
半个月前,知识星球中有个关于 text2sql 的讨论,后续又陆续有成员私信沟通。这篇节取了个目前手头项目的 MVP (最小可行化)版本,来和各位做个分享交流,也希望听到来自不同场景的最佳实践。
这篇试图说清楚:
信贷风控策略迭代场景的标准流程、Text2SQL 三类技术方案,MVP 版本的 Coze text2sql 工作流,以及对人机协同的一些碎片思考。
以下,enjoy:
1、业务场景剖析
因为过去几年混迹在金融科技圈的原因,这篇就选择我相对熟悉的,线上企业信贷产品的风控策略调优场景展开聊聊。为了方便各位更好理解,我会先花点篇幅介绍下标准企业信贷风险策略迭代的完整流程,以及技术门槛对企业信贷风控效率的影响。(不感兴趣的,可以直接跳到下一章 text2sql 技术方案)
1.1企业信贷风险策略迭代的完整流程
传统消费贷产品的风控三板斧,已经有大量的行业最佳实践。但纯线上的企业信贷产品,因为企业经营状况更加复杂多变,数据维度也更加多元,对于风险策略的更新维护也有了更高的专业要求。举个例子来说,比如某城商行的税贷产品,上线三个月后发现批发零售行业的 M3 逾期率达到 4.2%,远超 2.5%的风险容忍度。风险策略经理面对这种情况,一般会遵循如下策略迭代流程:
多个维度问题诊断:
企业违约往往有迹可循,可以从多个数据源交叉验证,策略经理编写的第一批 SQL 可能类似于:
复制-- 企业基础画像分析
SELECT
a.行业细分, a.注册资本, a.成立年限,
b.近12月开票金额, b.开票稳定性系数,
c.被执行人次数, c.最近被执行时间,
d.纳税信用等级, d.近期纳税金额波动率,
COUNT(DISTINCT a.企业ID) as 企业数,
AVG(CASE WHEN e.M3_flag = 1 THEN 1 ELSE 0 END) as M3逾期率
FROM 企业基础信息表 a
LEFT JOIN 发票数据表 b ON a.企业ID = b.企业ID
LEFT JOIN 司法数据表 c ON a.统一社会信用代码 = c.统一社会信用代码
LEFT JOIN 税务数据表 d ON a.纳税人识别号 = d.纳税人识别号
INNER JOIN 贷款表现表 e ON a.企业ID = e.企业ID
WHERE e.放款日期 BETWEEN '2024-01-01' AND '2024-03-31'
GROUP BY 1,2,3,4,5,6,7,8,9进一步归因分析:
假设初步发现问题是集中在"成立时间 2-3 年"且"近期开票金额下滑"的企业 中,考虑到批发零售行业的季节性波动确实很大,简单的环比下降也可能是正常现象,需要结合行业特性进一步深挖。因此,风险策略经理一般需要进一步的构建更复杂的查询,例如:
复制-- 剔除季节性因素的真实经营变化
WITH 行业季节性因子 AS (
SELECT 月份, AVG(开票金额环比) as 行业平均环比
FROM 历史开票数据
WHERE 行业 = '批发零售' AND 年份 IN (2021, 2022, 2023)
GROUP BY 月份
)
SELECT
企业ID,
(实际开票环比 - 行业平均环比) as 剔除季节性后的变化,
法人近3个月征信查询次数,
上下游集中度指标, -- 前5大客户/供应商占比
库存周转率变化
FROM ...行业特色变量设计
经过上述两步分析,策略经理往往会设计出一系列针对批发零售行业的风险特征,例如:
经营稳定性指标群:
开票客户数变化率(反映客户流失)
开票金额集中度趋势(大客户依赖风险)
进销项匹配度(识别虚假贸易)
还款能力预警指标:
应收账款周转天数拉长预警
存货周转率恶化指数
现金流覆盖倍数(基于开票和纳税数据估算)
还款意愿识别指标:
法人个人负债上升速度
企业诉讼案件增长率
关联企业风险传染指数
这些细化的行业风险特征设计,会带来一些很大的工作量进行验证。实际场景中,可能每个指标的开发都需要关联 5-10 张表,处理至少几十万条记录。(比如一个"进销项匹配度"指标的计算就需要近 200 行 SQL。)
1.2技术门槛对企业信贷风控效率的影响
为了更好的说明下述要介绍到的基于 LLM 驱动的工作流好处,这里再适当扩充描述下时效性的问题。同样的,还是举一些实际场景中的案例进行说明。例如当一个风险策略经理发现一个纺织企业客户逾期后,他想分析下是个案还是行业性风险,就可能慧聪以下方向考虑衍生变量加工:
- 所有纺织行业客户的风险表现
- 这些客户的上下游关系网络
- 近期原材料价格波动对其影响
现实情况中,第一个查询可能就要关联 15+张表,因为企业数据分散在不同系统。例如工商数据在 A 库,税务数据在 B 库,司法数据存在C库。
到最后的剧情往往是,写完 SQL 花了两天,跑的时候因为数据量太大超时了,最后只能分批查询,手工拼接结果。等分析完已经是一周后的事情。但如果是行业性、区域性的风险,从出现异常信号到实质性违约,窗口期可能只有 30-60 天。如果类似市场环境变化的时候,策略调整总是慢半拍,就可能会导致批量违约的发生。
2、Text2SQL 三类技术方案
text2sql 这个名次其实由来已久,遵循讲清楚来龙去脉的文章风格,下面通过一些具体的对比来说明下我了解到的三个阶段的技术方案对比。
2.1基于规则的方法:词典映射与模板匹配
早期的 Text2SQL 类似一个翻译词典。公开信息可查的是,早在 2010 年前后,各大银行的 IT 部门流行过建立一个庞大的映射规则库的做法,类似:
复制"客户" → "customer_table" "上个月" → "date >= DATEADD(month, -1, GETDATE())" "逾期" → "overdue_flag = 1"
然后当用户输入"查询上个月逾期客户"时,系统会进行分词和映射:
1.分词:[查询] [上个月] [逾期] [客户]
2.映射:SELECT * FROM customer_table WHERE overdue_flag = 1 AND date >= DATEADD(month, -1, GETDATE())
这个做法看起来很符合暴力美学,只要组织人手尽可能的穷尽常用的一些映射关系即可。但实际的问题是,只要用户的表达稍微灵活一点,系统就无法处理。比如用户说"最近表现不太好的企业客户",系统完全不知道"表现不太好"对应什么字段。另外维护成本也是个坑,每次新增一个业务术语,都要手动添加规则,还要保证和既有规则不能冲突。
2.2基于深度学习的方法:让机器学习"翻译"
18 年前后随着 BERT 这些模型的出现,Text2SQL 开始进入深度学习时代。 核心逻辑从依赖人工规则,升级成了让模型从大量的"问题-SQL"对中学习映射模式。 训练过程类似教小孩说话:
复制输入:"查询上海地区的企业客户" 标注:SELECT \* FROM enterprise WHERE city = '上海' 输入:"统计上海的制造业企业数量" 标注:SELECT COUNT(\*) FROM enterprise WHERE city = '上海' AND industry = '制造业' ...(准备10万条这样的训练数据)
模型比如会学习到:"查询"通常对应 SELECT,"统计...数量"对应 COUNT(*),地名通常出现在 WHERE 子句中。我查到国内有家金融科技公司基于 Seq2Seq 架构训练了一个模型,在标准数据集上准确率号称达到了 85%。演示效果也很惊艳,类似效果:
复制输入:"过去三个月新增的优质客户有多少"
输出:SELECT COUNT(\*) FROM customer
WHERE create_date >= DATEADD(month, -3, GETDATE())
AND customer_level = 'A'但这种方法对没见过的表达方式准确率会明显下降("优质"在训练集里对应 customer_level='A',但用户说"高价值"时就会识别不了),同时对于复杂查询(比如 3 个表以上的 JOIN)基本生成不对。但最麻烦的是,这种黑盒子的方法,错了也不知道错在哪。
2.3大语言模型时代:理解语义而非记忆模式
ChatGPT3.5 发布到现在也两年半的时间了,尤其是年初 DeepSeekR1 让公众开始熟悉的 LLM 慢思考能力,可以在 text2sql 这个场景中,从以往学习"问题→SQL"的映射的路线,变成真正理解用户意图和数据库语义的方法。举个具体例子来说,
用户说:"帮我看看最近经营状况恶化的纺织企业"
规则方法:error(没有定义"经营状况恶化")
深度学习:可能输出 SELECT * FROM enterprise WHERE status = 'bad'(瞎猜)
而LLM可能会这样推理:
"经营状况恶化"→需要对比不同时期的经营指标
纺织企业→需要过滤行业
可能的指标:营收下降、利润率降低、现金流紧张
最后生成的 SQL 例如:
复制WITH 企业经营指标 AS (
SELECT
企业ID,
(本期营收 - 上期营收) / 上期营收 as 营收增长率,
(本期利润率 - 上期利润率) as 利润率变化
FROM 财务数据表
WHERE 统计期间 IN ('2024Q1', '2023Q4')
)
SELECT
a.企业名称,
b.营收增长率,
b.利润率变化
FROM 企业信息表 a
JOIN 企业经营指标 b ON a.企业ID = b.企业ID
WHERE a.行业分类 = '纺织业'
AND (b.营收增长率 < -0.1 OR b.利润率变化 < -0.05)
ORDER BY b.营收增长率当然,必须要说明的是,这种基于 LLM 驱动的推理做法也有其自身的局限性,例如可能生成不存在的字段名,同样的问题可能生成不同的 SQL 等。这也是为什么在工作流中,需要考虑结合知识库和验证机制的方法,既利用 LLM 的理解能力,又通过规则确保准确性和一致性。
3、基于扣子的工作流实现方案
因为目前这个项目方内部使用 Coze 作为主要的工作流平台,所以下述工作流的演示也以 Coze 为例,各位可以如果要复现,也可以选择通过 Dify 或者其他类似工作流平台。
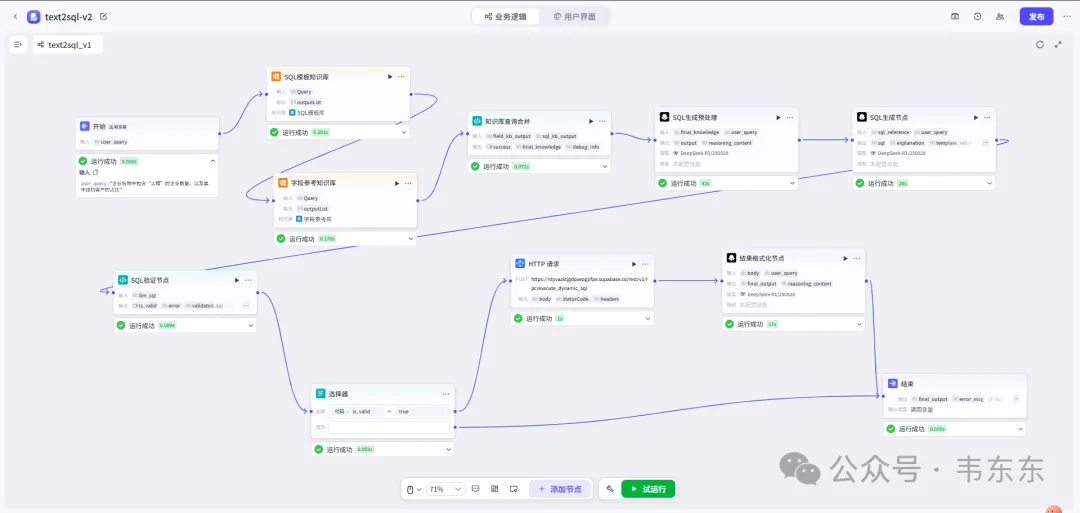
3.1整体架构设计思路
节取的这个 MVP 版本保持了原方案的"理解-增强-生成-验证"四层架构,一些可以重点关注的节点:
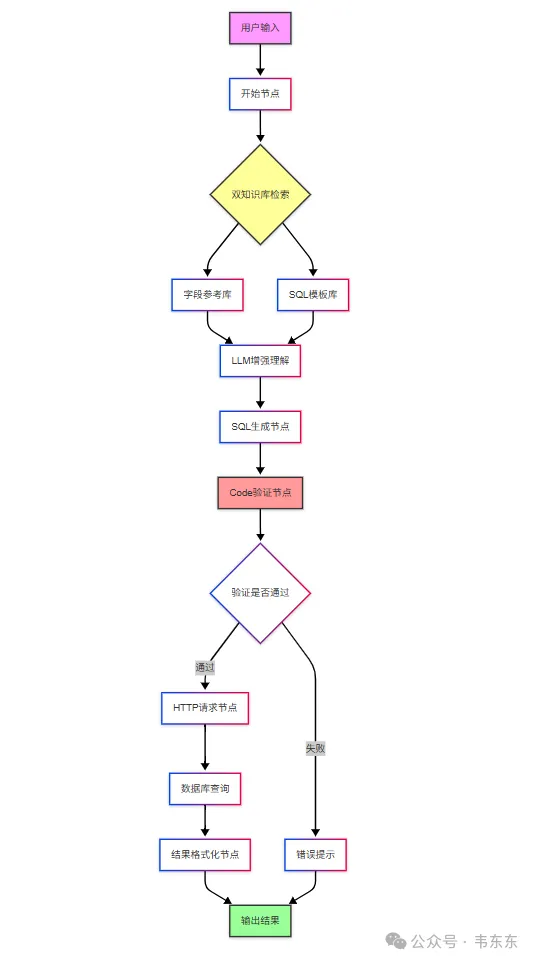
双知识库前置:在生成 SQL 前先检索相关知识,大幅提升首次生成准确率
SQL生成预处理:在正式生成SQL前,设置专门LLM节点结合知识库输出进行SQL生成方案规划
分层验证机制:语法验证、语义验证、安全验证等多重校验
3.2核心节点功能拆解
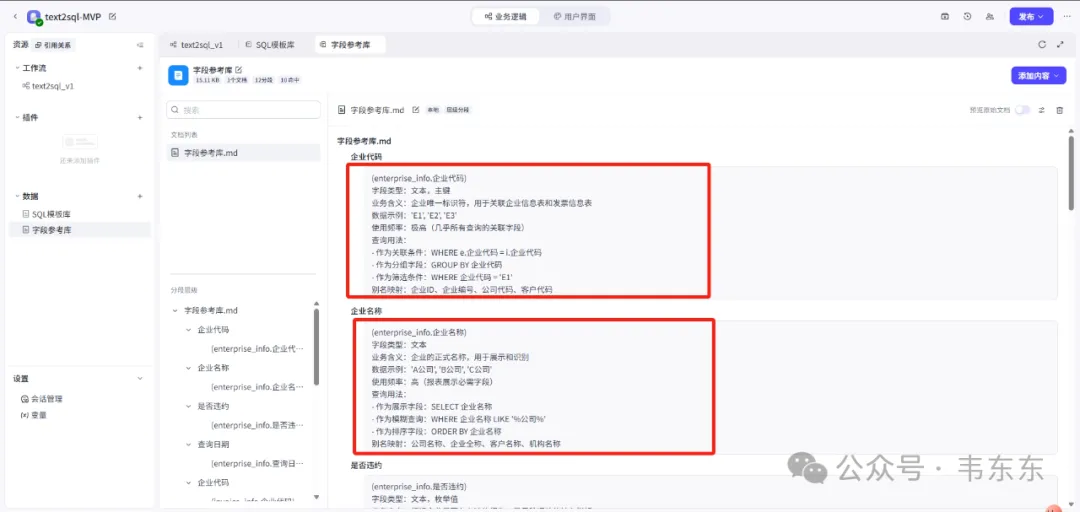
字段参考库查询节点:动态 schema 映射
这个节点解决了企业数据库的一个普遍痛点——同一个业务含义在不同表中的字段名不一致,例如:
{
"企业标识": {
"主键字段": \["enterprise_id", "ent_id", "company_id"\],
"工商信息": \["unified_social_credit_code", "uscc", "社会信用代码"\],
"税务信息": \["taxpayer_id", "nsrsbh", "纳税人识别号"\]
},
"经营指标": {
"营业收入": {
"字段名": \["revenue", "income", "营业收入", "销售额"\],
"所在表": \["financial_data", "tax_report", "invoice_summary"\],
"计算说明": "如无直接字段,可通过发票金额汇总估算"
}
}
}模糊匹配:用户说"收入",能匹配到 revenue、income 等
同义词扩展:用户说"营收",自动关联"营业收入"、"销售额"
跨表提示:告知 LLM 某个指标在多个表中都有,需要选择或关联
SQL 模板库查询节点:场景化最佳实践
不同于简单的 SQL 片段,这里存储的是经过验证的业务场景解决方案,例如
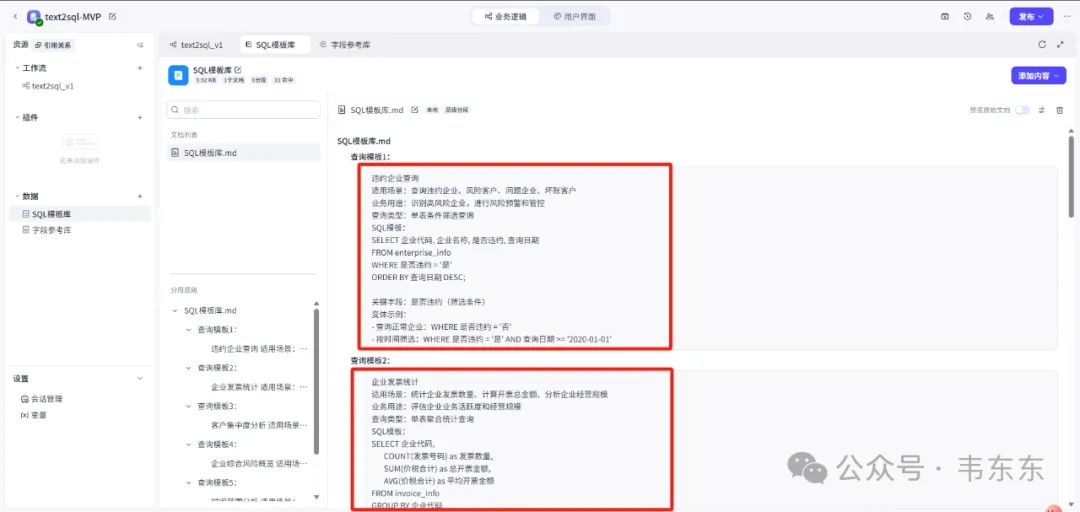
-- 模板名称:企业关联风险全景图
-- 适用场景:查询目标企业的关联方风险暴露
-- 输入参数:{enterprise_id}
WITH 关联企业 AS (
-- 通过共同法人找关联方
SELECT DISTINCT b.企业ID as 关联企业ID
FROM 企业基础信息 a
JOIN 企业基础信息 b ON a.法人身份证 = b.法人身份证
WHERE a.企业ID = {enterprise_id} AND b.企业ID != {enterprise_id}
)
SELECT
风险类型,
COUNT(DISTINCT 关联企业ID) as 涉险企业数,
SUM(风险金额) as 风险敞口总额,
GROUP_CONCAT(企业名称) as 具体企业清单
FROM (
-- 各类风险汇总逻辑...
)
GROUP BY 风险类型模板元数据:
使用频率:记录被调用次数,高频模板优先推荐
效果反馈:记录查询耗时、结果准确率
适配性标记:标注适用的数据库版本、表结构版本
SQL 生成预处理节点
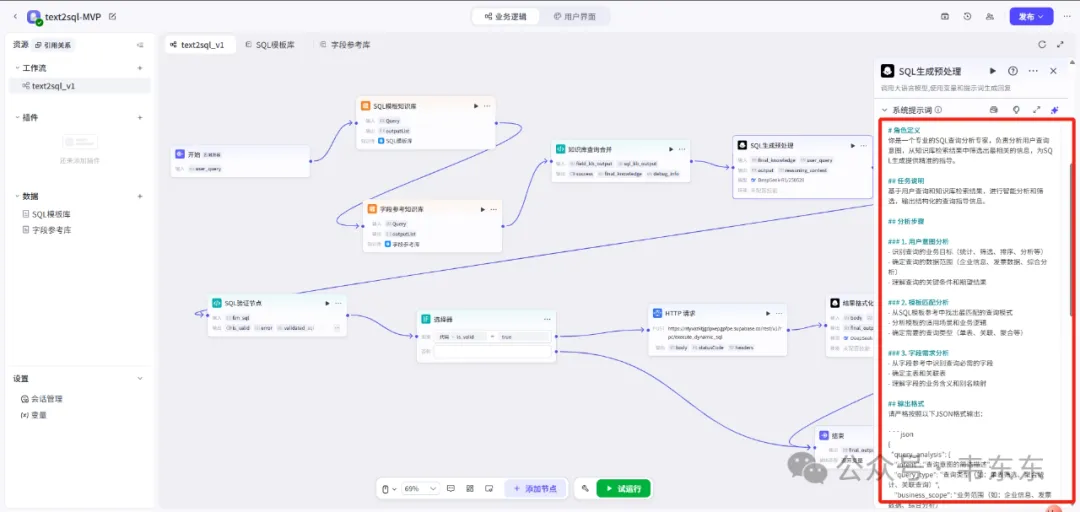
这是一个关键的中间节点,位于知识库查询和 SQL 生成之间,负责把用户的自然语言需求转化为结构化的查询计划。好处就是降低了下一个 sql 生成节点的压力,实测确实对于最后的准确度提升有所帮助,但是也会带来更多的耗时和 tooken 消耗。
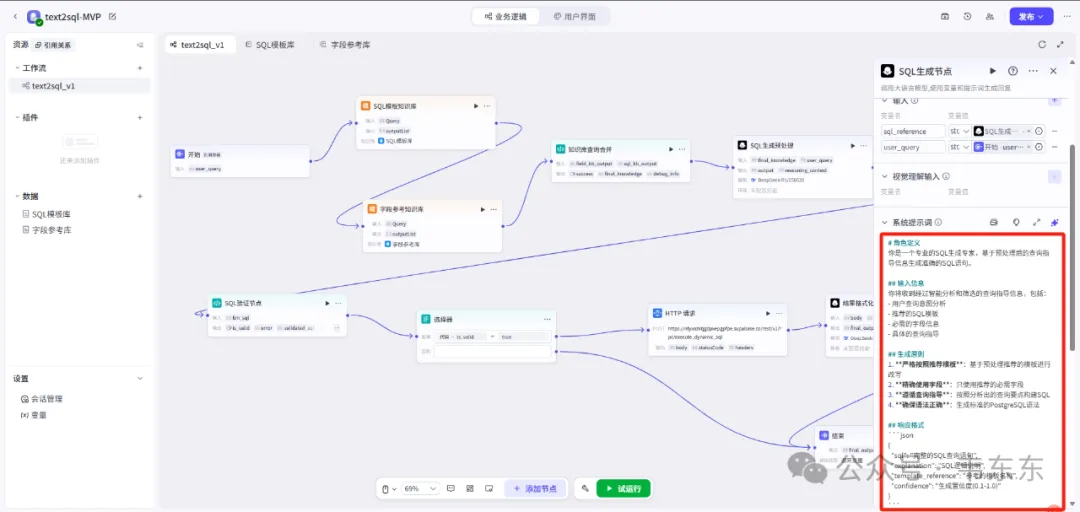
SQL 生成节点
这是整个流程的核心,选择有思维链的最新 LLM(例如 DeepSeek-R1-0528),并且通过精心设计的 Prompt 充分发挥 LLM 能力。
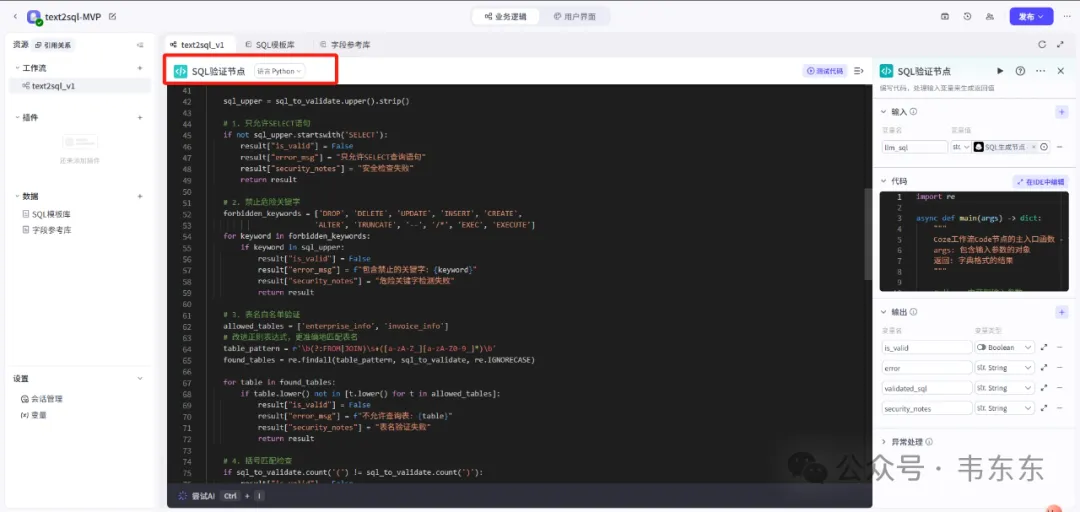
SQL 验证节点
这个节点是设置了六道验证:空值检查、查询类型限制、危险关键字过滤、表名白名单、语法校验、长度限制,确保 SQL 的安全性。同时还设计了自动为非聚合查询添加 LIMIT 限制、清理格式、适配特定数据库平台的特性。这个节点完美诠释了"防御性编程"思想,不仅可以拦截恶意或错误的 SQL,还能将合法的 SQL 优化得更加规范和高效。
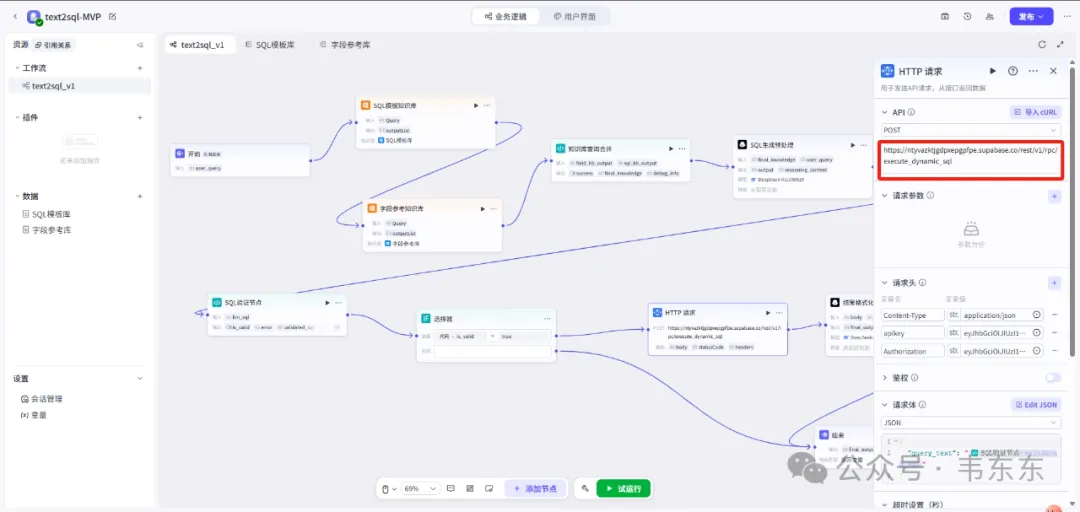
HTTP 请求节点
为了演示所需,这个工作流中所使用的数据我存在了 supabase 数据库中,可以通过 POST 请求把上游节点中输出的 sql 放在请求体中实现查询。
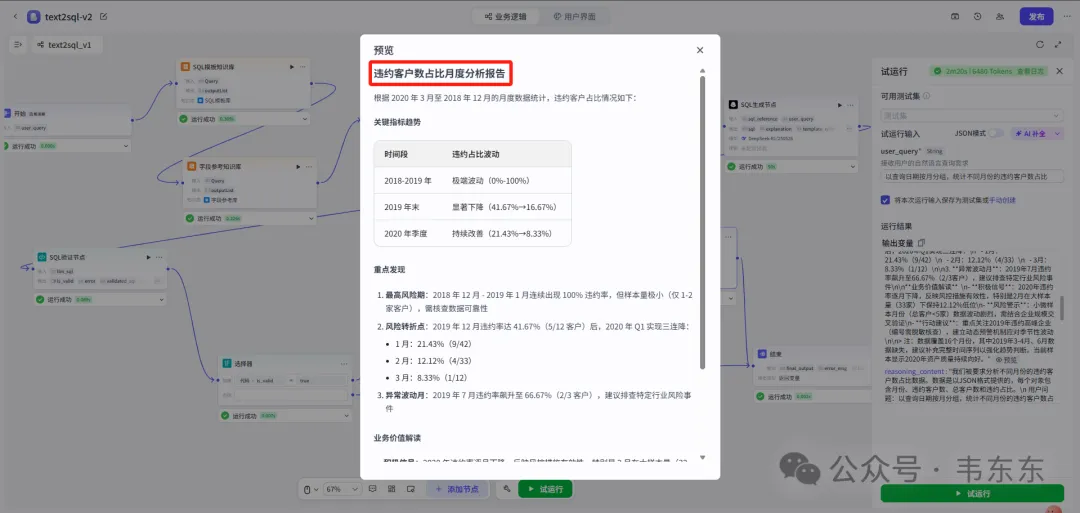
3.3问答案例演示
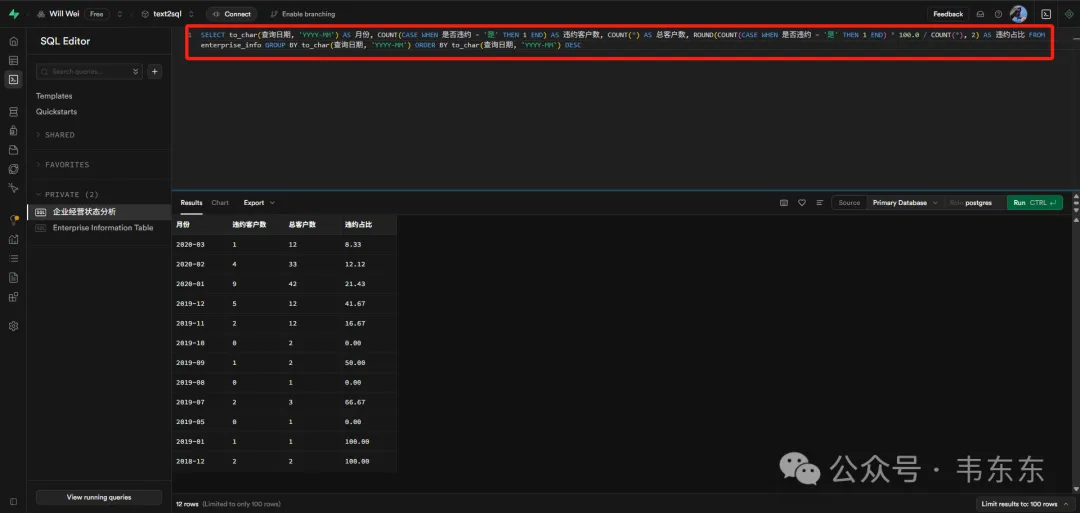
测试问题1:
{"user_query": "以查询日期按月分组,统计不同月份的违约客户数占比"}
生成的SQL语句:
复制SELECT
to_char(查询日期, 'YYYY-MM') AS 月份,
COUNT(CASE WHEN 是否违约 = '是' THEN 1 END) AS 违约客户数,
COUNT(*) AS 总客户数,
ROUND(COUNT(CASE WHEN 是否违约 = '是' THEN 1 END) * 100.0 / COUNT(*), 2) AS 违约占比
FROM enterprise_info
GROUP BY to_char(查询日期, 'YYYY-MM')
ORDER BY to_char(查询日期, 'YYYY-MM') DESC;复制按月统计企业违约情况 计算每月的违约客户数量 计算每月的总客户数量 计算违约占比(百分比,保留2位小数) 按月份降序排列结果
测试问题2:
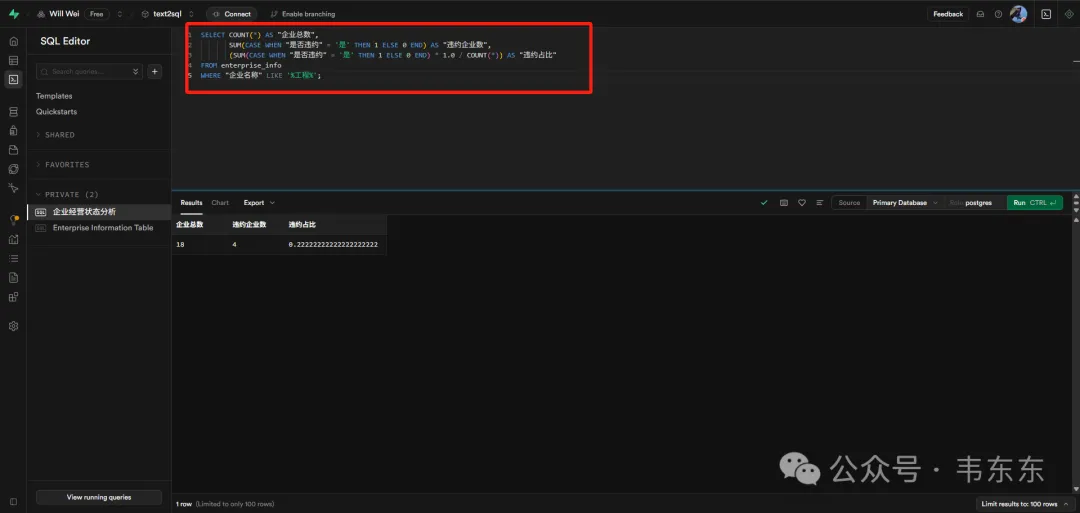
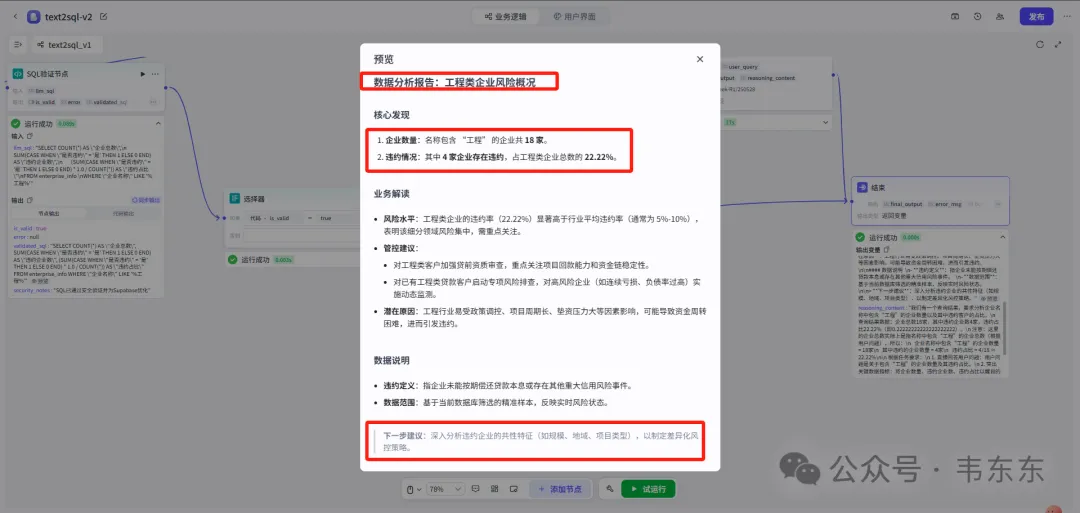
{"user_query": "企业名称中包含“工程”的企业数量,以及其中违约客户的占比"}
生成的SQL语句:
复制SELECT COUNT(*) AS "企业总数",
SUM(CASE WHEN "是否违约" = '是' THEN 1 ELSE 0 END) AS "违约企业数",
(SUM(CASE WHEN "是否违约" = '是' THEN 1 ELSE 0 END) * 1.0 / COUNT(*)) AS "违约占比"
FROM enterprise_info
WHERE "企业名称" LIKE '%工程%';复制筛选企业名称包含"工程"字样的企业 统计工程类企业的总数量 计算工程类企业中的违约企业数量 计算工程类企业的违约占比(小数格式) 通过单行汇总展示整体风险水平
3.4后续更新预告
预计6月中下旬,等手头项目告一段落后,我会再写篇文章介绍下如何在目前演示 的MVP版本基础上,实现包含以下四个维度的增强方案:
- 架构升级:引入Neo4j图数据库构建企业关系图谱,通过知识图谱增强LLM对复杂多表关联和业务实体关系的理解,支持更深层次的关联分析和风险传导路径挖掘;
- 分析智能化:在SQL取数基础上集成Python自动化分析节点,实现KS、IV、PSI等风险指标的自动计算,支持变量分箱、WOE编码、相关性分析等策略开发全流程的代码自动生成;
- 可视化增强:基于分析结果自动生成交互式图表和策略效果监控Dashboard,支持策略表现的实时追踪和多维度对比分析;
- Agent化演进:构建支持多轮对话的策略分析Agent,具备上下文记忆、策略版本管理、A/B测试设计等高级功能,实现从单次查询到持续策略优化的智能化转变。
4、写在最后
虽然目前 LLM 的能力还没有明显收敛,但底座 LLM 的推理水平也已经在很多场景下被验证有效。这也是上述这个扣子工作流试图演示的技术赋能业务打开方式。
不过文章中演示的案例只是个MVP版本,实际使用需要各位结合自身的业务场景进行大量测试后针对性调优。LLM 可能会生成语法完美,但业务逻辑错误的查询,比如将"经营状况恶化"简单理解为"status = 'bad'",忽略了需要对比不同时期的财务指标。这种深层的业务理解,依然是这个领域专业人士的价值所在。当技术门槛被 AI 逐渐抹平后,风险策略经理的核心竞争力也就正在从"如何写 SQL"转向"如何定义问题"。
LLM 时代的专业价值正在被慢慢重塑,LLM 能力边界与人类专业判断的平衡是我们每个人工作中都要面对的课题,技术赋能专业,而非替代专业,猜想未来人机协作的最佳实践模式是人负责 WHY 和 WHAT,AI 负责 HOW。


