向量数据库

RAG、向量数据库和LLM搜索:人工智能驱动商业智能的未来
译者 | 李睿审校 | 重楼本文对RAG、向量数据库和LLM搜索如何塑造人工智能驱动的商业智能未来进行探讨。 RAG通过集成知识检索提升LLM性能,解决其无法及时纳入最新或专有信息的问题,尤其在客户服务领域影响显著。 向量数据库则支持快速相似性搜索,理解查询语义。

深度剖析向量数据库HNSW索引,参数优化与性能权衡
随着深度学习在特征表示领域的突破,向量嵌入已成为处理和检索非结构化数据(如文本、图像、音频)的核心技术。 向量数据库,作为专门存储、管理和查询大规模向量数据的系统,其性能高度依赖于高效的近似最近邻(Approximate Nearest Neighbor, ANN)搜索算法。 HNSW (Hierarchical Navigable Small World) 作为当前业界领先的图 ANN 索引算法之一,因其出色的搜索速度和召回率平衡而备受青睐。

当AI邂逅向量数据库:重新定义智能时代的数据检索
译者 | 晶颜审校 | 重楼探究人工智能与向量数据库如何实现语义搜索,为更智能的推荐系统、聊天机器人及非结构化数据处理工具提供支撑。 在互联网时代,你是否期待搜索引擎不再局限于关键词匹配,而是能理解用户真实意图? 这正是人工智能与向量数据库结合的价值所在。

一文揭秘专为 RAG 打造的高性能开源图向量数据库:HelixDB
在人工智能技术尤其是大语言模型(LLM)蓬勃发展的浪潮中,检索增强生成(Retrieval-Augmented Generation,简称 RAG)正迅速成为提升生成式 AI 系统内容准确性、实时性与上下文相关性的核心手段。 RAG 通过将外部知识检索与语言模型推理相结合,显著缓解了模型“幻觉”问题,使其在问答系统、智能助手、企业知识中台等应用中展现出广阔前景。 然而,随着业务需求的不断升级,传统 RAG 系统所依赖的扁平向量表示与单一类型数据库架构,已难以满足对复杂语义结构建模与海量非结构化数据高效检索的双重需求。

向量存储瘦身术:智能问答系统的空间优化革命
在AI智能问答系统中,向量数据库的存储压力越来越大。 随着知识库规模扩大,如何高效压缩存储空间正在被大家所关注。 本文将介绍一种方案,实现节省知识库占用空间,避免数据量无限制的增长。

RAG实战|向量数据库LanceDB指南
LanceDB介绍LanceDB是一个开源的用 Rust 实现的向量数据库(),它的主要特点是:提供单机服务,可以直接嵌入到应用程序中支持多种向量索引算法,包括Flat、HNSW、IVF等。 支持全文检索,包括BM25、TF-IDF等。 支持多种向量相似度算法,包括Cosine、L2等。

为什么AI需要向量数据库?
大模型火遍全球,DeepSeek、OpenAI、谷歌、百度、抖音等科技巨头争相发布自家产品。 多数人会想当然认为,大模型越大越强大,参数量越多就越聪明。 现实呢?

SpringAI用嵌入模型操作向量数据库!
嵌入模型(Embedding Model)和向量数据库(Vector Database/Vector Store)是一对亲密无间的合作伙伴,也是 AI 技术栈中紧密关联的两大核心组件,两者的协同作用构成了现代语义搜索、推荐系统和 RAG(Retrieval Augmented Generation,检索增强生成)等应用的技术基础。 “PS:准确来说 Vector Database 和 Vector Store 不完全相同,前者主要用于“向量”数据的存储,而 Vector Store 是用于存储和检索向量数据的组件。 在 Spring AI 中,嵌入模型 API 和 Spring AI Model API 和嵌入模型的关系如下:系统整体交互流程如下:接下来我们使用以下技术:Spring AI阿里云文本嵌入模型 text-embedding-v3SimpleVectorStore(内存级别存储和检索向量数据组件)实现嵌入模型操作内存级别向量数据库的案例。

基于LangChain和云原生向量数据库Milvus开发混合搜索AI程序
译者 | 朱先忠审校 | 重楼本文将探讨基于LangChain框架和云原生向量数据库Milvus并将密集嵌入与稀疏嵌入结合起来开发混合搜索型AI程序的实战过程。 简介最近,我们——来自IBM研究中心的团队——需要在Milvus向量存储中使用混合搜索技术。 因为我们已经在使用LangChain框架,所以我们决定一鼓作气贡献出在langchain-milvus中启用这一功能所需的一切。

向量数据库的中场战事:长期主义者Zilliz如何全球突围
命运齿轮转动的开始,源于 2023 年的 3 月 23 日的 OpenAI 一次日常更新。 这一天,OpenAI ChatGPT 发布了一个名叫 chatgpt-retrieval-plugin 的插件功能。 而在官方 plugin 给出的标准案例中,OpenAI 专门提到,向量数据库是大模型产品形成长期记忆一个必不可少的组件。
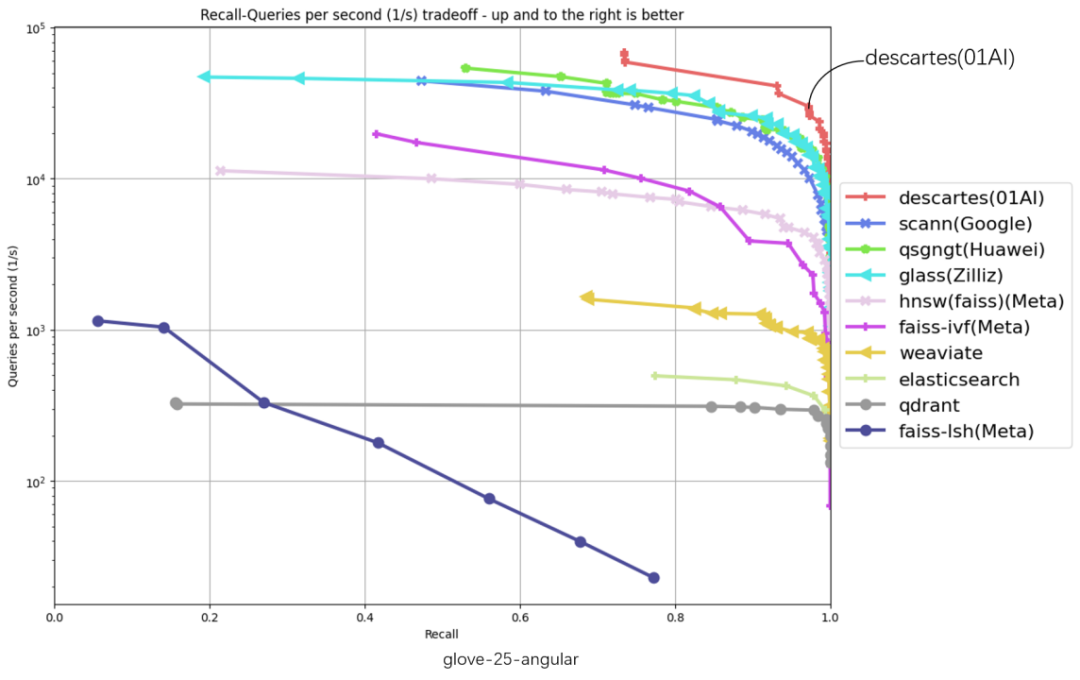
零一万物自研全导航图向量数据库,横扫权威榜单6项第一
3 月 11 日,零一万物宣布推出基于全导航图的新型向量数据库 「笛卡尔(Descartes)」,其搜索内核已包揽权威榜单 ANN-Benchmarks 6 项数据集评测第一名。向量数据库,又被称为 AI 时代的信息检索技术,是检索增强生成(Retrieval-Augmented Generation, RAG)内核技术之一。对大模型应用开发者来说,向量数据库是非常重要的基础设施,在一定程度上影响着大模型的性能表现。在国际权威评测平台 ANN-Benchmarks 离线测试中,零一万物笛卡尔(Descartes)向
OpenAI开发者大会后的向量数据库和RAG,一起来这场论坛聊聊
十几天前的 OpenAI 开发者大会,给整个行业带来了一场地震。最新推出的 Assistants API 提供了代码解释器、检索以及函数调用等新功能,帮助开发者构建高质量的 AI 应用。于是,“OpenAI 力挺 RAG,向量数据库失宠了?”等话题一度成为了讨论的热点。很多从业者纷纷表示尽管 RAG 看似很完美,但是目前来看,向量数据库依然是不可忽视的一环,而它本身也是 RAG 的基本组件。尽管向量数据库和 RAG 的技术门槛并不算高,但是在实际应用中还是会出现各种各样的问题。如何发挥外挂知识库和向量数据库的最大价
低成本快速定制大模型,这次我们来深度探讨下RAG 和向量数据库
当今人工智能领域,最受关注的毋庸置疑是大模型。然而,高昂的训练成本、漫长的训练时间等都成为了制约大多数企业入局大模型的关键瓶颈。这种背景下,向量数据库凭借其独特的优势,成为解决低成本快速定制大模型问题的关键所在。向量数据库是一种专门用于存储和处理高维向量数据的技术。它采用高效的索引和查询算法,实现了海量数据的快速检索和分析。如此优秀的性能之外,向量数据库还可以为特定领域和任务提供定制化的解决方案。科技巨头诸如腾讯、阿里等公司纷纷布局向量数据库研发,力求在大模型领域实现突破。大量中小型公司也借助向量数据库的能力快速进

低成本快速入局大模型,你需要学下向量数据库
在 ChatGPT 等大语言模型(LLM)盛行的当下,一直不温不火的向量数据库(Vector Data Base ,VectorDB)开始受到大家的关注。一般而言,大模型在回答具有普遍性的问题上游刃有余,但在回答垂直专业的问题上,就显得不那么出色,例如,大模型在医疗行业会存在回答不准确的情况。这时,为大模型配备一个「超级大脑」变得尤为重要,这个「超级大脑」可以存储一些专有知识,这样一来,大模型就能从海量的数据中快速检索出最合适的答案,提高它们的准确性和效率,而向量数据库就充当了「超级大脑」角色。其实,早在 2013
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉