用户提供明确查询,而是能主动理解模糊需求,通过“记忆-线索”环节搭建“需求与数据”的桥梁。
对于开发者和企业而言,MemoRAG的价值在于:
- 降低长文本处理成本:无需为128K+上下文的LLM支付高昂算力,用轻量级模型+KV压缩即可处理超长文本;
- 拓展RAG应用边界:首次将RAG从简单QA推向摘要、跨文档分析、法律合同解读等复杂场景;
未来,随着记忆模块的进一步优化(如动态调整压缩比、多模态记忆),RAG或许能真正实现“像人一样理解长文档”,为医疗报告分析、学术论文解读、企业知识库等领域带来更颠覆性的改变。


