语音大模型
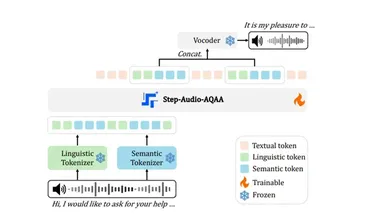
开源端到端语音大模型Step-Audio-AQAA:听懂音频直接生成自然语音
在人工智能领域,尤其是生成式对抗网络(AIGC)方面的不断进展,语音交互已成为一个重要的研究方向。 传统的大语言模型(LLM)主要专注于文本处理,无法直接生成自然语音,这在一定程度上影响了人机音频交互的流畅性。 为了突破这一局限,Step-Audio 团队开源了一款全新的端到端语音大模型 ——Step-Audio-AQAA。

几十个测试后,发现海螺语音与 ElevenLabs 掰手腕的能力不是盖的
试想一个场景,职场中接到一个香港客户的单子,但是在交付的过程中耽搁了时间,现在要进行线上沟通解释,那么你面对的情况大致是这样的:如果不对这段音频进行标注,可能大部分人会认为这一粤语、英语混用的片段是真实发生或从TVB电视剧里截出来的。 但其实,这是由 AI 完成的配音,背后所使用的工具是海螺语音。 今年 1 月,继 MiniMax 发布并开源基础语言大模型 MiniMax-Text-01 和视觉多模态大模型 MiniMax-VL-01 后,再次推出了升级的语音大模型 T2A-01 系列,搭载于海螺 AI 之上,开辟海螺语音板块。

个性经济时代,MiniMax 语音大模型如何 To C?
大约一个月前,距离 GPT Store 上线还有两周,一位名为 Kyle Tryon 的国外开发者在个人博客上分享了其基于 ChatGPT Plus 开发的三个 Agent(又称“GPTs”),其中一个 Agent 是关于美国费城旅游出行的个人指南“PhillyGPT”,它能访问当地 SEPTA 公共交通 API,为个人提供费城当地的实时天气、旅游资讯、文艺演出活动、出行路线、公交车站与地标数据、预计抵达时间等等。 具体可访问 PhillyGPT 链接:,实际是人们对于 GPT 时代 C 端个性消费产品的真正想象。 无独有偶,1 月 11 日 OpenAI 正式上线 GPT Store 后,公布 300 万个 GPTs 之余,也将与用户日常消费活动息息相关的徒步路线指南“AllTrails”放在推荐榜单上。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉