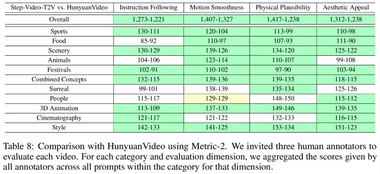
在人工智能领域,尤其是生成式对抗网络(AIGC)方面的不断进展,语音交互已成为一个重要的研究方向。传统的大语言模型(LLM)主要专注于文本处理,无法直接生成自然语音,这在一定程度上影响了人机音频交互的流畅性。
为了突破这一局限,Step-Audio 团队开源了一款全新的端到端语音大模型 ——Step-Audio-AQAA。该模型能够直接从原始音频输入生成自然流畅的语音输出,使得人机交流更加自然。
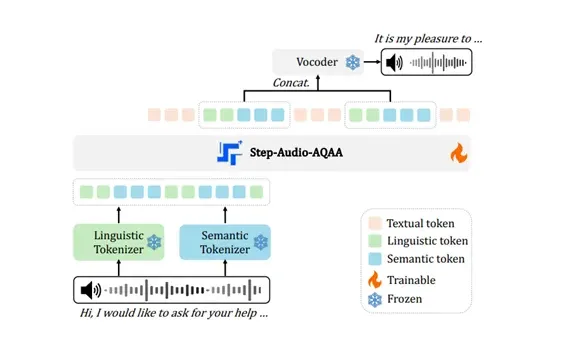
Step-Audio-AQAA 的架构由三个核心模块组成:双码本音频标记器、骨干 LLM 和神经声码器。其中,双码本音频标记器负责将输入的音频信号转化为结构化的标记序列。这个模块分为语言标记器和语义标记器,前者提取语言的结构化特征,后者则捕捉语音的情感和语调等副语言信息。通过这种双码本设计,Step-Audio-AQAA 能够更好地理解语音中的复杂信息。
接下来,这些标记序列会被送入骨干 LLM,即 Step-Omni。这是一款预训练的1300亿参数的多模态模型,具备处理文本、语音和图像的能力。该模型采用了解码器架构,可以高效地处理来自双码本音频标记器的标记序列,通过深度的语义理解和特征提取,为后续生成自然语音做好准备。
最后,生成的音频标记序列会被送入神经声码器。该模块的作用是将离散的音频标记合成为高质量的语音波形,采用了 U-Net 架构,以确保在音频处理中的高效性和准确性。通过这种创新的架构设计,Step-Audio-AQAA 能够在听懂音频问题后,迅速合成自然、流畅的语音回答,为用户提供了更好的交互体验。
这项技术的发展代表着人机音频交互的一个重要进步,开源的 Step-Audio-AQAA 不仅为研究者提供了一个强大的工具,也为未来的智能语音应用打下了坚实的基础。
开源地址:https://huggingface.co/stepfun-ai/Step-Audio-AQAA
划重点:
🔊 Step-Audio 团队开源的 Step-Audio-AQAA 可以直接从音频输入生成自然语音,提升人机交互体验。
📊 模型架构由双码本音频标记器、骨干 LLM 和神经声码器三个模块组成,能够高效捕捉语音中的复杂信息。
🎤 Step-Audio-AQAA 的推出标志着语音交互技术的重要进展,为未来智能语音应用提供了新思路。